VMware announces vSphere V6 and associated virtualization technologies

VMware has announced version 6 (V6) of its software defined data center (SDDC) server virtualization hypervisor called vSphere aka ESXi. In addition to a new version of its software defined server hypervisor along with companion software defined management and convergence tools.

VMware vSphere Refresh
As a refresh for those whose world does not revolve around VMware, vSphere and software defined data centers (believe it or not there are some who exist ;), ESXi is the hypervisor that virtualizes underlying physical machines (PM’s) known as hosts.
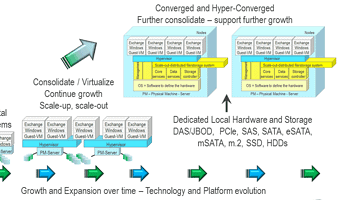
The path to software defined data center convergence
Guest operating systems (or other hypervisors using nesting) run as virtual machines (VM’s) on top of the vSphere hypervisor host (e.g. ESXi software). Various VMware management tools (or third-party) are used for managing the virtualized data center from initial configuration, configuration, conversion from physical to virtual (P2V) or virtual to virtual (V2V) along with data protection, performance, capacity planning across servers, storage and networks.
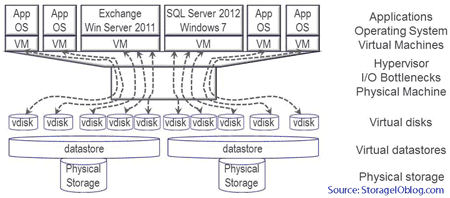
VMware vSphere is flexible and can adapt to different sized environments from small office home office (SOHO) or small SMB, to large SMB, SME, enterprise or cloud service provider. There are a free version of ESXi along with paid versions that include support and added management tool features. Besides the ESXi vSphere hypervisor, other commonly deployed modules include the vCenter administration along with Infrastructure Controller services platform among others. In addition, there are optional solution bundles to add support for virtual networking, cloud (public and private), data protection (backup/restore, replication, HA, BC, DR), big data among other capabilities.
What is new with vSphere V6
VMware has streamlined the installation, configuration and deployment of vSphere along with associated tools which for smaller environments makes things simply easier. For the larger environments, having to do less means being able to do more in the same amount of time which results in cost savings. In addition to easier to use, deploy and configure, VMware has extended the scaling capabilities of vSphere in terms of scaling-out (larger clusters), scaling-up (more and larger servers), as well as scaling-down (smaller environments and ease of use).

- Compute: Expanded support for new hardware, guest operating systems and general scalability in terms of physical, and virtual resources. For example increasing the number of virtual CPU (vCPUs), number of cluster nodes among other speeds and feeds enhancements.
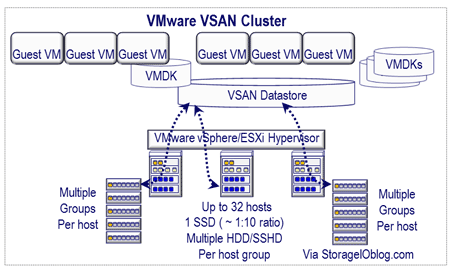
- Storage: This is an area where several enhancements were made including updates for Storage I/O controls (Storage QoS and performance optimizations) with per VM reservations, NFS v4.1 with Kerberos client, Virtual SAN (VSAN) improvements (new back-end underlying file system) as well as new Virtual Volumes (vVOLs) for Storage Policy Based Management.
- Availability: Improvements for vMotion (ability to live move virtual machines between physical servers (vmware hosts) including long distance fault-tolerance. Other improvements include faster replication, vMotion across vCenter servers, and long distance vMotion (up to 100ms round trip time latency).
- Network: Network I/O Control (NIOC) provides per VM and dat (VM and data repository) bandwidth reservations for quality of service (QoS) performance optimization.
- Management: Improvements for multi-site, virtual data centers, content-library (storage and versioning of files and objects including ISOs and OVFs (Open Virtualization Format files) that can be on a VMFS (VMware File System) dat or NFS volume, policy-based management and web-client performance enhancements.
What is vVOL?
The quick synopsis of VMware vVOL’s overview:
- Higher level of abstraction of storage vs. traditional SCSI LUN’s or NAS NFS mount points
- Tighter level of integration and awareness between VMware hypervisors and storage systems
- Simplified management for storage and virtualization administrators
- Removing complexity to support increased scaling
- Enable automation and service managed storage aka software defined storage management

How data storage access and managed via VMware today (read more here)
vVOL’s are not LUN’s like regular block (e.g. DAS or SAN) storage that use SAS, iSCSI, FC, FCoE, IBA/SRP, nor are they NAS volumes like NFS mount points. Likewise vVOL’s are not accessed using any of the various object storage access methods mentioned above (e.g. AWS S3, Rest, CDMI, etc) instead they are an application specific implementation. For some of you this approach of an applications specific or unique storage access method may be new, perhaps revolutionary, otoh, some of you might be having a DejaVu moment right about now.
vVOL is not a LUN in the context of what you may know and like (or hate, even if you have never worked with them), likewise it is not a NAS volume like you know (or have heard of), neither are they objects in the context of what you might have seen or heard such as S3 among others.
Keep in mind that what makes up a VMware virtual machine are the VMK, VMDK and some other files (shown in the figure below), and if enough information is known about where those blocks of data are or can be found, they can be worked upon. Also keep in mind that at least near-term, block is the lowest common denominator that all file systems and object repositories get built-up.

How VMware data storage accessed and managed with vVOLs (read more here)
Here is the thing, while vVOL’s will be accessible via a block interface such as iSCSI, FC or FCoE or for that matter, over Ethernet based IP using NFS. Think of these storage interfaces and access mechanisms as the general transport for how vSphere ESXi will communicate with the storage system (e.g. their data path) under vCenter management.
What is happening inside the storage system that will be presented back to ESXi will be different than a normal SCSI LUN contents and only understood by VMware hypervisor. ESXi will still tell the storage system what it wants to do including moving blocks of data. The storage system however will have more insight and awareness into the context of what those blocks of data mean. This is how the storage systems will be able to more closely integrate snapshots, replication, cloning and other functions by having awareness into which data to move, as opposed to moving or working with an entire LUN where a VMDK may live.
Keep in mind that the storage system will still function as it normally would, just think of vVOL as another or new personality and access mechanism used for VMware to communicate and manage storage. Watch for vVOL storage provider support from the who’s who of existing and startup storage system providers including Cisco, Dell, EMC, Fujitsu, HDS, HP, IBM, NetApp, Nimble and many others. Read more about Storage I/O fundamentals here and vVOLs here and here.
What this announcement means
Depending on your experiences, you might use revolutionary to describe some of the VMware vSphere V6 features and functionalities. Otoh, if you have some Dejavu moments looking pragmatically at what VMware is delivering with V6 of vSphere executing on their vision, evolutionary might be more applicable. I will leave it up to you do decide if you are having a Dejavu moment and what that might pertain to, or if this is all new and revolutionary, or something more along the lines of technolutionary.
VMware continues to execute delivering on the Virtual Data Center aka Software Defined Data Center paradigm by increasing functionality, as well as enhancing existing capabilities with performance along with resiliency improvements. These abilities enable the aggregation of compute, storage, networking, management and policies for enabling a global virtual data center while supporting existing along with new emerging applications.
Where to learn more
If you were not part of the beta to gain early hands-on experience with VMware vSphere V6 and associated technologies, download a copy to check it out as part of making your upgrade or migration plans.
Check out the various VMware resources including communities links here
VMware vSphere Hypervisor getting started and general vSphere information (including download)
VMware vSphere data sheet, compatibility guide along with speeds and feeds (size and other limits)

VMware Blogs and VMware vExpert page
Various fellow VMware vExpert blogs including among many others vsphere-land, scott lowe, virtuallyghetto and yellow-bricks among many others found at the vpad here.
StorageIO Out and About Update – VMworld 2014 (with Video)
VMware vVOL’s and storage I/O fundamentals (Storage I/O overview and vVOL, details Part I and Part II)
How many IOPs can a HDD or SSD do in a VMware environment (Part I and Part II)
VMware VSAN overview and primer, DIY converged software defined storage on a budget
Wrap up and summary
Overall VMware vSphere V6 has a great set of features that support both ease of management for small environments as well as the scaling needs of larger organizations.
Ok, nuff said, for now…
Cheers gs
Greg Schulz – Author Cloud and Virtual Data Storage Networking (CRC Press), The Green and Virtual Data Center (CRC Press) and Resilient Storage Networks (Elsevier)
twitter @storageio
All Comments, (C) and (TM) belong to their owners/posters, Other content (C) Copyright 2006-2026 Server StorageIO and UnlimitedIO LLC All Rights Reserved