Part 4 – Which HDD for Content Applications – Database Workloads

Updated 1/23/2018
Which enterprise HDD to use with a content server platform for database workloads
Insight for effective server storage I/O decision making
Server StorageIO Lab Review

This is the fourth in a multi-part series (read part three here) based on a white paper hands-on lab report I did compliments of Servers Direct and Seagate that you can read in PDF form here. The focus is looking at the Servers Direct (www.serversdirect.com) converged Content Solution platforms with Seagate Enterprise Hard Disk Drive (HDD’s). In this post the focus expands to database application workloads that were run to test various HDD’s.
Database Reads/Writes
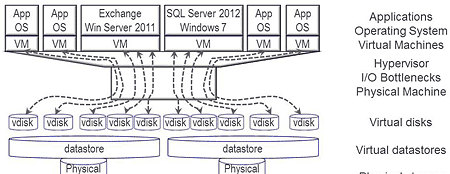
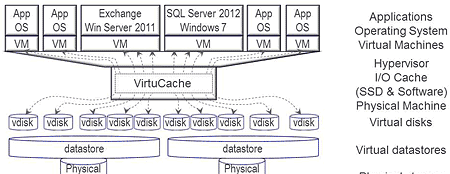
Transaction Processing Council (TPC) TPC-C like workloads were run against the SUT from the STI. These workloads simulated transactional, content management, meta-data and key-value processing. Microsoft SQL Server 2012 was configured and used with databases (each 470GB e.g. scale 6000) created and workload generated by virtual users via Dell Benchmark Factory (running on STI Windows 2012 R2).
A single SQL Server database instance (8) was used on the SUT, however unique databases were created for each HDD set being tested. Both the main database file (.mdf) and the log file (.ldf) were placed on the same drive set being tested, keep in mind the constraints mentioned above. As time was a constraint, database workloads were run concurrent (9) with each other except for the Enterprise 10K RAID 1 and RAID 10. Workload was run with two 10K HDD’s in a RAID 1 configuration, then another workload run with a four drive RAID 10. In a production environment, ideally the .mdf and .ldf would be placed on separate HDD’s and SSDs.
To improve cache buffering the SQL Server database instance memory could be increased from 16GB to a larger number that would yield higher TPS numbers. Keep in mind the objective was not to see how fast I could make the databases run, rather how the different drives handled the workload.
(Note 8) The SQL Server Tempdb was placed on a separate NVMe flash SSD, also the database instance memory size was set to 16GB which was shared by all databases and virtual users accessing it.
(Note 9) Each user step was run for 90 minutes with a 30 minute warm-up preamble to measure steady-state operation.
Users | TPCC Like TPS | Single Drive Cost per TPS | Drive Cost per TPS | Single Drive Cost / Per GB Raw Cap. | Cost / Per GB Usable (Protected) Cap. | Drive Cost (Multiple Drives) | Protect | Cost per usable GB per TPS | Resp. Time (Sec.) | |
ENT 15K R1 | 1 | 23.9 | $24.94 | $49.89 | $0.99 | $0.99 | $1,190 | 100% | $49.89 | 0.01 |
ENT 10K R1 | 1 | 23.4 | $37.38 | $74.77 | $0.49 | $0.49 | $1,750 | 100% | $74.77 | 0.01 |
ENT CAP R1 | 1 | 16.4 | $24.26 | $48.52 | $0.20 | $0.20 | $ 798 | 100% | $48.52 | 0.03 |
ENT 10K R10 | 1 | 23.2 | $37.70 | $150.78 | $0.49 | $0.97 | $3,500 | 100% | $150.78 | 0.07 |
ENT CAP SWR5 | 1 | 17.0 | $23.45 | $117.24 | $0.20 | $0.25 | $1,995 | 20% | $117.24 | 0.02 |
ENT 15K R1 | 20 | 362.3 | $1.64 | $3.28 | $0.99 | $0.99 | $1,190 | 100% | $3.28 | 0.02 |
ENT 10K R1 | 20 | 339.3 | $2.58 | $5.16 | $0.49 | $0.49 | $1,750 | 100% | $5.16 | 0.01 |
ENT CAP R1 | 20 | 213.4 | $1.87 | $3.74 | $0.20 | $0.20 | $ 798 | 100% | $3.74 | 0.06 |
ENT 10K R10 | 20 | 389.0 | $2.25 | $9.00 | $0.49 | $0.97 | $3,500 | 100% | $9.00 | 0.02 |
ENT CAP SWR5 | 20 | 216.8 | $1.84 | $9.20 | $0.20 | $0.25 | $1,995 | 20% | $9.20 | 0.06 |
ENT 15K R1 | 50 | 417.3 | $1.43 | $2.85 | $0.99 | $0.99 | $1,190 | 100% | $2.85 | 0.08 |
ENT 10K R1 | 50 | 385.8 | $2.27 | $4.54 | $0.49 | $0.49 | $1,750 | 100% | $4.54 | 0.09 |
ENT CAP R1 | 50 | 103.5 | $3.85 | $7.71 | $0.20 | $0.20 | $ 798 | 100% | $7.71 | 0.45 |
ENT 10K R10 | 50 | 778.3 | $1.12 | $4.50 | $0.49 | $0.97 | $3,500 | 100% | $4.50 | 0.03 |
ENT CAP SWR5 | 50 | 109.3 | $3.65 | $18.26 | $0.20 | $0.25 | $1,995 | 20% | $18.26 | 0.42 |
ENT 15K R1 | 100 | 190.7 | $3.12 | $6.24 | $0.99 | $0.99 | $1,190 | 100% | $6.24 | 0.49 |
ENT 10K R1 | 100 | 175.9 | $4.98 | $9.95 | $0.49 | $0.49 | $1,750 | 100% | $9.95 | 0.53 |
ENT CAP R1 | 100 | 59.1 | $6.76 | $13.51 | $0.20 | $0.20 | $ 798 | 100% | $13.51 | 1.66 |
ENT 10K R10 | 100 | 560.6 | $1.56 | $6.24 | $0.49 | $0.97 | $3,500 | 100% | $6.24 | 0.14 |
ENT CAP SWR5 | 100 | 62.2 | $6.42 | $32.10 | $0.20 | $0.25 | $1,995 | 20% | $32.10 | 1.57 |
Table-2 TPC-C workload results various number of users across different drive configurations
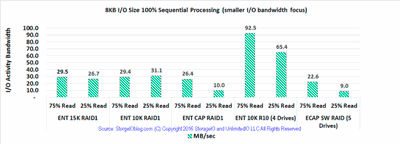
Figure-2 shows TPC-C TPS (red dashed line) workload scaling over various number of users (1, 20, 50, and 100) with peak TPS per drive shown. Also shown is the used space capacity (in green), with total raw storage capacity in blue cross hatch. Looking at the multiple metrics in context shows that the 600GB Enterprise 15K HDD with performance enhanced cache is a premium option as an alternative, or, to complement flash SSD solutions.

Figure-2 472GB Database TPS scaling along with cost per TPS and storage space used
In figure-2, the 1.8TB Enterprise 10K HDD with performance enhanced cache while not as fast as the 15K, provides a good balance of performance, space capacity and cost effectiveness. A good use for the 10K drives is where some amount of performance is needed as well as a large amount of storage space for less frequently accessed content.
A low cost, low performance option would be the 2TB Enterprise Capacity HDD’s that have a good cost per capacity, however lack the performance of the 15K and 10K drives with enhanced performance cache. A four drive RAID 10 along with a five drive software volume (Microsoft WIndows) are also shown. For apples to apples comparison look at costs vs. capacity including number of drives needed for a given level of performance.
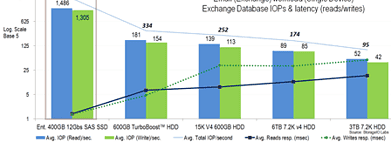
Figure-3 is a variation of figure-2 showing TPC-C TPS (blue bar) and response time (red-dashed line) scaling across 1, 20, 50 and 100 users. Once again the Enterprise 15K with enhanced performance cache feature enabled has good performance in an apples to apples RAID 1 comparison.
Note that the best performance was with the four drive RAID 10 using 10K HDD’s Given popularity, a four drive RAID 10 configuration with the 10K drives was used. Not surprising the four 10K drives performed better than the RAID 1 15Ks. Also note using five drives in a software spanned volume provides a large amount of storage capacity and good performance however with a larger drive footprint.

Figure-3 472GB Database TPS scaling along with response time (latency)
From a cost per space capacity perspective, the Enterprise Capacity drives have a good cost per GB. A hybrid solution for environment that do not need ultra-high performance would be to pair a small amount of flash SSD (10) (drives or PCIe cards), as well as the 10K and 15K performance enhanced drives with the Enterprise Capacity HDD (11) along with cache or tiering software.
(Note 10) Refer to Seagate 1200 12 Gbps Enterprise SAS SSD StorageIO lab review
(Note 11) Refer to Enterprise SSHD and Flash SSD Part of an Enterprise Tiered Storage Strategy
Where To Learn More
- Part 1 of this series – Trends and Content Applications Servers
- Part 2 of this series – Content applications server decisions and testing plans
- Part 3 of this series – Test hardware and software configuration
- Part 4 of this series – Large file I/O processing
- Part 5 of this series – Small file I/O processing
- Part 6 of this series – General I/O processing
- Part 7 of this series – How HDD continue to evolve over different generations and wrap up
- As the platters spin, HDD’s for cloud, virtual and traditional storage environments
- How many IOPS can a HDD, HHDD or SSD do?
- Hard Disk Drives (HDD) for Virtual Environments
- Server and Storage I/O performance and benchmarking tools
- Additional Server StorageIO White Papers and Lab Reports, Solutions Briefs and Profiles, Tips and Articles
- PDF White Paper version of this post
- www.thenvmeplace.com and www.thessdplace.com
Additional learning experiences along with common questions (and answers), as well as tips can be found in Software Defined Data Infrastructure Essentials book.

What This All Means
If your environment is using applications that rely on databases, then test resources such as servers, storage, devices using tools that represent your environment. This means moving up the software and technology stack from basic storage I/O benchmark or workload generator tools such as Iometer among others instead using either your own application, or tools that can replay or generate various workloads that represent your environment.
Continue reading part five in this multi-part series here where the focus shifts to large and small file I/O processing workloads.
Ok, nuff said, for now.
Gs
Greg Schulz – Microsoft MVP Cloud and Data Center Management, VMware vExpert 2010-2017 (vSAN and vCloud). Author of Software Defined Data Infrastructure Essentials (CRC Press), as well as Cloud and Virtual Data Storage Networking (CRC Press), The Green and Virtual Data Center (CRC Press), Resilient Storage Networks (Elsevier) and twitter @storageio. Courteous comments are welcome for consideration. First published on https://storageioblog.com any reproduction in whole, in part, with changes to content, without source attribution under title or without permission is forbidden.
All Comments, (C) and (TM) belong to their owners/posters, Other content (C) Copyright 2006-2026 Server StorageIO and UnlimitedIO. All Rights Reserved. StorageIO is a registered Trade Mark (TM) of Server StorageIO.