Yes, you read that correctly, Microsoft Hyper-V is alive and enhanced with Windows Server 2025, formerly Windows Server v.Next server. Note that Windows Server 2025 preview build is just a preview available for download testing as of this time.
What about Myth Hyper-V is discontinued?
Despite recent FUD (fear, uncertainty, doubt), misinformation, and fake news, Microsoft Hyper-V is not dead. Nor has Hyper-V been discontinued, as some claim. Some Hyper-V FUD is tied to customers and partners of VMware following Broadcom’s acquisition of VMware looking for alternatives. More on Broadcom and VMware here, here, here, here, and here.
As a result of Broadcom’s VMware acquisition and challenges for partners and customers (see links above), organizations are doing due diligence, looking for replacement or alternatives. In addition, some vendors are leveraging the current VMware challenges to try and position themselves as the best hypervisor virtualization safe harbor for customers. Thus some vendors, their partners, influencers and amplifiers are using FUD to keep prospects from looking at or considering Hyper-V.
Virtual FUD (vFUD)
First, let’s shut down some Virtual FUD (vFUD). As mentioned above, some are claiming that Microsoft has discontinued Hyper-V. Specifically, the vFUD centers on Microsoft terminating a specific license SKU (e.g., the free Hyper-V Server 2019 SKU). For those unfamiliar with the discontinued SKU (Hyper-V Server 2019), it’s a headless (no desktop GUI) version of Windows Server running Hyper-V VMs, nothing more, nothing less.
Does that mean the Hyper-V technology is discontinued? No.
Does that mean Windows Server and Hyper-V are discontinued? No.
Microsoft is terminating a particular stripped-down Windows Server version SKU (e.g. Hyper-V Server 2019) and not the underlying technology, including Windows Server and Hyper-V.
To repeat, a specific SKU or distribution (Hyper-V Server 2019) has been discontinued not Hyper-V. Meanwhile, other distributions of Windows Server with Hyper-V continue to be supported and enhanced, including the upcoming Windows Server 2025 and Server 2022, among others.
On the other hand, there is also some old vFUD going back many years, or a decade, when some last experienced using, trying, or looking at Hyper-V. For example, the last look at Hyper-V might been in the Server 2016 or before era.
If you are a vendor or influencer throwing vFUD around, at least get some new vFUD and use it in new ways. Better yet, up your game and marketing so you don’t rely on old vFUD. Likewise, if you are a vendor partner and have not extended your software or service support for Hyper-V, now is a good time to do so.
Watch out for falling into the vFUD trap thinking Hyper-V is dead and thus miss out on new revenue streams. At a minimum, take a look at current and upcoming enhancements for Hyper-V doing your due diligence instead of working off of old vFUD.
Where is Hyper-V being used?
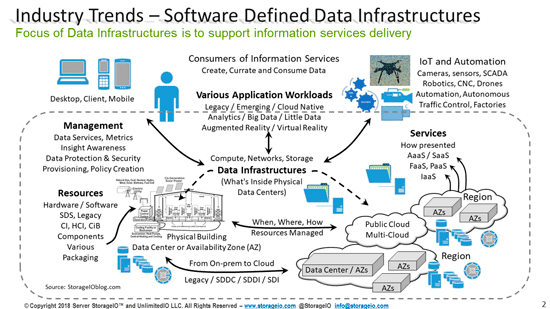
From on-site (aka on-premises, on-premises, on-prem) and edge on Windows Servers standalone and clustered, to Azure Stack HCI. From Azure, and other Microsoft platforms or services to Windows Desktops, as well as home labs, among many other scenarios.
Do I use Hyper-V? Yes, when I retired from the vExpert program after ten years. I moved all of my workloads from VMware environment to Hyper-V including *nix, containers and Windows VMs, on-site and on Azure Cloud.
How Hyper-V Is Alive Enhanced With Windows Server 2025
Is Hyper-V Alive Enhanced With Windows Server 2025? Yup.
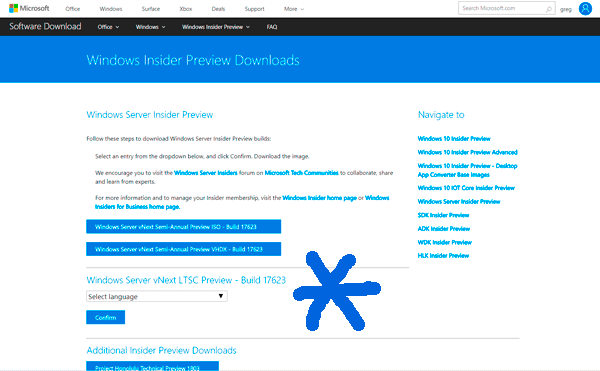
Formerly known as Windows Server v.Next, Microsoft announced the Windows Server 2025 preview build on January 26, 2024 (you can get the bits here). Note that Microsoft uses Windows Server v.Next as a generic placeholder for next-generation Windows Server technology.
A reminder that the cadence of Windows Server Long Term Serving Channels (LTSC) versions has been about three years (2012R2, 2016, 2019, 2022, now 2025), along with interim updates.
What’s enhanced with Hyper-V and Windows Server 2025
- Hot patching of running server (requires Azure Arc management) with almost instant implementations and no reboot for physical, virtual, and cloud-based Windows Servers.
- Scaling of even more compute processors and RAM for VMs.
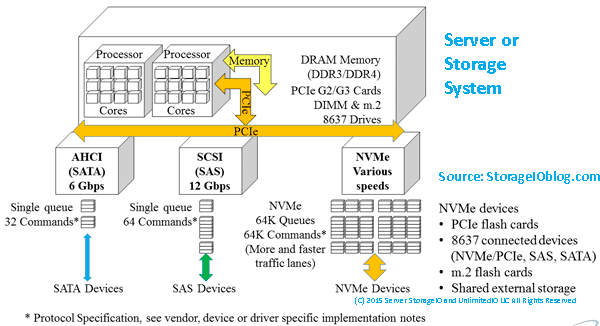
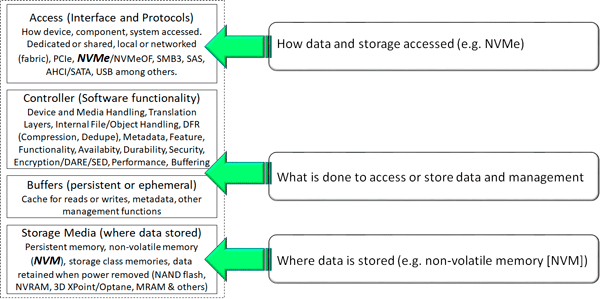
- Server Storage I/O performance updates, including NVMe optimizations.
- Active Directory (AD) improvements for scaling, security, and performance.
- There are enhancements to storage replica and clustering capabilities.
- Hyper-V GPU partition and pools, including migration of VMs using GPUs.
More Enhancements for Hyper-V and Windows Server 2025
Active Directory (AD)
Enhanced performance using all CPUs in a process group up to 64 cores to support scaling and faster processing. LDAP for TLS 1.3, Kerberos support for AES SHA 256 / 384, new AD functional levels, local KDC, improved replication priority, NTLM retirement, local Kerberos, and other security hardening. In addition, 64-bit Long value IDs (LIDs) are supported along with a new database schema using 32K pages vs the previous 8K pages. You will need to upgrade forest-wide across domain controllers to leverage the new larger page sizes (at least Server 2016 or later). Note that there is also backward compatibility using 8K pages until all ADs are upgraded.
Storage, HA, and Clustering
Windows Server continues to offer flexible options for storage how you want or need to use it, from traditional direct attached storage (DAS) to Storage Area Networks (SAN), to Storage Spaces Direct (S2D) software-defined, including NVMe, NVMe over Fabrics (NVMeoF), SAS, Fibre Channel, iSCSI along with file attached storage. Some other storage and HA enhancements include Storage Replica performance for logging and compression and stretch S2D multi-site optimization.
Failover Cluster enhancements include AD-less clusters, cert-based VM live migration for the edge, cluster-aware updating reliability, and performance improvements. ReFS enhancements include dedupe and compression optimizations.
Other NVMe enhancements include optimization to boost performance while reducing CPU overhead, for example, going from 1.1M IOPS to 1.86M IOPS, and then with a new native NVMe driver (to be added), from 1.1M IOPs to 2.1M IOPs. These performance optimizations will be interesting to look at closer, including baseline configuration, number and type of devices used, and other considerations.
Compute, Hyper-V, and Containers
Microsoft has added and enhanced various Compute, Hyper-V, and Container functionality with Server 2025, including supporting larger configurations and more flexibility with GPUs. There are app compatibility improvements for containers that will be interesting to see and hear more details about besides just Nano (the ultra slimmed-down Windows container).
Hyper-V
Microsoft extensively uses Hyper-V technology across different platforms, including Azure, Windows Servers, and Desktops. In addition, Hyper-V is commonly found across various customer and partner deployments on Windows Servers, Desktops, Azure Stack HCI, running on other clouds, and virtualization (nested). While Microsoft effectively leverages Hyper-V and continues to enhance it, its marketing has not effectively told and amplified the business benefit and value, including where and how Hyper-V is deployed.
Hyper-V with Server 2025 includes discrete device assignment to VM (e.g., resources dedicated to VMs). However, dedicating a device like a GPU to a VM prevents resource sharing, failover cluster, or live migration. On the other hand, Server 2025 Hyper-V supports GPU-P (GPU Partitioning), enabling GPU(s) to be shared across multiple VMs. GPUs can be partitioned and assigned to VMs, with GPUs and GPU partitioning enabled across various hosts.
In addition to partitioning, GPUs can be placed into GPU pools for HA. Live migration and cluster failover (requires PCIe SR-IOV), AMD Lilan or later, Intel Sapphire Rapids, among other requirements, can be done. Another enhancement is Dynamic Processor Compatibility, which allows mixed processor generations to be used across VMs and then masks out functionalities that are not common across processors. Other enhancements include optimized UEFI, secure boot, TPM , and hot add and removal of NICs.
Networking
Network ATC provides intent-based deployments where you specify desired outcomes or states, and the configuration is optimized for what you want to do. Network HUD enables always-on monitoring and network remediation. Software Defined Network (SDN) optimization for transparent multi-site L2 and L3 connectivity and improved SDN gateway performance enhancements.
SMB over QUIC leverages TLS 1.3 security to streamline local, mobile, and remote networking while enhancing security with configuration from the server or client. In addition, there is an option to turn off SMB NTLM at the SMB level, along with controls on which versions of SMB to allow or refuse. Also being added is a brute force attack limiter that slows down SMB authentication attacks.
Management, Upgrades, General user Experience
The upgrade process moving forward with Windows Server 2025 is intended to be seamless and less disruptive. These enhancements include hot patching and flighting (e.g., LTSC Windows server upgrades similar to how you get regular updates). For hybrid management, an easier-to-use wizard to enable Azure Arc is planned. For flexibility, if present, WiFi networking and Bluetooth devices are automatically enabled with Windows Server 2025 focused on edge and remote deployment scenarios.
Also new is an optional subscription-based licensing model for Windows Server 2025 while retaining the existing perpetual use. Let me repeat that so as not to create new vFUD, you can still license Windows Server (and thus Hyper-V) using traditional perpetual models and SKUs.
Additional Resources Where to learn more
The following links are additional resources to learn about Windows Server, Server 2025, Hyper-V, and related data infrastructures and tradecraft topics.
What’s New in Windows Server v.Next video from Microsoft Ignite (11/17/23)
Microsoft Windows Server 2025 Whats New
Microsoft Windows Server 2025 Preview Build Download
Microsoft Windows Server 2025 Preview Build Download (site)
Microsoft Evaluation Center (various downloads for trial)
Microsoft Eval Center Windows Server 2022 download
Microsoft Hyper-V on Windows Information
Microsoft Hyper-V on Windows Server Information
Microsoft Hyper-V on Windows Desktop (e.g., Win10)
Microsoft Windows Server Release Information
Microsoft Hyper-V Server 2019
Microsoft Azure Virtual Machines Trial
Microsoft Azure Elastic SAN
If NVMe is the answer, what are the questions?
NVMe Primer (or refresh), The NVMe Place.
Additional learning experiences along with common questions (and answers), are found in my Software Defined Data Infrastructure Essentials book.

What this all means
Hyper-V is very much alive, and being enhanced. Hyper-V is being used from Microsoft Azure to Windows Server and other platforms at scale, and in smaller environments.
If you are looking for alternatives to VMware or simply exploring virtualization options, do your due diligence and check out Hyper-V. Hyper-V may or may not be what you want; however, is it what you need? Looking at Hyper-V now and upcoming enhancements also positions you when asked by management if you have done your due diligence vs relying on vFUD.
Do a quick Proof of Concept, spin up a lab, and check out currently available Hyper-V. For example, on Server 2022 or 2025 preview, to get a feel for what is there to meet your needs and wants. Download the bits and get some hands on time with Hyper-V and Windows Server 2025.
Wrap up
Hyper-V is alive and enhanced with Windows Server 2025 and other releases.
Ok, nuff said, for now.
Cheers Gs
Greg Schulz – Nine time Microsoft MVP Cloud and Data Center Management, VMware vExpert 2010-2018. Author of Software Defined Data Infrastructure Essentials (CRC Press), as well as Cloud and Virtual Data Storage Networking (CRC Press), The Green and Virtual Data Center (CRC Press), Resilient Storage Networks (Elsevier) and twitter @storageio. Courteous comments are welcome for consideration. First published on https://storageioblog.com any reproduction in whole, in part, with changes to content, without source attribution under title or without permission is forbidden.
All Comments, (C) and (TM) belong to their owners/posters, Other content (C) Copyright 2006-2026 Server StorageIO and UnlimitedIO. All Rights Reserved. StorageIO is a registered Trade Mark (TM) of UnlimitedIO LLC.