
Application Data Volume Velocity Variety Everything Not The Same
Application Data Volume Velocity Variety Everything Not The Same
This is part four of a five-part mini-series looking at Application Data Value Characteristics everything is not the same as a companion excerpt from chapter 2 of my new book Software Defined Data Infrastructure Essentials – Cloud, Converged and Virtual Fundamental Server Storage I/O Tradecraft (CRC Press 2017). available at Amazon.com and other global venues. In this post, we continue looking at application and data characteristics with a focus on data volume velocity and variety, after all, everything is not the same, not to mention many different aspects of big data as well as little data.

Volume of Data
More data is growing at a faster rate every day, and that data is being retained for longer periods. Some data being retained has known value, while a growing amount of data has an unknown value. Data is generated or created from many sources, including mobile devices, social networks, web-connected systems or machines, and sensors including IoT and IoD. Besides where data is created from, there are also many consumers of data (applications) that range from legacy to mobile, cloud, IoT among others.
Unknown-value data may eventually have value in the future when somebody realizes that he can do something with it, or a technology tool or application becomes available to transform the data with unknown value into valuable information.
Some data gets retained in its native or raw form, while other data get processed by application program algorithms into summary data, or is curated and aggregated with other data to be transformed into new useful data. The figure below shows, from left to right and front to back, more data being created, and that data also getting larger over time. For example, on the left are two data items, objects, files, or blocks representing some information.
In the center of the following figure are more columns and rows of data, with each of those data items also becoming larger. Moving farther to the right, there are yet more data items stacked up higher, as well as across and farther back, with those items also being larger. The following figure can represent blocks of storage, files in a file system, rows, and columns in a database or key-value repository, or objects in a cloud or object storage system.
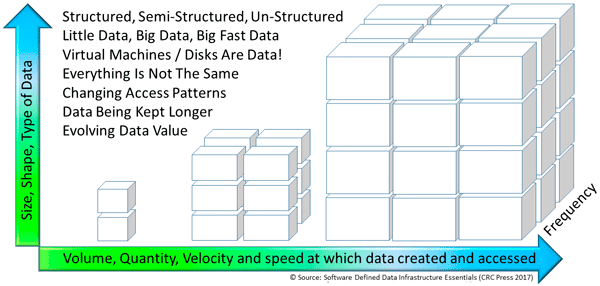
Increasing data velocity and volume, more data and data getting larger
In addition to more data being created, some of that data is relatively small in terms of the records or data structure entities being stored. However, there can be a large quantity of those smaller data items. In addition to the amount of data, as well as the size of the data, protection or overhead copies of data are also kept.
Another dimension is that data is also getting larger where the data structures describing a piece of data for an application have increased in size. For example, a still photograph was taken with a digital camera, cell phone, or another mobile handheld device, drone, or other IoT device, increases in size with each new generation of cameras as there are more megapixels.
Variety of Data
In addition to having value and volume, there are also different varieties of data, including ephemeral (temporary), persistent, primary, metadata, structured, semi-structured, unstructured, little, and big data. Keep in mind that programs, applications, tools, and utilities get stored as data, while they also use, create, access, and manage data.
There is also primary data and metadata, or data about data, as well as system data that is also sometimes referred to as metadata. Here is where context comes into play as part of tradecraft, as there can be metadata describing data being used by programs, as well as metadata about systems, applications, file systems, databases, and storage systems, among other things, including little and big data.
Context also matters regarding big data, as there are applications such as statistical analysis software and Hadoop, among others, for processing (analyzing) large amounts of data. The data being processed may not be big regarding the records or data entity items, but there may be a large volume. In addition to big data analytics, data, and applications, there is also data that is very big (as well as large volumes or collections of data sets).
For example, video and audio, among others, may also be referred to as big fast data, or large data. A challenge with larger data items is the complexity of moving over the distance promptly, as well as processing requiring new approaches, algorithms, data structures, and storage management techniques.
Likewise, the challenges with large volumes of smaller data are similar in that data needs to be moved, protected, preserved, and served cost-effectively for long periods of time. Both large and small data are stored (in memory or storage) in various types of data repositories.
In general, data in repositories is accessed locally, remotely, or via a cloud using:
- Object and blobs stream, queue, and Application Programming Interface (API)
- File-based using local or networked file systems
- Block-based access of disk partitions, LUNs (logical unit numbers), or volumes
The following figure shows varieties of application data value including (left) photos or images, audio, videos, and various log, event, and telemetry data, as well as (right) sparse and dense data.
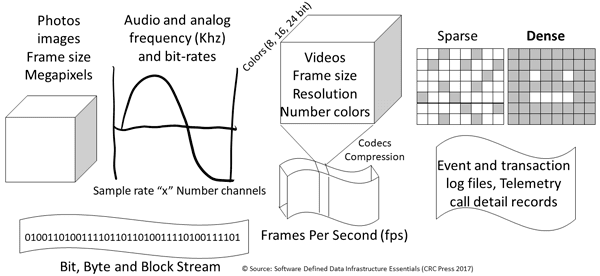
Varieties of data (bits, bytes, blocks, blobs, and bitstreams)
Velocity of Data
Data, in addition to having value (known, unknown, or none), volume (size and quantity), and variety (structured, unstructured, semi structured, primary, metadata, small, big), also has velocity. Velocity refers to how fast (or slowly) data is accessed, including being stored, retrieved, updated, scanned, or if it is active (updated, or fixed static) or dormant and inactive. In addition to data access and life cycle, velocity also refers to how data is used, such as random or sequential or some combination. Think of data velocity as how data, or streams of data, flow in various ways.
Velocity also describes how data is used and accessed, including:
- Active (hot), static (warm and WORM), or dormant (cold)
- Random or sequential, read or write-accessed
- Real-time (online, synchronous) or time-delayed
Why this matters is that by understanding and knowing how applications use data, or how data is accessed via applications, you can make informed decisions. Also, having insight enables how to design, configure, and manage servers, storage, and I/O resources (hardware, software, services) to meet various needs. Understanding Application Data Value including the velocity of the data both for when it is created as well as when used is important for aligning the applicable performance techniques and technologies.
Where to learn more
Learn more about Application Data Value, application characteristics, performance, availability, capacity, economic (PACE) along with data protection, software-defined data center (SDDC), software-defined data infrastructures (SDDI) and related topics via the following links:
- Part 1 – Application Data Value Characteristics Everything Is Not The Same
- Part 2 – 4 3 2 1 Data Protection Application Data Availability
- Part 3 – Application Data Characteristics Types Everything Is Not The Same
- Part 4 – Application Data Volume Velocity Variety Everything Is Not The Same
- Part 5 – Application Data Access life cycle Patterns Everything Not The Same
- Software Defined, Cloud, Object and Blob Storage
- Data Infrastructure server storage I/O network Recommended Reading
- World Backup Day 2018 Data Protection Readiness Reminder
- Data Infrastructure Server Storage I/O related Tradecraft Overview
- Data Infrastructure Overview, Its What’s Inside of Data Centers
- 4 3 2 1 and 3 2 1 data protection best practices
- Garbage data in, garbage information out, big data or big garbage?
- GDPR (General Data Protection Regulation) Resources Are You Ready?
- Which Enterprise HDD to use for a Content Server Platform
- The SSD Place (SSD, NVM, PM, SCM, Flash, NVMe, 3D XPoint, MRAM and related topics)
- The NVMe Place (NVMe related topics, trends, tools, technologies, tip resources)
- Data Protection Diaries (Archive, Backup/Restore, BC, BR, DR, HA,Replication, Security)

Additional learning experiences along with common questions (and answers), as well as tips can be found in Software Defined Data Infrastructure Essentials book.
What this all means and wrap-up
Data has different value, size, as well as velocity as part of its characteristic including how used by various applications. Keep in mind that with Application Data Value Characteristics Everything Is Not The Same across various organizations, data centers, data infrastructures spanning legacy, cloud and other software defined data center (SDDC) environments. Continue reading the next post (Part V Application Data Access life cycle Patterns Everything Is Not The Same) in this series here.
Ok, nuff said, for now.
Gs
Greg Schulz – Microsoft MVP Cloud and Data Center Management, VMware vExpert 2010-2017 (vSAN and vCloud). Author of Software Defined Data Infrastructure Essentials (CRC Press), as well as Cloud and Virtual Data Storage Networking (CRC Press), The Green and Virtual Data Center (CRC Press), Resilient Storage Networks (Elsevier) and twitter @storageio. Courteous comments are welcome for consideration. First published on https://storageioblog.com any reproduction in whole, in part, with changes to content, without source attribution under title or without permission is forbidden.
All Comments, (C) and (TM) belong to their owners/posters, Other content (C) Copyright 2006-2026 Server StorageIO and UnlimitedIO. All Rights Reserved. StorageIO is a registered Trade Mark (TM) of Server StorageIO.