VMware continues cloud construction with March announcements

VMware continues cloud construction with March announcements of new features and other enhancements.
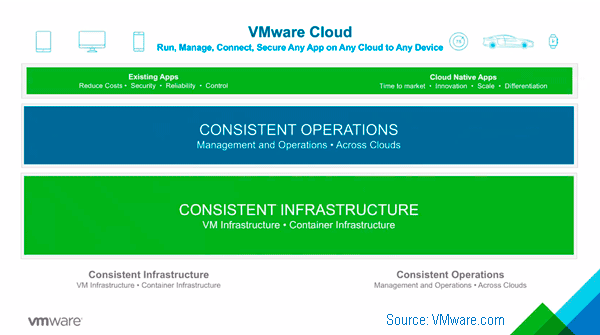
VMware Cloud Provides Consistent Operations and Infrastructure Via: VMware.com
With its recent announcements, VMware continues cloud construction adding new features, enhancements, partnerships along with services.
VMware continues cloud construction, like other vendors and service providers who tried and test the waters of having their own public cloud, VMware has moved beyond its vCloud Air initiative selling that to OVH. VMware which while being a public traded company (VMW) is by way of majority ownership part of the Dell Technologies family of company via the 2016 acquisition of EMC by Dell. What this means is that like Dell Technologies, VMware is focused on providing solutions and services to its cloud provider partners instead of building, deploying and running its own cloud in competition with partners.
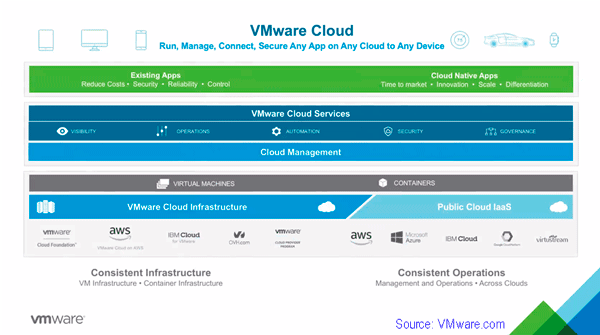
VMware Cloud Data Infrastructure and SDDC layers Via: VMware.com
The VMware Cloud message and strategy is focused around providing software solutions to cloud and other data infrastructure partners (and customers) instead of competing with them (e.g. divesting of vCloud Air, partnering with AWS, IBM Softlayer). Part of the VMware cloud message and strategy is to provide consistent operations and management across clouds, containers, virtual machines (VM) as well as other software defined data center (SDDC) and software defined data infrastructures.
In other words, what this means is VMware providing consistent management to leverage common experiences of data infrastructure staff along with resources in a hybrid, cross cloud and software defined environment in support of existing as well as cloud native applications.
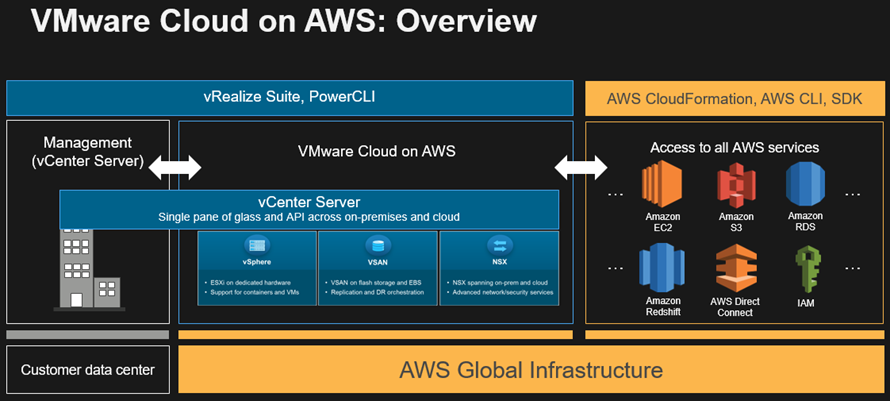
VMware Cloud on AWS Image via: AWS.com
Note that VMware Cloud services run on top of AWS EC2 bare metal (BM) server instances, as well as on BM instances at IBM softlayer as well as OVH. Learn more about AWS EC2 BM compute instances aka Metal as a Service (MaaS) here. In addition to AWS, IBM and OVH, VMware claims over 4,000 regional cloud and managed service providers who have built their data infrastructures out using VMware based technologies.
VMware continues cloud construction updates
Building off of previous announcements, VMware continues cloud construction with enhancements to their Amazon Web Services (AWS) partnership along with services for IBM Softlayer cloud as well as OVH. As a refresher, OVH is what formerly was known as VMware vCloud air before it was sold off.
Besides expanding on existing cloud partner solution offerings, VMware also announced additional cloud, software defined data center (SDDC) and other software defined data infrastructure environment management capabilities. SDDC and Data infrastructure management tools include leveraging VMwares acquisition of Wavefront among others.
VMware Cloud Updates and New Features
- VMware Cloud on AWS European regions (now in London, adding Frankfurt German)
- Stretch Clusters with synchronous replication for cross geography location resiliency
- Support for data intensive workloads including data footprint reduction (DFR) with vSAN based compression and data de duplication
- Fujitsu services offering relationships
- Expanded VMware Cloud Services enhancements
VMware Cloud Services enhancements include:
- Hybrid Cloud Extension
- Log intelligence
- Cost insight
- Wavefront
VMware Cloud in additional AWS Regions
As part of service expansion, VMware Cloud on AWS has been extended into European region (London) with plans to expand into Frankfurt and an Asian Pacific location. Previously VMware Cloud on AWS has been available in US West Oregon and US East Northern Virginia regions. Learn more about AWS Regions and availability zones (AZ) here.
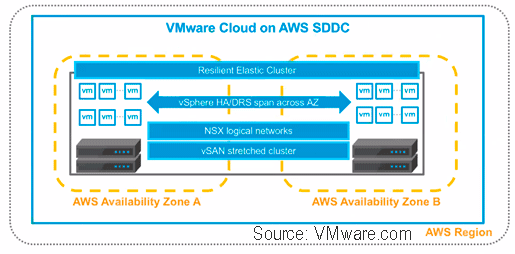
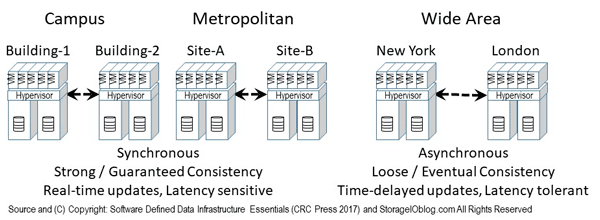
VMware Cloud on AWS Stretch Clusters Source: VMware.com
VMware Cloud on AWS Stretch Clusters
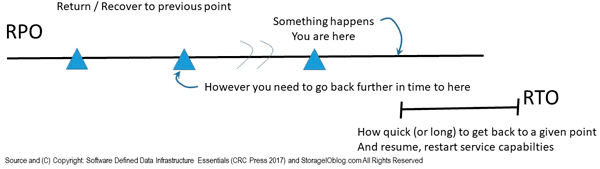
In addition to expanding into additional regions, VMware Cloud on AWS is also being extended with stretch clusters for geography dispersed protection. Stretched clusters provide protection against an AZ failure (e.g. data center site) for mission critical applications. Build on vSphere HA and DRS automated host failure technology, stretched clusters provide recovery point objective zero (RPO 0) for continuous protection, high availability across AZs at the data infrastructure layer.
The benefit of data infrastructure layer based HA and resiliency is not having to re architect or modify upper level, higher up layered applications or software. Synchronous replication between AZs enables RPO 0, if one AZ goes down, it is treated as a vSphere HA event with VMs restarted in another AZ.
vSAN based Data Footprint Reduction (DFR) aka Compression and De duplication
To support applications that leverage large amounts of data, aka data intensive applications in marketing speak, VMware is leveraging vSAN based data footprint reduction (DFR) techniques including compression as well as de duplication (dedupe). Leveraging DFR technologies like compression and dedupe integrated into vSAN, VMware Clouds have the ability to store more data in a given cubic density. Storing more data in a given cubic density storage efficiency (e.g. space saving utilization) as well as with performance acceleration, also facilitate storage effectiveness along with productivity.
With VMware vSAN technology as one of the core underlying technologies for enabling VMware Cloud on AWS (among other deployments), applications with large data needs can store more data at a lower cost point. Note that VMware Cloud can support 10 clusters per SDDC deployment, with each cluster having 32 nodes, with cluster wide and aware dedupe. Also note that for performance, VMware Cloud on AWS leverages NVMe attached Solid State Devices (SSD) to boost effectiveness and productivity.
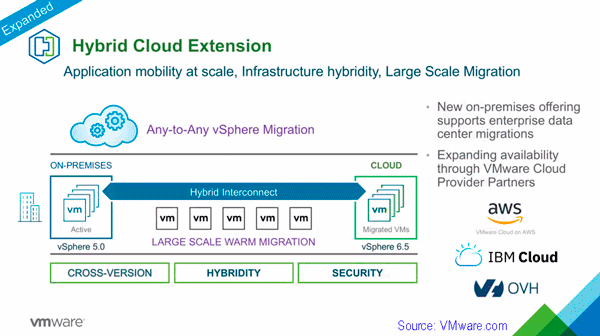
Extending VMware vSphere any to any migration across clouds Source: VMware.com
VMware Hybrid Cloud Extension
VMware Hybrid Cloud Extension enables common management of common underlying data infrastructure as well as software defined environments including across public, private as well as hybrid clouds. Some of the capabilities include enabling warm VM migration across various software defined environments from local on-premises and private cloud to public clouds.
New enhancements leverages previously available technology now as a service for enterprises besides service providers to support data center to data center, or cloud centric AZ to AZ, as well as region to region migrations. Some of the use cases include small to large bulk migrations of hundreds to thousands of VM move and migrations, both scheduling as well as the actual move. Move and migrations can span hybrid deployments with mix of on-premises as well as various cloud services.
VMware Cloud Cost Insight
VMware Cost Insight enables analysis, compare cloud costs across public AWS, Azure and private VMware clouds) to avoid flying blind in and among clouds. VMware Cloud cost insight enables awareness of how resources are used, their cost and benefit to applications as well as IT budget impacts. Integrates vSAN sizer tool along with AWS metrics for improved situational awareness, cost modeling, analysis and what if comparisons.
With integration to Network insight, VMware Cloud Cost Insight also provides awareness into networking costs in support of migrations. What this means is that using VMware Cloud Cost insight you can take the guess-work out of what your expenses will be for public, private on-premisess or hybrid cloud will be having deeper insight awareness into your SDDC environment. Learn more about VVMware Cost Insight here.
VMware Log Intelligence
Log Intelligence is a new VMware cloud service that provides real-time data infrastructure insight along with application visibility from private, on-premises, to public along with hybrid clouds. As its name implies, Log Intelligence provides syslog and other log insight, analysis and intelligence with real-time visibility into VMware as well as AWS among other resources for faster troubleshooting, diagnostics, event correlation and other data infrastructure management tasks.
Log and telemetry input sources for VMware Log Intelligence include data infrastructure resources such as operating systems, servers, system statistics, security, applications among other syslog events. For those familiar with VMware Log Insight, this capability is an extension of that known experience expanding it to be a cloud based service.

Wavefront by VMware Source: VMware.com
VMware Wavefront
VMware Wavefront enables monitoring of cloud native high scale environments with custom metrics and analytics. As a reminder Wavefront was acquired by VMware to enable deep metrics and analytics for developers, DevOps, data infrastructure operations as well as SaaS application developers among others. Wavefront integrates with VMware vRealize along with enabling monitoring of AWS data infrastructure resources and services. With the ability to ingest, process, analyze various data feeds, the Wavefront engine enables the predictive understanding of mixed application, cloud native data and data infrastructure platforms including big data based.
Where to learn more
Learn more about VMware, vSphere, vRealize, VMware Cloud, AWS (and other clouds), along with data protection, software defined data center (SDDC), software defined data infrastructures (SDDI) and related topics via the following links:
- VMware Cloud Briefing site
- VMware vRealize Cloud Management Platform (Application delivery and operations automation across clouds)
- VMware Cost Insight (Analyze and compare cloud costs across public AWS, Azure and private VMware clouds)
- VMware Network Insight (Accelerate application security and networking across public, private, hybrid clouds)
- VMware Wavefront (Monitor cloud native high scale environments with custom metrics and analytics
- VMware Cloud Community resources
- VMware Cloud Partner resources
- VMware vSAN V6.6 Part V (vSAN evolution and summary)
- Dell EMC World 2017 Day One news announcement summary
- September 2017 Server StorageIO Data Infrastructure Update Newsletter
- Getting Caught Up What Happened In September 2017
- Travel Fun Crossword Puzzle For VMworld 2017 Las Vegas
- Hot Popular New Trending Data Infrastructure Vendors To Watch
- Dell EMC VMware September 2017 Software Defined Data Infrastructure Updates
- Amazon Web Service AWS September 2017 Software Defined Data Infrastructure Updates
- Data Infrastructure server storage I/O network Recommended Reading
- EMC is now Dell EMC, part of Dell Technologies and other server storage Updates
- World Backup Day 2018 Data Protection Readiness Reminder
- Data Infrastructure Server Storage I/O related Tradecraft Overview
- Data Infrastructure Overview, Its What’s Inside of Data Centers
- 4 3 2 1 and 3 2 1 data protection best practices
- Software Defined, Converged Infrastructure (CI), Hyper-Converged Infrastructure (HCI) resources
- The SSD Place (SSD, NVM, PM, SCM, Flash, NVMe, 3D XPoint, MRAM and related topics)
- The NVMe Place (NVMe related topics, trends, tools, technologies, tip resources)
- Data Protection Diaries (Archive, Backup/Restore, BC, BR, DR, HA, RAID/EC/LRC, Replication, Security)
- Software Defined Data Infrastructure Essentials (CRC Press 2017) including SDDC, Cloud, Container and more

Additional learning experiences along with common questions (and answers), as well as tips can be found in Software Defined Data Infrastructure Essentials book.

What this all means and wrap-up
VMware continues cloud construction. For now, it appears that VMware like Dell Technologies is content on being a technology provider partner to large as well as small public, private and hybrid cloud environments instead of building their own and competing. With these series of announcements, VMware continues cloud construction enabling its partners and customers on their various software defined data center (SDDC) and related data infrastructure journeys. Overall, this is a good set of enhancements, updates, new and evolving features for their partners as well as customers who leverage VMware based technologies. Meanwhile VMware continues cloud construction.
Ok, nuff said, for now.
Gs
Greg Schulz – Microsoft MVP Cloud and Data Center Management, VMware vExpert 2010-2017 (vSAN and vCloud). Author of Software Defined Data Infrastructure Essentials (CRC Press), as well as Cloud and Virtual Data Storage Networking (CRC Press), The Green and Virtual Data Center (CRC Press), Resilient Storage Networks (Elsevier) and twitter @storageio. Courteous comments are welcome for consideration. First published on https://storageioblog.com any reproduction in whole, in part, with changes to content, without source attribution under title or without permission is forbidden.
All Comments, (C) and (TM) belong to their owners/posters, Other content (C) Copyright 2006-2026 Server StorageIO and UnlimitedIO. All Rights Reserved. StorageIO is a registered Trade Mark (TM) of Server StorageIO.