
Enabling Recovery Points (Backup, Snapshots, Versions)
Updated 1/7/18
Companion to Software Defined Data Infrastructure Essentials – Cloud, Converged, Virtual Fundamental Server Storage I/O Tradecraft ( CRC Press 2017)

By Greg Schulz – www.storageioblog.com November 26, 2017
This is Part 4 of a multi-part series on Data Protection fundamental tools topics techniques terms technologies trends tradecraft tips as a follow-up to my Data Protection Diaries series, as well as a companion to my new book Software Defined Data Infrastructure Essentials – Cloud, Converged, Virtual Server Storage I/O Fundamental tradecraft (CRC Press 2017).

Click here to view the previous post Part 3 Data Protection Access Availability RAID Erasure Codes (EC) including LRC, and click here to view the next post Part 5 Point In Time Data Protection Granularity Points of Interest.
Post in the series includes excerpts from Software Defined Data Infrastructure (SDDI) pertaining to data protection for legacy along with software defined data centers ( SDDC), data infrastructures in general along with related topics. In addition to excerpts, the posts also contain links to articles, tips, posts, videos, webinars, events and other companion material. Note that figure numbers in this series are those from the SDDI book and not in the order that they appear in the posts.
In this post the focus is around Data Protection Recovery Points (Archive, Backup, Snapshots, Versions) from Chapter 10 .
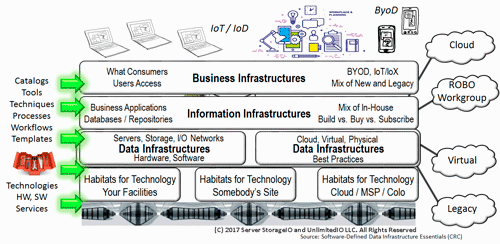
Figure 1.5 Data Infrastructures and other IT Infrastructure Layers
Enabling RPO (Archive, Backup, CDP, PIT Copy, Snapshots, Versions)

Figure 9.5 Data Protection and Availability Points of Interest
RAID, including parity and erasure code (EC) along with mirroring and replication, provide availability and accessibility. These by themselves, however, are not a replacement for backup (or other point in time data protection) to support recovery points. For complete data protection the solution is to combine resiliency technology with point-in-time tools enabling availability and facilitate going back to a previous consistency time.
Recovery point protection is implemented within applications using checkpoint and consistency points as well as log and journal switches or flush. Other places where recovery-point protection occurs include in middleware, database, key-value stores and repositories, file systems, volume managers, and software-defined storage, in addition to hypervisors, operating systems, containers, utilities, storage systems, appliances, and service providers.
In addition to where, there are also different approaches, technologies, techniques, and tools, including archive, backup, continuous data protection, point-in-time copies, or clones such as snapshots, along with versioning.
Common recovery point Data Protection related terms, technologies, techniques, trends and topics pertaining to data protection from availability and access to durability and consistency to point in time protection and security are shown below.
Time interval protection for example with Snapshot, backup/restore, point in time copies, checkpoints, consistency point among other approaches can be scheduled or dynamic. They can also vary by how they copy data for example full copy or clone, or incremental and differential (e.g. what has changed) among other techniques to support 4 3 2 1 data protection. Other variations include how many concurrent copies, snapshots or versions can take place, along with how many stored and for how long (retention).
Additional Data Protection Terms
Copy Data Management ( CDM) as its name implies is associated managing various data copies for data protection, analytics among other activities. This includes being able to identify what copies exist (along with versions), where they are located among other insight.
Data Protection Management ( DPM) as its name implies is the management of data protection from backup/restore, to snapshots and other recovery point in time protection, to replication. This includes configuration, monitoring, reporting, analytics, insight into what is protected, how well it is protected, versions, retention, expiration, disposition, access control among other items.
Number of 9s Availability – Availability (access or durability or access and availability) can be expressed in number of nines. For example, 99.99 (four nines), indicates the level of availability (downtime does not exceed) objective. For example, 99.99% availability means that in a 24-hour day there could be about 9 seconds of downtime, or about 52 minutes and 34 seconds per year. Note that numbers can vary depending on whether you are using 30 days for a month vs. 365/12 days, or 52 weeks vs. 365/7 for weeks, along with rounding and number decimal places as shown in Table 9.1.
| Uptime | 24-hour Day | Week | Month | Year |
99 | 0 h 14 m 24 s | 1 h 40 m 48 s | 7 h 18 m 17 s | 3 d 15 h 36 m 15 s |
99.9 | 0 h 01 m 27 s | 0 h 10 m 05 s | 0 h 43 m 26 s | 0 d 08 h 45 m 36 s |
99.99 | 0 h 00 m 09 s | 0 h 01 m 01 s | 0 h 04 m 12 s | 0 d 00 h 52 m 34 s |
99.999 | 0 h 00 m 01s | 0 h 00 m 07 s | 0 h 00 m 36 s | 0 d 00 h 05 m 15 s |
Table 9.1 Number of 9’s Availability Shown as Downtime per Time Interval
Service Level Objectives SLOs are metrics and key performance indicators (KPI) that guide meeting performance, availability, capacity, and economic targets. For example, some number of 9’s availability or durability, a specific number of transactions per second, or recovery and restart of applications. Service-level agreement (SLA) – SLA specifies various service level objectives such as PACE requirements including RTO and RPO, among others that define the expected level of service and any remediation for loss of service. SLA can also specify availability objectives as well as penalties or remuneration should SLO be missed.
Recovery Time Objective RTO is how much time is allowed before applications, data, or data infrastructure components need to be accessible, consistent, and usable. An RTO = 0 (zero) means no loss of access or service disruption, i.e., continuous availability. One example is an application end-to-end RTO of 4 hours, meaning that all components (application server, databases, file systems, settings, associated storage, networks) must be restored, rolled back, and restarted for use in 4 hours or less.
Another RTO example is component level for different data infrastructure layers as well as cumulative or end to end. In this scenario, the 4 hours includes time to recover, restart, and rebuild a server, application software, storage devices, databases, networks, and other items. In this scenario, there are not 4 hours available to restore the database, or 4 hours to restore the storage, as some time is needed for all pieces to be verified along with their dependencies.
Data Loss Access DLA occurs when data still exists, is consistent, durable, and safe, but it cannot be accessed due to network, application, or other problem. Note that the inverse is data that can be accessed, but it is damaged. Data Loss Event DLE is an incident that results in loss or damage to data. Note that some context is needed in a scenario in which data is stolen via a copy but the data still exists, vs. the actual data is taken and is now missing (no copies exist). Also note that there can be different granularity as well as scope of DLE for example all data or just some data lost (or damaged). Data Loss Prevention DLP encompasses the activities, techniques, technologies, tools, best practices, and tradecraft skills used to protect data from DLE or DLA.
Point in Time (PiT) such as PiT copy or data protection refers to a recovery or consistency point where data can be restored from or to (i.e., RPO), such as from a copy, snapshot, backup, sync, or clone. Essentially, as its name implies, it is the state of the data at that particular point in time.
Recovery Point Objective RPO is the point in time to which data needs to be recoverable (i.e., when it was last protected). Another way of looking at RPO is how much data you can afford to lose, with RPO = 0 (zero) meaning no data loss, or, for example, RPO = 5 minutes being up to 5 minutes of lost data.
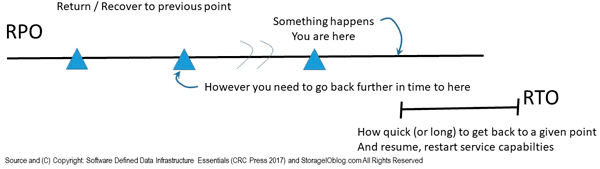
Figure 9.8 Recovery Points (point in time to recover from), and Recovery Time (how long recovery takes)
Frequency refers to how often and on what time interval protection is performed.

Figure 9.4 Data Protection 4 3 2 1 and 3 2 1 rule
In the context of the 4 3 2 1 rule, enabling RPO is associated with durability, meaning number of copies and versions. Simply having more copies is not sufficient because if they are all corrupted, damaged, infected, or contain deleted data, or data with latent nefarious bugs or root kits, then they could all be bad. The solution is to have multiple versions and copies of the versions in different locations to provided data protection to a given point in time.
Timeline and delta or recovery points are when data can be recovered from to move forward. They are consistent points in the context of what is/was protected. Figure 10.1 shows on the left vertical axis different granularity, along with protection and consistency points that occur over time (horizontal axis). For example, data “Hello” is written to storage (A) and then (B), an update is made “Oh Hello,” followed by (C) full backup, clone, and master snapshot or a gold copy is made.

Figure 10.1 Recovery and consistency points
Next, data is changed (D) to “Oh, Hello,” followed by, at time-1 (E), an incremental backup, copy, snapshot. At (F) a full copy, the master snapshot, is made, which now includes (H) “Hello” and “Oh, Hello.” Note that the previous full contained “Hello” and “Oh Hello,” while the new full (H) contains “Hello” and “Oh, Hello.” Next (G) data is changed to “Oh, Hello there,” then changed (I) to “Oh, Hello there I’m here.” Next (J) another incremental snapshot or copy is made, date is changed (K) to “Oh, Hello there I’m over here,” followed by another incremental (L), and other incremental (M) made a short time later.
At (N) there is a problem with the file, object, or stored item requiring a restore, rollback, or recovery from a previous point in time. Since the incremental (M) was too close to the recovery point (RP) or consistency point (CP), and perhaps damaged or its consistency questionable, it is decided to go to (O), the previous snapshot, copy, or backup. Alternatively, if needed, one can go back to (P) or (Q).
Note that simply having multiple copies and different versions is not enough for resiliency; some of those copies and versions need to be dispersed or placed in different systems or locations away from the source. How many copies, versions, systems, and locations are needed for your applications will depend on the applicable threat risks along with associated business impact.
The solution is to combine techniques for enabling copies with versions and point-in-time protection intervals. PIT intervals enable recovering or access to data back in time, which is a RPO. That RPO can be an application, transactional, system, or other consistency point, or some other time interval. Some context here is that there are gaps in protection coverage, meaning something was not protected.
A good data protection gap is a time interval enabling RPO, or simply a physical and logical break and the distance between the active or protection copy, and alternate versions and copies. For example, a gap in coverage (e.g. bad data protection gap) means something was not protected.
A protection air or distance gap is having one of those versions and copies on another system, in a different location and not directly accessible. In other words, if you delete, or data gets damaged locally, the protection copies are safe. Furthermore, if the local protection copies are also damaged, an air or distance gap means that the remote or alternate copies, which may be on-line or off-line, are also safe.

Figure 9.9 Air Gaps and Data Protection
Figure 10.2 shows on the left various data infrastructure layers moving from low altitude (lower in the stack) host servers or bare metal (BM) physical machine (PM) and up to higher levels with applications. At each layer or altitude, there are different hardware and software components to protect, with various policy attributes. These attributes, besides PACE, FTT, RTO, RPO, and SLOs, include granularity (full or incremental), consistency points, coverage, frequency (when protected), and retention.

Figure 10.2 Protecting data infrastructure granularity and enabling resiliency at various stack layers (or altitude)
Also shown in the top left of Figure 10.2 are protections for various data infrastructure management tools and resources, including active directory (AD), Azure AD (AAD), domain controllers (DC), group policy objects (GPO) and organizational units (OU), network DNS, routing and firewall, among others. Also included are protecting management systems such as VMware vCenter and related servers, Microsoft System Center, OpenStack, as well as data protection tools along with their associated configurations, metadata, and catalogs.
The center of Figure 10.2 lists various items that get protected along with associated technologies, techniques, and tools. On the right-hand side of Figure 10.2 is an example of how different layers get protected at various times, granularity, and what is protected.
For example, the PM or host server BIOS and UEFI as well as other related settings seldom change, so they do not have to be protected as often. Also shown on the right of Figure 10.2 are what can be a series of full and incremental backups, as well as differential or synthetic ones.
Figure 10.3 is a variation of Figure 10.2 showing on the left different frequencies and intervals, with a granularity of focus or scope of coverage on the right. The middle shows how different layers or applications and data focus have various protection intervals, type of protection (full, incremental, snap, differentials), along with retention, as well as some copies to keep.

Figure 10.3 Protecting different focus areas with various granularities
Protection in Figures 10.2 and 10.3 for the PM could be as simple as documentation of what settings to configure, versions, and other related information. A hypervisors may have changes, such as patches, upgrades, or new drivers, more frequently than a PM. How you go about protecting may involve reinstalling from your standard or custom distribution software, then applying patches, drivers, and settings.
You might also have a master copy of a hypervisors on a USB thumb drive or another storage device that can be cloned, customized with the server name, IP address, log location, and other information. Some backup and data protection tools also provide protection of hypervisors (or containers and cloud machine instances) in addition to the virtual machine (VM), guest operating systems, applications, and data.
The point is that as you go up the stack, higher in altitude (layers), the granularity and frequency of protection increases. What this means is that you may have more frequent smaller protection copies and consistency points higher up at the application layer, while lower down, less frequent, yet larger full image, volume, or VM protection, combining different tools, technology, and techniques.
Where To Learn More
Continue reading additional posts in this series of Data Infrastructure Data Protection fundamentals and companion to Software Defined Data Infrastructure Essentials (CRC Press 2017) book, as well as the following links covering technology, trends, tools, techniques, tradecraft and tips.
- Part 1 – Data Infrastructure Data Protection Fundamentals
- Part 2 – Reliability, Availability, Serviceability ( RAS) Data Protection Fundamentals
- Part 3 – Data Protection Access Availability RAID Erasure Codes ( EC) including LRC
- Part 4 – Data Protection Recovery Points (Archive, Backup, Snapshots, Versions)
- Part 5 – Point In Time Data Protection Granularity Points of Interest
- Part 6 – Data Protection Security Logical Physical Software Defined
- Part 7 – Data Protection Tools, Technologies, Toolbox, Buzzword Bingo Trends
- Part 8 – Data Protection Diaries Walking Data Protection Talk
- Part 9 – who’s Doing What ( Toolbox Technology Tools)
- Part 10 – Data Protection Resources Where to Learn More
- Data Protection Diaries series
- Data Infrastructure server storage I/O network Recommended Reading List Book Shelf
- Software Defined Data Infrastructure Essentials (CRC 2017) Book
Additional learning experiences along with common questions (and answers), as well as tips can be found in Software Defined Data Infrastructure Essentials book.
What This All Means
Everything is not the same across different environments, data centers, data infrastructures, applications and their workloads (along with data, and its value). Likewise there are different approaches for enabling data protection to meet various SLO needs including RTO, RPO, RAS, FTT and PACE attributes among others. What this means is that complete data protection requires using different new (and old) tools, technologies, trends, services (e.g. cloud) in new ways. This also means leveraging existing and new techniques, learning from lessons of the past to prevent making the same errors.
RAID (mirror, replicate, parity including erasure codes) regardless of where and how implemented (hardware, software, legacy, virtual, cloud) by itself is not a replacement for backup, they need to be combined with recovery point protection of some type (backup, checkpoint, consistency point, snapshots). Also protection should occur at multiple levels of granularity (device, system, application, database, table) to meet various SLO requirements as well as different time intervals enabling 4 3 2 1 data protection.
Keep in mind what is it that you are protecting, why are you protecting it and against what, what is likely to happen, also if something happens what will its impact be, what are your SLO requirements, as well as minimize impact to normal operating, as well as during failure scenarios. For example do you need to have a full system backup to support recovery of an individual database table, or can that table be protected and recovered via checkpoints, snapshots or other fine-grained routine protection? Everything is not the same, why treat and protect everything the same way?
Get your copy of Software Defined Data Infrastructure Essentials here at Amazon.com, at CRC Press among other locations and learn more here. Meanwhile, continue reading with the next post in this series, Part 5 Point In Time Data Protection Granularity Points of Interest.
Ok, nuff said, for now.
Gs
Greg Schulz – Microsoft MVP Cloud and Data Center Management, VMware vExpert 2010-2017 (vSAN and vCloud). Author of Software Defined Data Infrastructure Essentials (CRC Press), as well as Cloud and Virtual Data Storage Networking (CRC Press), The Green and Virtual Data Center (CRC Press), Resilient Storage Networks (Elsevier) and twitter @storageio. Courteous comments are welcome for consideration. First published on https://storageioblog.com any reproduction in whole, in part, with changes to content, without source attribution under title or without permission is forbidden.
All Comments, (C) and (TM) belong to their owners/posters, Other content (C) Copyright 2006-2026 Server StorageIO and UnlimitedIO. All Rights Reserved. StorageIO is a registered Trade Mark (TM) of Server StorageIO.