
Part III – 3D XPoint server storage class memory SCM

Updated 1/31/2018
3D XPoint nvm pm scm storage class memory.
This is the third of a three-part series on the recent Intel and Micron 3D XPoint server storage memory announcement. Read Part I here and Part II here.
What is 3D XPoint and how does it work?
3D XPoint is a new class or class of memory (view other categories of memory here) that provides performance for reads and writes closer to that of DRAM with about 10x the capacity density. In addition to the speed closer to DRAM vs. the lower NAND flash, 3D XPoint is also non-volatile memory (NVM) like NAND flash, NVRAM and others. What this means is that 3D XPoint can be used as persistent higher density fast server memory (or main memory for other computers and electronics). Besides being fast persistent main memory, 3D XPoint will also be a faster medium for solid state devices (SSD’s) including PCIe Add In Cards (AIC), m2 cards and drive form factor 8637/8639 NVM Express (NVMe) accessed devices that also has better endurance or life span compared to NAND flash.

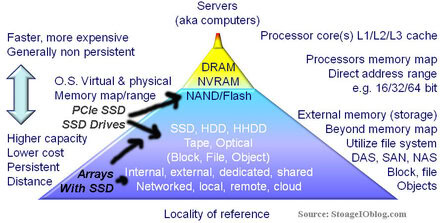
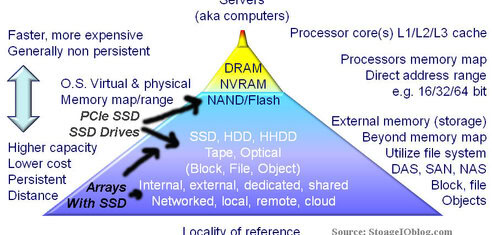
3D XPoint architecture and attributes
The initial die or basic chip building block 3D XPoint implementation is a layer 128 Gbit device which if using 8 bits would yield 16GB raw. Over time increased densities should become available as the bit density improves with more cells and further scaling of the technology, combined with packaging. For example while a current die could hold up to 16 GBytes of data, multiple dies could be packaged together to create a 32GB, 64GB, 128GB etc. or larger actual product. Think about not only where packaged flash based SSD capacities are today, also think in terms of where DDR3 and DDR4 DIMM are at such as 4GB, 8GB, 16GB, 32GB densities.
The 3D aspect comes from the memory being in a matrix initially being two layers high, with multiple rows and columns that intersect, where those intersections occur is a microscopic material based switch for accessing a particular memory cell. Unlike NAND flash where an individual cell or bit is accessed as part of a larger block or page comprising several thousand bytes at once, 3D XPoint cells or bits can be individually accessed to speed up reads and writes in a more granular fashion. It is this more granular access along with performance that will enable 3D XPoint to be used in lower latency scenarios where DRAM would normally be used.
Instead of trapping electrons in a cell to create a bit of capacity (e.g. on or off) like NAND flash, 3D XPoint leverages the underlying physical material propertied to store a bit as a phase change enabling use of all cells. In other words, instead of being electron based, it is material based. While Intel and Micron did not specify what the actual chemistry and physical materials that are used in 3D XPoint, they did discuss some of the characteristics. If you want to go deep, check out how the Dailytech makes an interesting educated speculation or thesis on the underlying technology.
Watch the following video to get a better idea and visually see how 3D XPoint works.
What are these chips, cells, wafers and dies?
Left many dies on a wafer, right, a closer look at the dies cut from the wafer
Dies (here and here) are the basic building block of what goes into the chips that in turn are the components used for creating DDR DIMM for main computer memory, as well as for create SD and MicroSD cards, USB thumb drives, PCIe AIC and drive form factor SSD, as well as custom modules on motherboards, or consumption via bare die and wafer level consumption (e.g. where you are doing really custom things at volume, beyond using a soldering iron scale).
Has Intel and Micron cornered the NVM and memory market?
We have heard proclamations, speculation and statements of the demise of DRAM, NAND flash and other volatile and NVM memories for years, if not decades now. Each year there is the usual this will be the year of “x” where “x” can include among others. Resistive RAM aka ReRAM or RRAM aka the memristor that HP earlier announced they were going to bring to market and then earlier this year canceling those plans while Crossbar continues to pursue RRAM. MRAM or Magnetorestive RAM, Phase Change Memory aka CRAM or PCM and PRAM, FRAM aka FeRAM or Ferroelectric RAM among others.

Expanding persistent memory and SSD storage markets
Keep in mind that there are many steps taking time measured in years or decades to go from research and development lab idea to prototype that can then be produced at production volumes in economic yields. As a reference for, there is still plenty of life in both DRAM as well as NAND flash, the later having appeared around 1989.

Technology industry adoption precedes customer adoption and deployment
There is a difference between industry adoption and deployment vs. customer adoption and deployment, they are related, yet separated by time as shown in the above figure. What this means is that there can be several years from the time a new technology is initially introduced and when it becomes generally available. Keep in mind that NAND flash has yet to reach its full market potential despite having made significant inroads the past few years since it was introduced in 1989.
This begs the question of if 3D XPoint is a variation of phase change, RRAM, MRAM or something else. Over at the Dailytech they lay out a line of thinking (or educated speculation) that 3D XPoint is some derivative or variation of phase change, time will tell about what it really is.
What’s the difference between 3D NAND flash and 3D XPoint?
3D NAND is a form of NAND flash NVM, while 3D XPoint is a completely new and different type of NVM (e.g. its not NAND).
3D NAND is a variation of traditional flash with the difference between vertical stacking vs. horizontal to improve density, also known as vertical NAND or V-NAND. Vertical stacking is like building up to house more tenants or occupants in a dense environment or scaling up, vs scaling-out by using up more space where density is not an issue. Note that magnetic HDD’s shifted to perpendicular (e.g. vertical) recording about ten years ago to break through the super parametric barrier and more recently, magnetic tape has also adopted perpendicular recording. Also keep in mind that 3D XPoint and the earlier announced Intel and Micron 3D NAND flash are two separate classes of memory that both just happen to have 3D in their marketing names.
Where to read, watch and learn more
- Intel and Micron unveil new 3D XPoint Non Volatile Memory (NVM) for servers and storage ( Part I)
- Part II – Intel and Micron new 3D XPoint server and storage NVM
- Part III – 3D XPoint new server storage memory from Intel and Micron
- Intel and Micron ( Media Room, links, videos, images and more including B roll videos)
- YouTube Video: Intel and Micron unveiled 3D XPoint Technology, a Faster Non-volatile Memory (NVM)
- Intel, Micron Launch "Bulk-Switching" ReRAM
- If Intel and Micron’s "Xpoint" is 3D Phase Change Memory, Boy Did They Patent It
- Intel & Micron 3D XPoint memory – is it just CBRAM hyped up?
- DRAM, DIMM, DDR3, nand flash memory, SSD, stating what’s often assumed
- Intel site and Micron site
- www.thessdplace.com and www.thenvmeplace.com
Additional learning experiences along with common questions (and answers), as well as tips can be found in Software Defined Data Infrastructure Essentials book.

What This All Means
First, keep in mind that this is very early in the 3D XPoint technology evolution life-cycle and both DRAM and NAND flash will not be dead at least near term. Keep in mind that NAND flash appeared back in 1989 and only over the past several years has finally hit its mainstream adoption stride with plenty of market upside left. Same with DRAM which has been around for sometime, it too still has plenty of life left for many applications. However other applications that have the need for improved speed over NAND flash, or persistency and density vs. DRAM will be some of the first to leverage new NVM technologies such as 3D XPoint. Thus at least for the next several years, there will be a co-existences between new and old NVM and DRAM among other memory technologies. Bottom line, 3D XPoint is a new class of NVM memory, can be used for persistent main server memory or for persistent fast storage memory. If you have not done so, check out Part I here and Part II here of this three-part series on Intel and Micron 3D XPoint.
Disclosure: Micron and Intel have been direct and/or indirect clients in the past via third-parties and partners, also I have bought and use some of their technologies direct and/or in-direct via their partners.
Ok, nuff said, for now.
Gs
Greg Schulz – Microsoft MVP Cloud and Data Center Management, VMware vExpert 2010-2017 (vSAN and vCloud). Author of Software Defined Data Infrastructure Essentials (CRC Press), as well as Cloud and Virtual Data Storage Networking (CRC Press), The Green and Virtual Data Center (CRC Press), Resilient Storage Networks (Elsevier) and twitter @storageio. Courteous comments are welcome for consideration. First published on https://storageioblog.com any reproduction in whole, in part, with changes to content, without source attribution under title or without permission is forbidden.
All Comments, (C) and (TM) belong to their owners/posters, Other content (C) Copyright 2006-2026 Server StorageIO and UnlimitedIO. All Rights Reserved. StorageIO is a registered Trade Mark (TM) of Server StorageIO.



























{kind=link}