Modernizing Data Protection = Using new and old things in new ways
This is part of an ongoing series of posts that part of www.storageioblog.com/data-protection-diaries-main/ on data protection including archiving, backup/restore, business continuance (BC), business resiliency (BC), data footprint reduction (DFR), disaster recovery (DR), High Availability (HA) along with related themes, tools, technologies, techniques, trends and strategies.

Keep in mind that a fundamental goal of an Information Technology (IT) organization is to protect, preserve and serve data and information in a cost-effective as well as productive way when needed. There is no such thing as an information recession with more data being generated and processed. In addition to more of it, data is also getting larger, having more dependencies on it being available as well as living longer (e.g. retention).
Proof Points, No Data or Information Recession
A quick easy proof point of more data and it getting larger is your cell phone and the pictures it take. Compare the size of those photos today to what you had in your previous generation of smart phone or even digital camera as the Mega Pixels (e.g. resolution and size of data) increased, along with the size of media (e.g. storage) to save those to also grew. Another proof point is look at your presentations, documents, web sites and other mediums with how the amount of rich or unstructured content (e.g. photos, videos) exists on those now vs. a few years ago. Yet another proof-point is to look at your structured little data databases and how there are more rows and columns, as well as how some of those columns have gotten larger or are point to external "blobs" or "objects" that have also gotten larger.
Industry trend and challenges
There has been industry buzz the past several years around data protection modernizing, modernizing data protection or simply modernizing backup along with modernizing your data and information infrastructure. Many of these conversations focus around swapping out an older technology in favor of whatever the new industry buzzword trend is (e.g. swap tape for disk, disk for cloud) or perhaps from one data protection, backup, archive or copy tool for another. Some of these conversations also focus around swapping legacy for virtual, cloud or some other variation of software defined marketing.
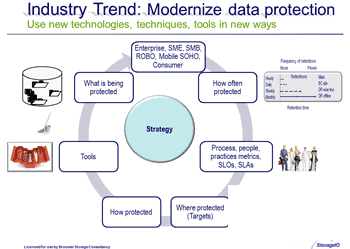
The Opportunity to do new things
What is common with all the above is basically swapping out one technology, tool, medium or technique for another new one yet using it in old ways. For example tape gets swapped for disk, yet the same approach to when, where, why, how often and what gets copied or protected is left the same. Sure some new tools and technologies get introduced. However when was the last time you put the tools down, took a step back and revisited the fundamental questions of how and why you are doing data protection the way it is being done? When was the last time you thought about data protection as an asset or business enabler as opposed to a cost center, overhead or after thought?

What’s in your data protection toolbox, do you know what to use when?
What about modernizing beyond the tools
One of the challenges with modernizing is that there is a cost involved including people time, staff skills as well as budgets not to mention keeping things running, so how do you go about paying for any improvements? Sure you can go get a data infrastructure or habitat for technology aka data home improvement loan, however there are costs associated to that.

What about reducing data protection costs?
So why not self-fund the improvements and modernization activities by finding and removing costs, eliminating complexity vs. moving and masking issues? Part of this can be accomplished by simply revisiting if you are treating all your applications and data the same from a data protection perspective. Are you providing a data protection service ability to your organization that is based on business wants or business needs? For example, does the business want recovery time objective (RTO) 0 and recovery point objective (RPO) 0 for all applications, while it needs RTO 4 hours and RPO 15 minutes for application-a while application-b requires RTO 12 hours and RPO of 2 hours and application must have RTO 24 hours with RPO of 12 hours?
As a reminder RTO is how much time, or how quickly you need your applications and data to be restored and made ready for use. RPO is the point in time to where data needs to be protected as of, or the amount of data or time frame data could be lost or missing. Thus RTO = 0 means instant recovery no downtime and RPO = 0 means no loss of data. RTO one day and RPO of ten (10) minutes means applications and their data are ready for use within 24 hours and no more than 10 minutes of data can be lost (e.g. the granularity of protection coverage)., Also keep in mind that you can have various RTO and RPO combinations to meet your specific application along with business needs as part of a tiered data protection strategy implementation.
With RTO and RPO in mind, when was the last time you sat down with the business and applications people to revisit what they want vs. what they must have? From these conversation you can easily Transition into how long to keep, how many copies in what place among other things which in turn allows you to review data protection as well as start using both old and new technologies, tools and techniques in new ways.
Where to learn more
Learn more about data protection and related topics, themes, trends, tools and technologies via the following links:
- Cloud conversations: If focused on cost you might miss other cloud storage benefits
- Data Protection Diaries
- Cloud Conversations: AWS overview and primer
- Are more than five nines of availability really possible?
- How do primary storage clouds and cloud for backup differ?
- What’s most important to know about my cloud privacy policy?
What this all means and wrap-up
Data protection is a broad topic that spans from logical and physical security to HA, BC, BR, DR, archiving (including life beyond compliance) along with various tools, technologies, techniques. Key is aligning those to the needs of the business or organization for today’s as well as tomorrows requirements. Instead of doing things what has been done in the past that may have been based on what was known or possible due to technology capabilities, why not start using new and old things in new ways. Let’s start using all the tools in the data protection toolbox regardless of if they are new or old, cloud, virtual, physical, software defined product or service in new ways while keeping the requirements of the business in focus.
Keeping with the theme of protect preserve and serve, data protection to be modernized needs to become and be seen as a business asset or enabler vs. an after thought or cost over-head topic. Also, keep in mind that only you can prevent data loss, are your restores ready for when you need them? as well as one of the fundamental goals of IT is to protect, preserve and serve information including its applications as well as data when, where needed in a cost-effective way.
What say you?
Ok, nuff said for now
Cheers
Gs
Greg Schulz – Author Cloud and Virtual Data Storage Networking (CRC Press), The Green and Virtual Data Center (CRC Press) and Resilient Storage Networks (Elsevier)
twitter @storageio
All Comments, (C) and (TM) belong to their owners/posters, Other content (C) Copyright 2006-2026 Server StorageIO and UnlimitedIO LLC All Rights Reserved