
Seagate 1200 12Gbs Enterprise SAS SSD StorgeIO lab review
This is the first post of a two part series, read the second post here.
Earlier this year I had the opportunity to test drive some Seagate 1200 12Gbs Enterprise SAS SSD’s as a follow-up to some earlier activity trying their Enterprise TurboBoost Drives. Disclosure: Seagate has been a StorageIO client and was also the sponsor of this white paper and associated proof-points mentioned in this post.
The question to ask yourself is not if flash Solid State Device (SSD) technologies are in your future, Instead the questions are when, where, using what, how to configure and related themes. SSD including traditional DRAM and NAND flash-based technologies are like real estate where location matters; however, there are different types of properties to meet various needs. This means leveraging different types of NAND flash SSD technologies in different locations in a complementary and cooperative aka hybrid way. For example nand flash SSD as part of an enterprise tiered storage strategy can be implemented server-side using PCIe cards, SAS and SATA drives as targets or as cache along with software, as well as leveraging SSD devices in storage systems or appliances.

Seagate 1200 Enterprise SAS 12Gbs SSD Image via Seagate.com
Another place where nand flash can be found and compliments SSD devices are so-called Solid State Hybrid Drives (SSHD) or Hybrid Hard Disk Drives (HHDD) including a new generation that accelerate writes as well as reads such as those Seagate refers to as with Enterprise TurboBoost. The Enterprise TurboBoost drives (view the companion StorageIO Lab review TurboBoost white paper here) were previously known as the Solid State Hybrid Drives (SSHD) or Hybrid Hard Disk Drives (HHDD). Read more about TurboBoost here and here.
The best server and storage I/O is the one you do not have to do
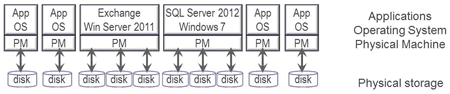
Keep in mind that the best server or storage I/O is that one that you do not have to do, with the second best being the one with the least overhead resolved as close to the processor (compute) as possible or practical. The following figure shows that the best place to resolve server and storage I/O is as close to the compute processor as possible however only a finite amount of storage memory located there. This is where the server memory and storage I/O hierarchy comes into play which is also often thought of in the context of tiered storage balancing performance and availability with cost and architectural limits.
Also shown is locality of reference which refers to how close data is to where it is being used and includes cache effectiveness or buffering. Hence a small amount of cache of flash and DRAM in the right location can have a large benefit. Now if you can afford it, install as much DRAM along with flash storage as possible, however if you are like most organizations with finite budgets yet server and storage I/O challenges, then deploy a tiered flash storage strategy.

Server memory storage I/O hierarchy, locality of reference
Seagate 1200 12Gbs Enterprise SAS SSD’s
Back to the Seagate 1200 12Gbs Enterprise SAS SSD which is covered in this StorageIO Industry Trends Perspective thought leadership white paper. The focus of the white paper is to look at how the Seagate 1200 Enterprise class SSD’s and 12Gbps SAS address current and next generation tiered storage for virtual, cloud, traditional Little and Big Data infrastructure environments.

This includes providing proof points running various workloads including Database TPC-B, TPC-E and Microsoft Exchange in the StorageIO Labs along with cache software comparing SSD, SSHD and different HDD’s including 12Gbs SAS 6TB near-line high-capacity drives.
Seagate 1200 Enterprise SSD Proof Points
The proof points in this white paper are from an applications focus perspective representing more of an end-to-end real-world situation. While they are not included in this white paper, StorageIO has run traditional storage building-block focus workloads, which can be found at StorageIOblog (Part II: How many IOPS can a HDD, HHDD or SSD do with VMware?). These include tools such as Iometer, iorate, vdbench among others for various IO sizes, mixed, random, sequential, reads, writes along with “hot-band" across different number of threads (concurrent users). “Hot-Band” is part of the SNIA Emerald energy effectiveness metrics for looking at sustained storage performance using tools such as vdbench. Read more about other various server and storage I/O benchmarking tools and techniques here.
For the following series of proof-points (TPC-B, TPC-E and Exchange) a system under test (SUT) consisted of a physical server (described with the proof-points) configured with VMware ESXi along with guests virtual machines (VMs) configured to do the storage I/O workload. Other servers were used in the case of TPC workloads as application transactional requester to drive the SQL Server database and resulting server storage I/O workload. VMware was used in the proof-points to reflect a common industry trend of using virtual server infrastructures (VSI) supporting applications including database, email among others. For the proof-point scenarios, the SUT along with storage system device under test were dedicated to that scenario (e.g. no other workload running) unless otherwise noted.

Server Storage I/O configuration for proof-points
Microsoft Exchange Email proof-point configuration
For this proof-point, Microsoft Jet Stress Exchange performance workloads were placed (e.g. Exchange Database – EDB file) on each of the different devices under test with various metrics shown including activity rates and response time for reads as well as writes. For the Exchange testing, the EDB was placed on the device being tested while its log files were placed on a separate Seagate 400GB Enterprise 12Gbps SAS SSD.
Test configuration: Seagate 400GB 12000 2.5” SSD (ST400FM0073) 12Gbps SAS, 600GB 2.5” Enterprise 15K with TurboBoost™ (ST600MX) 6 Gbps SAS, 600GB 2.5” Enterprise Enhanced 15K V4 (15K RPM) HDD (ST600MP) with 6 Gbps SAS, Seagate Enterprise Capacity Nearline (ST6000NM0014) 6TB 3.5” 7.2K RPM HDD 12 Gbps SAS and 3TB 7.2K SATA HDD. Email server hosted as guest on VMware vSphere/ESXi V5.5, Microsoft SBS2011 Service Pack 1 64 bit. Guest VM (VMware vSphere 5.5) was on a SSD based dat, had a physical machine (host), with 14 GB DRAM, quad CPU (4 x 3.192GHz) Intel E3-1225 v300, with LSI 9300 series 12Gbps SAS adapters in a PCIe Gen 3 slot with Jet Stress 2010. All devices being tested were Raw Device Mapped (RDM) where EDB resided. VM on a SSD based separate data store than devices being tested. Log file IOPs were handled via a separate SSD device also persistent (no delayed writes). EDB was 300GB and workload ran for 8 hours.

Microsoft Exchange proof-points comparing various storage devices
TPC-B (Database, Data Warehouse, Batch updates) proof-point configuration
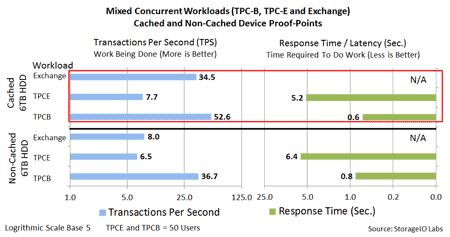
SSD’s are a good fit for both transaction database activity with reads and write as well as query-based decision support systems (DSS), data warehouse and big data analytics. The following are proof points of SSD capabilities for database activity. In addition to supporting database table files and objects, along with transaction journal logs, other uses include for meta-data, import/export or other high-IO and write intensive scenarios. Two database workload profiles were tested including batch update (write-intensive) and transactional. Activity involved running Transaction Performance Council (TPC) workloads TPC-B (batch update) and TPC-E (transaction/OLTP simulate financial trading system) against Microsoft SQL Server 2012 databases. Each test simulation had the SQL Server database (MDF) on a different device with transaction log file (LDF) on a separate SSD. TPC-B for a single device results shown below.
TPC-B (write intensive) results below show how TPS work being done (blue) increases from left to right (more is better) for various numbers of simulated users. Also shown on the same line for each amount of TPS work being done is the average latency in seconds (right to left) where lower is better. Results are shown from top to bottom for each group of users (100, 50, 20 and 1) for the different drives being tested (top to bottom). Note how the SSD device does more work at a lower response time vs. traditional HDD’s
Test configuration: Seagate 400GB 12000 2.5” SSD (ST400FM0073) 12Gbps SAS, 600GB 2.5” Enterprise 15K with TurboBoost™ (ST600MX) 6 Gbps SAS, 600GB 2.5” Enterprise Enhanced 15K V4 (15K RPM) HDD (ST600MP) with 6 Gbps SAS, Seagate Enterprise Capacity Nearline (ST6000NM0014) 6TB 3.5” 7.2K RPM HDD 12 Gbps SAS and 3TB Seagate 7.2K SATA HDD Workload generator and virtual clients Windows 7 Ultimate 64 bit. Microsoft SQL Server 2012 database was on Windows 7 guest. Guest VM (VMware vSphere 5.5) had a dedicated 14 GB DRAM, quad CPU (4 x 3.192GHz) Intel E3-1225 v300, with LSI 9300 series 12Gbps SAS adapters in a PCIe Gen 3 slot along with TPC-B (www.tpc.org) workloads.
VM with guest OS along with SQL tempdb and masterdb resided on separate SSD based data store from devices being tested (e.g., where MDF (main database tables) and LDF (log file) resided). All devices being tested were Raw Device Mapped (RDM) independent persistent with database log file on a separate SSD device also persistent (no delayed writes) using VMware PVSCSI driver. MDF and LDF file sizes were 142GB and 26GB with scale factor of 10000, with each step running for one hour (10-minute preamble). Note that these proof-points DO NOT use VMware or any other third-party cache software or I/O acceleration tool technologies as those are covered later in a separate proof-point.

TPC-B SQL Server database proof-points comparing various storage devices
TPC-E (Database, Financial Trading) proof-point configuration
The following shows results from TPC-E test (OLTP/transactional workload) simulating a financial trading system. TPC-E is an industry standard workload that performs a mix of reads and writes database queries. Proof-points were performed with various numbers of users from 10, 20, 50 and 100 to determine (TPS) Transaction per Second (aka I/O rate) and response time in seconds. The TPC-E transactional results are shown for each device being tested across different user workloads. The results show how TPC-E TPS work (blue) increases from left to right (more is better) for larger numbers of users along with corresponding latency (green) that goes from right to left (less is better). The Seagate Enterprise 1200 SSD is shown on the top in the figure below with a red box around its results. Note how the SSD as a lower latency while doing more work compared to the other traditional HDD’s
Test configuration: Seagate 400GB 12000 2.5” SSD (ST400FM0073) 12Gbps SAS, 600GB 2.5” Enterprise 15K with TurboBoost™ (ST600MX) 6 Gbps SAS, 600GB 2.5” Enterprise Enhanced 15K V4 (15K RPM) HDD (ST600MP) with 6 Gbps SAS, Seagate Enterprise Capacity Nearline (ST6000NM0014) 6TB 3.5” 7.2K RPM HDD 12 Gbps SAS and 3TB Seagate 7.2K SATA HDD Workload generator and virtual clients Windows 7 Ultimate 64 bit. Microsoft SQL Server 2012 database was on Windows 7 guest. Guest VM (VMware vSphere 5.5) had a dedicated 14 GB DRAM, quad CPU (4 x 3.192GHz) Intel E3-1225 v300, with LSI 9300 series 12Gbps SAS adapters in a PCIe Gen 3 slot along with TPC-B (www.tpc.org) workloads.
VM with guest OS along with SQL tempdb and masterdb resided on separate SSD based data store from devices being tested (e.g., where MDF (main database tables) and LDF (log file) resided). All devices being tested were Raw Device Mapped (RDM) independent persistent with database log file on a separate SSD device also persistent (no delayed writes) using VMware PVSCSI driver. MDF and LDF file sizes were 142GB and 26GB with scale factor of 10000, with each step running for one hour (10-minute preamble). Note that these proof-points DO NOT use VMware or any other third-party cache software or I/O acceleration tool technologies as those are covered later in a separate proof-point.

TPC-E (Financial trading) SQL Server database proof-points comparing various storage devices
Continue reading part-two of this two-part series here including the virtual server storage I/O blender effect and solution.
Ok, nuff said (for now).
Cheers gs
Greg Schulz – Author Cloud and Virtual Data Storage Networking (CRC Press), The Green and Virtual Data Center (CRC Press) and Resilient Storage Networks (Elsevier)
twitter @storageio
All Comments, (C) and (TM) belong to their owners/posters, Other content (C) Copyright 2006-2026 Server StorageIO and UnlimitedIO LLC All Rights Reserved





































{kind=link}