March 31st is world backup day; when is world recovery day
If March 31st is world backup day, when is world recovery day?
For several years, if not decades, March 31st has been world backup day, a reminder to protect and backup your apps and data. Data protection, including backup, recovery, business continuance (BC), disaster recovery (DR), and business resilience (BR), should be a 365-day-a-year focus. If you have regular data protection, including backup, that is great; when was the last time you tested restore?
Some related content
Upcoming and past events including webinars, tips and commentary
World Backup Day Reminder Don’t Be an April Fool Test Your Data Recovery
Data Infrastructure Overview, Its What’s Inside of a Data Center
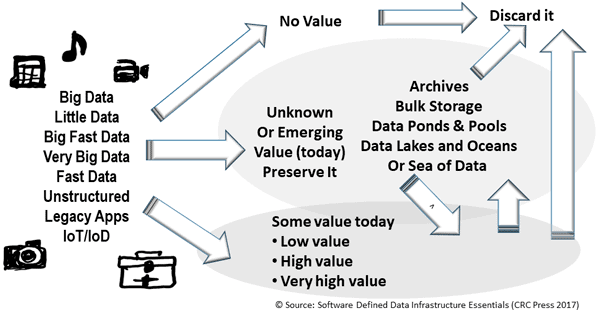
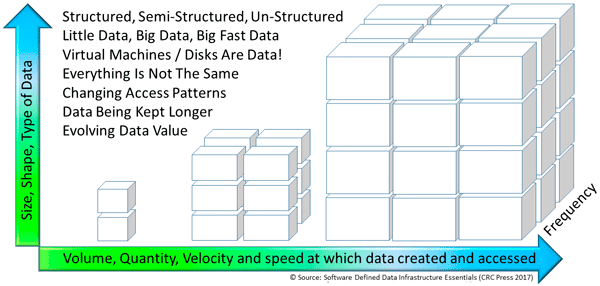
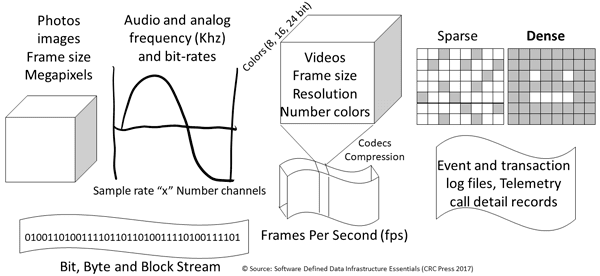
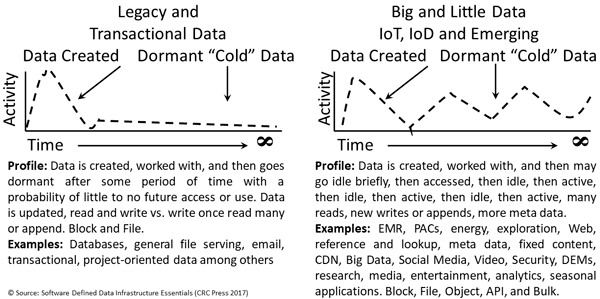
Application Data Value Characteristics Everything Is Not The Same
Data Protection Diaries Topics Tools Techniques Technologies Tips
Reminder to Protect your data and apps and settings
Thus, this is also a reminder to protect your data and apps and their settings regularly. What’s even better is evolving from none once a year to more frequent data protection, including backup of your critical and noncritical apps and data. Notice I keep mentioning apps and not just the usual focus of or on data. Program apps are considered broadly data; after all, apps and your settings and metadata are just data when stored and protected.
There is also often a focus on just the data, which can lead to problems when it comes time to recover an app program, settings, or metadata. Also, a reminder that data protection, including backup, is not just for large enterprises; it applies to organizations and entities of all sizes, including small and medium businesses (SMBs), non-profits, and homes (e.g., your photos, worksheets, and other documents).
What About Recovery
If March 31st is world backup day, when is world recovery day? So far, I have been talking about backup as part of data protection or ensuring your apps, data, and settings are protected; what about recovery?
Sometimes with data protection, discussions can drift into what’s more critical, backup or recovery, which is a bit like a chicken and egg situation. In other words, what’s more important, the chicken or the egg? Similar to data protection, what’s more critical, backup or recovery?
Recovery is only as good as your backup (or snapshot, point-in-time copy, checkpoint, or consistency point), and your backup or protection copy is only as good as its recoverability. Recoverability means that not only is there something to restore from a point in time (e.g., recovery point objective or RPO) in a given amount of time (recovery time objective or RTO).
Recoverability also means that you can pull the data (e.g., bits, bytes, blocks, blobs, objects, files, tables) from the protection medium, media, or service and use it. Recovery means that the data is valid and consistent, has integrity, or is otherwise not bad, missing, damaged, or corrupted (e.g., usable).
What About Recovery Day?
For several years I have mentioned and will continue to do so that if March 31st is world backup day, then April 1st should be a world recovery day. So why April 1st for world recovery day? Simple, you don’t want to look like a fool the day after world backup day if you can’t restore and use data backed up the day before.
If you are not comfortable with April 1st for world recovery day? Then make your world recovery day (or test) a day or so later. The important message is to ensure your apps, data, and settings are protected (e.g., copied, backed up, snapshot, checkpoint, etc.), trust yet verify, and test your restorations.
Why do I mentation apps, data, and settings?
The important message here is that it is good if you are already protecting your data, your spreadsheets, worksheets, databases, files, photos, and the application programs that use them. However, also ensure that you are protecting application settings, configurations, metadata, encryption keys, the backup or protection mechanisms, and their data.
For example, when I accidentally delete a data file or configuration settings, I can restore those without recovering everything. Suppose, for instance, I accidentally or intentionally uninstall an application program. In that case, I can reinstall (assuming I have a copy of the program), then restore my settings and pick up where I resumed.
Who does this apply to?
From organizations of size and type to individuals. If you have or generate or save data, if it is worth having (or you have to keep it), then it should be protected. What how often to protect data (time interval) will be based on what your recovery point objective (RPO) is. Likewise how fast you need to recover with your recovery time objective (RTO).
Remember that it is not if you will need to restore, recover, reload, refresh, or repair your apps, data, and settings instead when. It might be because of accidental or planned deletion, accident, hardware, software, cloud service situation, ransomware, or malware, among other things that can and do happen.
What to do?
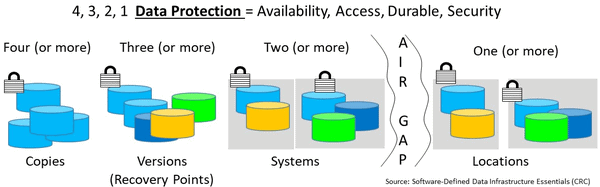
If March 31st is world backup day, when is world recovery day? Ensure you have regular copies of your apps, data, and configuration settings, including encryption keys. Implement a variation of the old school three two one (e.g., 3 2 1) data protection, e.g., backup scheme (e.g., three or more copies, stored on two or more devices, systems, media or mediums, and at least one of them offsite preferably offline including at cloud).
A variation of the new school 4 3 2 1 data protection scheme has:
Have four or more versions of your protected data.
Three or more copies (feel free to swap the number of copies and versions).
Stored on two or more different systems (devices, media, or locations).
At least one copy offsite (preferably with one offline), including cloud.
The big difference between the old school 3 2 1 and the new school 4 3 2 1 is the emphasis and distinction of having multiple copies and various versions (e.g., points in time). For example, storing three copies on two systems with one offsite is good unless all copies are damaged. Having different versions (e.g., point in time) and multiple copies of those versions stored in different places including at least one offline (e.g., air-gapped), is essential.
Trust yet verify, test your backups and recovery
Test to verify your data protection is working and that data (apps, data, settings) can be restored. When testing restores, be careful not to overwrite your good data and cause a disaster. Also, ensure your data is encrypted in multiple locations and layers and that you protect your encryption keys. Finally, make sure your backup, protection software, catalog, and settings are encrypted, secured, and protected.
If you have questions, not sure, learn more here in my book Software Defined Data Infrastructure Essentials (CRC Press), Data Infrastructure Management Insight and Strategies (CRC Press), as well as check out these listed below, or reach out to me or others. If you are an individual consumer and just looking to protect some photos, valuable documents, and heirlooms, get in touch with professionals who specialize in these types of things.
What do I do?
Implement 4 3 2 1 type data protection with different granularities and frequencies. For example, my data protection includes regular point-in-time copies, including backups and snapshots, checkpoints, consistency points of systems, volumes, shares, apps, files, data, and settings at different intervals. Having different types of apps and data, some of which are more static vs. others that are changing, protection is also varied to avoid treating everything the same, reduce cost, and increase coverage.
I protect my Apps, data, and settings with multiple versions and copies locally on different systems, devices, mediums, and offsite, including offline and at cloud services. So why do I store data offsite vs. having it all in the cloud? Simple, speed of recovery, and flexibility.
If it’s a few files, perhaps a few GBs of data, it is usually faster for me if I don’t have a good copy locally to get it from Microsoft Azure. Otoh, if I need to restore TBs of data (something terrible happens), then it can be faster to bring an offline, offsite copy back, correct that, then only pull the more recent data I need from the cloud.
What are some of the tools and technologies that I use?
Locally I have multiple Microsoft Windows Servers (Server 2022) with various storage (HDDs and SSDs), including removable devices. In addition to on-prem, I have data stored offsite on removable media and cloud copies. For my cloud copies, I have a mix of files and blobs stored at Microsoft Azure.
A challenge moving from AWS to Azure was Retrospect did not support objects (Azure blobs). I realized, no worries, Retrospect supports storing data on local storage (SSD or HDD) on regular filesystems as files. The solution was set up an Azure file share for Retrospect, and everything has worked fantastic.
Are there things I need and want to improve? Yes, it’s an ongoing process and journey.
What should you do next?
Make sure you have a data backup; if not, march 31st is a good reminder. Trust yet verify your backups are working and you can recover and not be an April 1st fool.
Where to learn more
Learn more about world backup day, recovery and data protection along with other related topics via the following links:
Upcoming and past events including webinars, tips and commentary
Next Generation Hybrid Data Infrastructures Are In Your Future
Cloud File Data Storage Consolidation and Economic Comparison Model
New Book Data Infrastructure Management Insight Strategies
World Backup Day Reminder Don’t Be an April Fool Test Your Data Recovery
Virtual, Cloud and IT Availability, it’s a shared responsibility
Don’t Stop Learning Expand Your Skills Experiences Everyday
Data Infrastructure Overview, Its What’s Inside of a Data Center
Application Data Value Characteristics Everything Is Not The Same
Data Protection Diaries Topics Tools Techniques Technologies Tips
Data Infrastructure Server Storage I/O related Tradecraft Overview
Additional learning experiences can be found in Software Defined Data Infrastructure Essentials book. Also check out Data Infrastructure Management Insight and Strategies.

What this all means
If March 31st is world backup day, when is world recovery day? Every day should be a backup day (e.g., some protection, backup, copy, snapshot, checkpoint, consistency point). Likewise, every day should be able to be a recovery day. World backup day and recovery apply to organizations of all sizes and individuals. Remember that If March 31st is world backup day, when is world recovery day?
Ok, nuff said.
Cheers gs
Greg Schulz – Multi-year Microsoft MVP Cloud and Data Center Management, ten-time VMware vExpert. Author of Data Infrastructure Insights (CRC Press), Software Defined Data Infrastructure Essentials (CRC). Cloud and Virtual Data Storage Networking (CRC), The Green and Virtual Data Center (CRC), Resilient Storage Networks (Elsevier). Visit twitter @storageio as well as www.picturesoverstillwater.com to view various UAS/UAV e.g. drone based aerial content created by Greg Schulz. Courteous comments are welcome for consideration. First published on https://storageioblog.com. Any reproduction without attribution or without permission is forbidden.
All Comments, (C) and (TM) belong to their owners/posters, Other content (C) Copyright 2006-2026 Server StorageIO and UnlimitedIO. Visit our companion site https://picturesoverstillwater.com to view drone based aerial photography and video related topics. All Rights Reserved. StorageIO is a registered Trade Mark (TM) of Server StorageIO and UnlimitedIO LLC.