Not Dead Yet Zombie Technology (Declared Dead yet still alive) October 2018 Update #blogtobertech

Not Dead Yet Zombie Technology (Declared Dead yet still alive) October 2018 Update. Musician Phil Collins has an excellent name for his current tour Not Dead Yet which is a reminder that he is still alive and performing, at least one more time. With Halloween just around the corner, it is that time of the year to revisit zombie technology, those technologies, tools, techniques, trends that are declared dead yet still alive.
IT Zombie Technology Declared Dead Not Dead Yet
With a concert tour named Not Dead Yet, that sets the stage for this post which is about IT Zombie Technology and in particular data infrastructure related technology, tools, trends and related topics that have been declared dead by some people, yet are still alive. Not only are these tools and techniques being used, but they are also being enhanced to be around for future years of zombie technology updates, not dead yet.
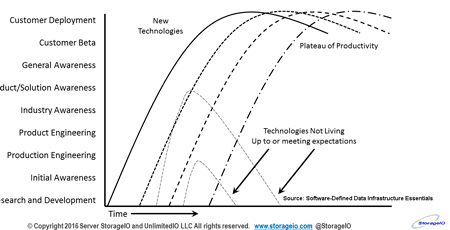
As a refresher, a Zombie technology is one that is declared dead, usually by some upstart vendor and its pundits along with other followers in favor of whatever new has been announced. As luck or fate would have it, some of these startup or new technologies that declare an older established one as being dead, tend to end up on the where are they now list.
In other words, some technologies do survive and gain in both industry adoption, as well as the even more critical customer deployment category. Likewise, some of these technologies that result in something existing being declared dead-end up surviving to live alongside or near what its supporters declared dead.
Another not so uncommon occurrence is when the new technology that its supporters declared something else as being dead joins the ranks of being declared dead by a yet more modern technology thereby becoming a Zombie technology itself. Put a different way, being on the Zombie technology list may not be the same as being the shiny new popular trendy technology. However, it can be both a badge of honor not to mention revenue and profit maker.
Zombie Technology List
What are some old and new Zombie technologies that have been declared dead, yet are still alive, being used and enhanced, not dead yet?
IBM Mainframe
This is a perennial favorite, and while not seeing new growth associated with other platforms including Intel, AMD, ARM among others, it has its place with many large organizations. Not only does it continue to be manufactured, enhanced, even some new customers buying them, it also runs native Linux in addition to traditional zOS among other software.
Fibre Channel (FC)
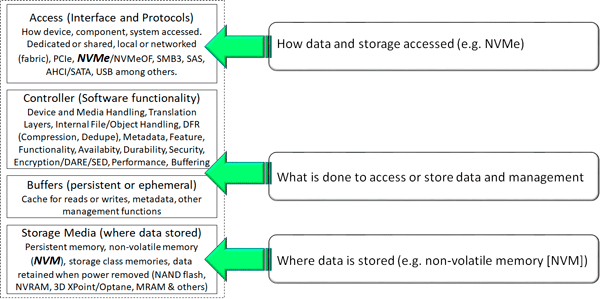
FC has been declared dead for over a decade, and while Ethernet-based server storage I/O networking continues to gain ground in both industry as well as customer deployments, there is still plenty of life in and with FC for years to come, at least for some environments. NVMe over Fabrics (NVMeoF) which is the NVMe protocol carried on top of a fabric network (SAN if you prefer) is gaining industry popularity and customer curiosity.
There are many flavors of NVMe over fabrics including NVMe over Fibre Channel, e.g., FC-NVMe which is similar to mapping the SCSI command set (SCSI_FCP) on to Fibre Channel or what is more commonly known as FCP or simply FC.
What this means if that FC-NVMe is just another upper-level protocol (ULP) that can co-exist with others on the same Fibre Channel network. In other words, FICON, FCP, NVMe among others can co-exist on the same Fibre Channel-based network. Will everybody using Fibre Channel move to FC-NVMe? Good question, ask the FC folks, and the answer not surprisingly would be yes or probably. Will new customers looking to do NVMe over some type of fabric or network use Fibre Channel instead of Ethernet or other transport? Some will while others will go other routes. For now, what is clear is that FC is still alive and thus on the Zombie technology list and not dead yet.
SAS and SATA
Both have been declared dead as they have been around for a while, and over time NVMe will pick up more of their workload, however near term, SAS and SATA will continue as lower cost smaller footprint for general purpose and bulk lower cost direct attachment. Otoh, look for more m.2 NVMe Next Generation Form Factor (NGFF) aka gum sticks appearing on physical servers along with storage systems. Likewise, watch for increased deployment of NVMe U.2. Aka 8639 drive form factor SSDs using NAND flash as well as 3D XPoint and Intel Optane among other mediums as part of new server and storage platforms. BTW, USB is not dead yet either, just saying.
Microsoft Windows
Windows desktop, Windows Servers, even Hyper-V virtualization have been declared dead for some time now, yet all continue to evolve. Just recently, Microsoft released Windows Server 2019 which included many enhancements from software-defined storage (Storage Spaces Direct aka S2D), software-defined networking, converged and hyper-converged infrastructure (HCI) deployment options, expanded virtualization capabilities, Windows Subsystem for Linux (WSL) enhancements (e.g. bash shell on Windows native), containers with Kubernetes as well as Docker updates among others. In other words, it’s not dead yet.
Hard Disk Drive (HDD)
Having been declared dead for decades, while not the primary frontline storage medium it was in the past, HDDs continue to evolve and be used for alongside faster flash SSD, and as a front-end to magnetic tape. Some of the larger consumers of HDDs continue to be cloud service providers also known as mega scalars for storing large amounts of bulk data. I suspect that HDDs will continue to be on the Zombie technology list for at least another decade or so which has been the case for the past several decades.
Magnetic Tape
Like HDDs, the tape is still in use in some environments, and like HDDs, the cloud service providers are significant users of tape as a low-cost, low access, high-capacity bulk storage for cold archives that are front-ended by HDD or SSD or both.
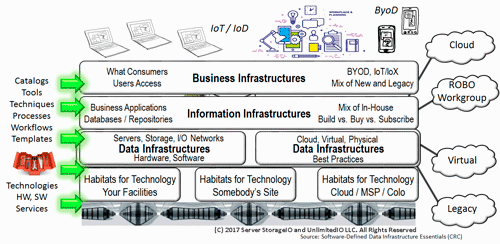
Cloud (Public, Private and Hybrid)
Yes, believe it or not, some have declared cloud dead, along with hybrid cloud, private cloud among others, oh well.
Physical Machine (PM)
Also known as bare metal, servers were declared dead a decade or so ago at the hands of the then emerging Intel based virtualization hypervisors notably VMware ESXi and to a lesser extent Microsoft Hyper-V. I say lesser extent with Hyper-V in that there was less noise about PM and BMs being dead as there was from some in the ESXi virtual kingdom. Needless to say, PM and BM from Intel to AMD and ARM-based, along with IBM Power among many others are very much alive as dedicated servers in the cloud, VM and container hosts, as well as being accessorized with FPGA, ASIC, GPU, and other resources.
Virtual Machines
Listen to some from the container, serverless or something new crowd, and you will hear that virtual machines (VMs) are dead which for some workloads may be right. On the other hand, similar to the physical machine (PM) or bare metal (BM) servers that were declared dead by the VMs a decade or so ago, VMs are alive and doing well. Not only are they doing well, like containers continued adoption and deployment of VMs will stay on both on-prem as well as cloud, as will BM and PMs now have known as dedicated servers in the clouds.
NAS and Files
If you listened to some of the pundits and press, NAS and files were supposed to have been dead several years ago at the hands of object storage. The reality today is that while object storage continues to grow in customer deployments while the industry is not as enamored (or drunk) with it as it was a few years ago, the new technology is here to stay and will be around for many decades to come.
That brings us back to NAS and files which were declared dead by the object opportunists which is file access is very much alive and continues gain ground. In fact, most cloud providers have either added NAS file-based access (NFS, SMB, POSIX among others) native or via partners to their solutions. Likewise, most object storage platforms have also added or enhanced their NAS file-based access for compatibility while their customers are re-engineering their applications, or create new apps that are object and blob native. Thus, NAS and File-based access are proud members of the Zombie technology list.
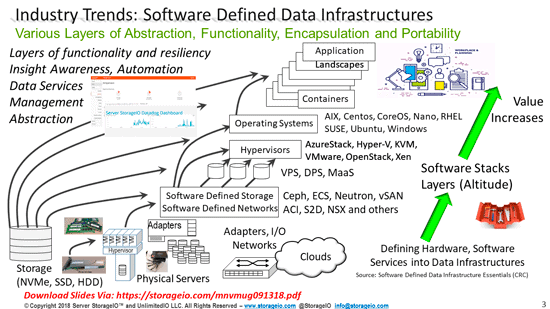
There are many more tools, technologies, trends, techniques that are part of the above list for example Backup has been declared dead, along with the PCIe bus, NAND flash, programming, data centers, databases, SQL along with many others. What they have in common is that they are part of a growing list of not dead yet, yet declared dead thus are Zombie technologies.
Where to learn more
Learn more about Clouds and Data Infrastructure related trends, tools, technologies and topics via the following links:
- Cloud File Data Storage Consolidation and Economic Comparison Model
- Application Data Value Characteristics Everything Is Not the Same (Part I)
- PACE your Server Storage I/O decision-making, it’s about application requirements
- What is DFR or Data Footprint Reduction?
- Cloud conversations: confidence, certainty, and confidentiality
- Trick or treat: 2011 IT Zombie technology poll
- Buzzword Bingo and Acronym Update V2.011
- Trick or treat: Have you seen any IT Frankenstacks
- Industry adoption vs. industry deployment, is there a difference?
- The blame game: Does cloud storage result in data loss?
- Trick or treat and vendor fun games
- Trick or Treat – Either way, Be Safe!
- Welcome to the Data Protection Diaries
- Next Generation Hybrid Software Defined Data Infrastructures Are In Your Future #blogtobertech
- Ten tips to reduce your cloud compute storage costs #blogtobertech
- Don’t Stop Learning Expand Your Skills Experiences Everyday #blogtobertech
- Data Infrastructure server storage I/O network Recommended Reading
- Data Infrastructure Server Storage I/O Tradecraft Trends
- Data Infrastructure Overview, Its What’s Inside of Data Centers
- Which Enterprise HDD to use for a Content Server Platform
- The SSD Place (SSD, NVM, PM, SCM, Flash, NVMe, 3D XPoint, MRAM and related topics)
- The NVMe Place (NVMe related topics, trends, tools, technologies, tip resources)
- Data Protection Diaries (Archive, Backup/Restore, BC, BR, DR, HA,Replication, Security)
- If NVMe is the answer, what are the questions?
- NVMe Primer (or refresh), The NVMe Place, The SSD Place, and the Object Storage Center
Additional learning experiences along with common questions (and answers), as well as tips can be found in Software Defined Data Infrastructure Essentials book.

What this all means
What is your favorite zombie technology, tool, trend or technique?
What zombie technologies, tools, trends or techniques should be added to the list and why?
Many tools, technologies, techniques, trends are often declared dead, sometimes before they are even really alive and mature by those who have something new, or that simply lack creative (e.g., dead marketing?) so it’s easier to declare something dead. While some succeed themselves prospering and being added to the Zombie technology list (a badge of honor), some quietly end up on the where are they now list. The where are they now list are those vendors, tools, technologies, techniques, trends that were on the famous hit parade in the past, having faded away, or end up dead (unlike a zombie).
Don’t be scared of zombie technology while also being prepared to embrace what is new while using both in new ways. Right now, I don’t have tickets to go see Phil Collins not dead yet tour, maybe that will change. However, for now, keep in mind, don’t be scared when looking at Not Dead Yet Zombie Technology (Declared Dead yet still alive) October 2018 Update #blogtobertech.
Ok, nuff said, for now.
Cheers Gs
Greg Schulz – Microsoft MVP Cloud and Data Center Management, VMware vExpert 2010-2018. Author of Software Defined Data Infrastructure Essentials (CRC Press), as well as Cloud and Virtual Data Storage Networking (CRC Press), The Green and Virtual Data Center (CRC Press), Resilient Storage Networks (Elsevier) and twitter @storageio. Courteous comments are welcome for consideration. First published on https://storageioblog.com any reproduction in whole, in part, with changes to content, without source attribution under title or without permission is forbidden.
All Comments, (C) and (TM) belong to their owners/posters, Other content (C) Copyright 2006-2026 Server StorageIO and UnlimitedIO. All Rights Reserved. StorageIO is a registered Trade Mark (TM) of Server StorageIO.