Ten tips to reduce your cloud compute storage costs #blogtobertech

The following are Ten tips to reduce your cloud compute storage costs.
In some cases, reducing your cloud costs means spending the same yet getting more value and resources that provide a business benefit. For example, paying the same yet upgrading to fewer, faster servers, storage, I/O network resources to support growth while boosting productivity. In other words, when measured on a cost per unit of work done or service enabled, there should be an improvement.
On the other hand, cost cutting can be measured by an actual reduction in spending, for example, consolidating multiple applications to a lower cost compute instance running at higher utilization. The caveat is that while the spend may be reduced, is the corresponding level of service or application and user productivity negatively impacted?
Other examples are a hybrid of removing complexity and cost, as well as cost-cutting, for instance finding orphan resources that are powered on and not used. Orphan resources include IP addresses assigned, being charged for yet not used, or a virtual machine instance powered on however not used. Another orphan example is a VM instance that is powered off however no longer used, nor are the disks assigned to it, as well as any snapshots or backups.
Ten tips to reduce your cloud costs
- Utilize client and remote site data file cache to reduce cloud egress network fees
- Bring your own software licenses for operating systems and applications
- Monitor your cloud cost summaries regularly to watch out for surprises
- Find and remove orphan resources including instances, images, IP address, storage volumes, buckets
- Revisit if your data is stored in the appropriate storage class or tier for how it is used. Likewise, leverage lower durable storage tiers as locations for additional protection instead of merely as a single destination to support cost-cutting. For example, cost cutting would be placing your only data protection copy and archive on a lower cost lower durable storage tier. Removing cost, boosting availability would be putting a copy of your data on two or more economical price, less durable storage tiers in different locations, instead of a single copy on a highly durable tier in one place.
- Consolidate many smaller, lower cost instances into fewer larger instances, removing complexity and costs
- Utilize reserved instances (RI) along with prepayment discounts, also check with your finance department to see if there are benefits of considering as OpEx or CapEx.
- Audit your RIs to make sure you have the appropriately sized resources to meet workload needs.
- Utilize spot instances for spot or ad-hoc interruptible workloads
- Leverage ephemeral on-instance storage as a cache to boost performance
Additional Tips and Recommendations
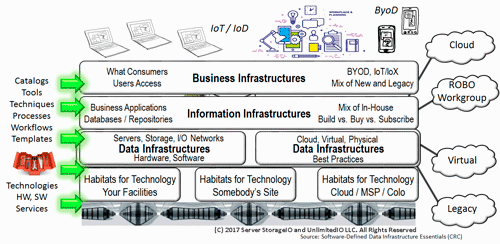
Everything is not the same, why treat everything the same including assigning to the same type of resources. Keep in mind that all applications have some level of Performance, Availability, Capacity, and Economic (PACE) resource requirements that need to be balanced.
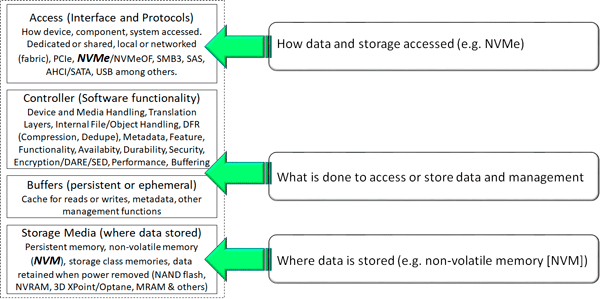
Similar to on-prem environments, one of the top mistakes when choosing storage is looking only at a cost per capacity, particular with flash-based SSD and NVMe accessed storage. Also look into what the storage performance thresholds are, as well as any access and API or service call fees.
Watch out for excessive API and cloud service calls beyond your normal monthly limits. For example, consistently running rsync on some storage classes can result in surprise monthly invoices. Likewise, moving data around, changing encryption or other operations may wipe out savings from going to a lower storage tier. Look beyond the monthly cost per capacity, what are the access including egress (reading data) fees, as well as API calls such as list, dir or other operations.
Likewise, for compute instances, look beyond the necessary cost also considering how much memory (DRAM), I/O for storage and networking, on-instance storage (temporary or persistent), bring your own license options, number of cores or virtual CPUs along with their speed. Also, watch for any limits on the number of I/O operations per instance particular with fast flash SSD including NVMe accessed storage. Just because its flash or NVMe does not mean it’s going to be fast.
Where to learn more
Learn more about Clouds and Data Infrastructure related trends, tools, technologies and topics via the following links:
- Cloud File Data Storage Consolidation and Economic Comparison Model
- Not Dead Yet Zombie Technology (Declared Dead yet still alive) October 2018 Update
- Application Data Value Characteristics Everything Is Not the Same (Part I)
- PACE your Server Storage I/O decision-making, it’s about application requirements
- What is DFR or Data Footprint Reduction?
- How I saved money storing more data on aws s3 simple storage service
- Cloud conversations: confidence, certainty, and confidentiality
- Cloud conversations: AWS EBS, Glacier and S3 overview (Part I)
- Server Storage I/O Network Virtualization Whats Next?
- Cloud Conversations AWS Azure Service Maps via Microsoft
- AWS S3 Storage Gateway Revisited (Part I)
- Cloud Conversations: AWS S3 Cross Region Replication storage enhancements
- Cloud conversations: AWS EBS, Glacier and S3 overview (Part II S3)
- Pictures Over Stillwater Drone Pro Shop and Resource Links
- 2018 Hot Popular New Trending Data Infrastructure Vendors to Watch
- Part 1 – Application Data Value Characteristics Everything Is Not The Same
- Data Infrastructure server storage I/O network Recommended Reading
- World Backup Day 2018 Data Protection Readiness Reminder
- Data Infrastructure Server Storage I/O related Tradecraft Overview
- Data Infrastructure Server Storage I/O Tradecraft Trends
- Data Infrastructure Overview, Its What’s Inside of Data Centers
- 4 3 2 1 and 3 2 1 data protection best practices
- Garbage data in, garbage information out, big data or big garbage?
- GDPR (General Data Protection Regulation) Resources Are You Ready?
- Which Enterprise HDD to use for a Content Server Platform
- The SSD Place (SSD, NVM, PM, SCM, Flash, NVMe, 3D XPoint, MRAM and related topics)
- The NVMe Place (NVMe related topics, trends, tools, technologies, tip resources)
- Data Protection Diaries (Archive, Backup/Restore, BC, BR, DR, HA,Replication, Security)
- If NVMe is the answer, what are the questions?
- NVMe Primer (or refresh), The NVMe Place, The SSD Place, and the Object Storage Center
Additional learning experiences along with common questions (and answers), as well as tips can be found in Software Defined Data Infrastructure Essentials book.

What this all means
Have a situational awareness of your on-prem environment knowing your costs of resources as well as the level of services to make informed decisions. Don’t be scared, be prepared, avoid flying blind, plan ahead and apply the appropriate resources along with quantity to require application workload needs. Keep in mind that there are more than Ten tips to reduce your cloud compute storage costs, however these should get your off to a good start.
Ok, nuff said, for now.
Cheers Gs
Greg Schulz – Microsoft MVP Cloud and Data Center Management, VMware vExpert 2010-2018. Author of Software Defined Data Infrastructure Essentials (CRC Press), as well as Cloud and Virtual Data Storage Networking (CRC Press), The Green and Virtual Data Center (CRC Press), Resilient Storage Networks (Elsevier) and twitter @storageio. Courteous comments are welcome for consideration. First published on https://storageioblog.com any reproduction in whole, in part, with changes to content, without source attribution under title or without permission is forbidden.
All Comments, (C) and (TM) belong to their owners/posters, Other content (C) Copyright 2006-2026 Server StorageIO and UnlimitedIO. All Rights Reserved. StorageIO is a registered Trade Mark (TM) of Server StorageIO.