May 2018 Server StorageIO Data Infrastructure Update Newsletter

Volume 18, Issue 5 (May 2018)
Hello and welcome to the May 2018 Server StorageIO Data Infrastructure Update Newsletter.
In cased you missed it, the April 2018 Server StorageIO Data Infrastructure Update Newsletter can be viewed here (HTML and PDF).
May has been a busy month with a lot of data infrastructure related activity from software-defined virtual, cloud, container, converged, serverless to legacy, hardware, software, services, server, storage, I/O and networking along with data protection topics among others.
In this issue buzzwords topics include GDPR, NVMe, NVMeoF, Composable, Serverless, Data Protection, SCM, Gen-Z, MaaS:
Enjoy this edition of the Server StorageIO Data Infrastructure update newsletter.
Cheers GS
May has been a busy month, some data infrastructure, server, storage, I/O network, hardware, software, cloud, converged, and container as well as data protection activity includes among others:
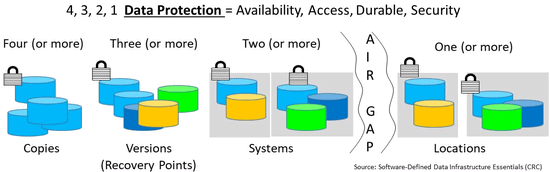
Depending on when you read this, the new global data protection regulations (GDPR) are either days away, or already in effect. For those who are not aware of GDPR other than seeing many inbox items in your email pertaining to it, here are some resources as a refresher or primer:
May Buzzword, Buzz Topic and Trends
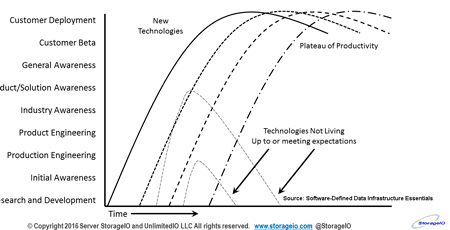
Besides data protection and GDPR, other recent data infrastructure related news, trends, technologies and topics to keep an eye on (besides AI, ML, DL, AR/VR, IoT, Blockchain, Serverless) include Metal as a Service (MaaS) that might be familiar to some, for others, something new. Canonical has been busy for sometime now with MaaS including in Ubuntu and they are not alone with variations appearing with various managed service providers, hosting and cloud providers as well. NVMe has become a more common topic, technology, trend including for use in servers as well as over fabrics (e.g. NVMe over Fabrics) as a language for server, storage, I/O communication.
A new emerging companion to NVMe is Gen-Z which initially is a companion to PCIe. Longer term, Gen-Z could maybe possibly be a replacement, as well as for use accessing direct random access memory (DRAM) among other uses. Storage Class Memory (SCM) has been an industry conversation topic for several years now with new persistent memories (PMEM) that combine the best of traditional DRAM (Speed and write endurance) as well as persistent, higher capacity, lower cost of traditional NAND flash SSDs.
Another trend topic is that for some, ASIC, FPGA and GPU are new companions to standard commodity compute processors along with servers, yet for others it may be Dejavu as they have been being used for years (ok, decades) in some solutions. For now, two other buzzwords, buzz terms to add or refresh your data infrastructure vocabulary include distributed ledgers (aka blockchains), composable resources and ephemeral instance storage (storage on a cloud instance).
May NVMe Momentum Movement Activity
May saw a lot of NVMe related activity, from chips and components (adapters, devices) to systems spanning direct attached to NVMe over Fabric (NVMeoF). Here is a primer (or refresh) for NVMe along with various deployment options. NVMeoF includes RDMA over Converged Ethernet (RoCE) based, along with NVMe over Fibre Channel (FC-NVMe), as well as emerging NVMe over IP.
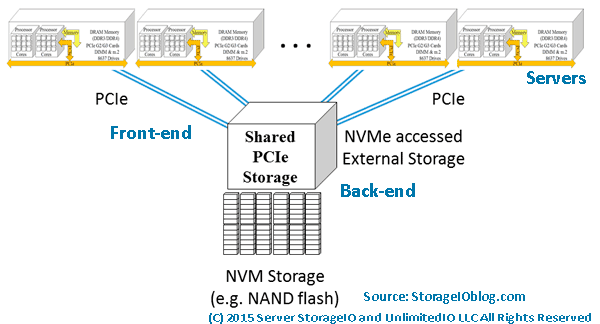
NVMe being used for front-end accessed via shared PCIe along with back-end devices
There are many different facets of NVMe including for use as a front-end on storage systems supporting server attachment (e.g. competes with Fibre Channel, iSCSI, SAS among others). Another variation of NVMe is as a back-end for attachment of drives or other NVMe based devices in storage systems, as well as servers.
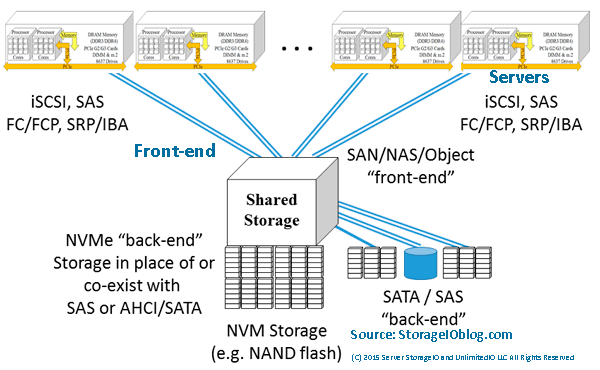
Front-end using traditional block SAN access with back-end NVMe, SAS and SATA devices
Read more about the many different options and variations of NVMe including key questions to ask or understand, deployment topology along with other related topics at thenvmeplace.com.
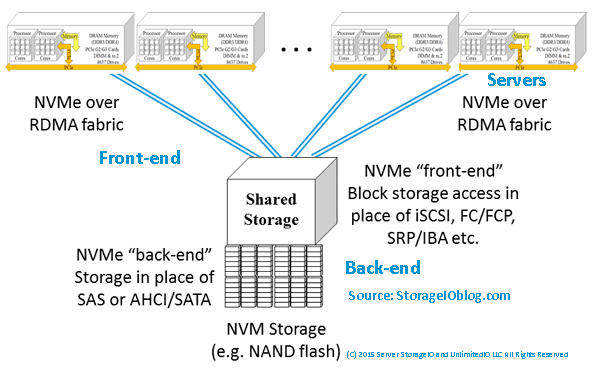
Various NVMe front-end including NVMeoF along with NVMe back-end devices (U.2, M.2, AiC)
Software Defined Data Infrastructure Activity
Amazon Web Services (AWS) continues to add new features, functionality as well as extending those as along with existing capabilities into various regions. Some recent updates include new Elastic Cloud Compute (EC2) Microsoft Windows Servers versions 1709 and 1803 Amazon Machine Images (AMIs). Other AWS updates include spot instances support for Red Hat BYOL (Bring Your Own License), VPN enhancements, X1e instances available in Frankfurt, H1 instance price reduction, as well as LightSail now in Canada, Paris, and Seoul regions.
For those who are not familiar with LightSail, they are virtual private servers (VPS) which are different from traditional EC2 instances. LightSail can be a cost-effective way for those who need to move out of general population shared hosting, yet cannot justify a full EC2 instance while requiring more than a container.
The LightSail instance also is available with various software pre-installed such as for WordPress websites among others. For example, I have used LightSail as a backup and standby WordPress site for StorageIOblog using Updraft Plus Pro for data protection.
In other news, AWS C5d EC2 instances are available in various regions. C5d instances are available with 2, 4, 8, 16, 36 and 72 vCPUs along with up to 1800GB of NVMe based ephemeral storage for on-demand reserved or spot instances.
Note that instance-based storage is temporary meaning that it persists for the life of the instance. What this means is that if you stop and restart the instance, the data is not persistence. Instance-based storage is useful for data that can be protected or persisted to other storage including EBS (Elastic Block Storage). Usage includes batch, log and analytics processing, burst buffers, cache or workspace.
AWS also announced a new Simple Storage Service (S3) storage class a month or so ago called One Zone Availability Infrequent Access. This new storage class primarily provides a lower cost of storage with lower durability (e.g., data spread across one zone vs. multiple). Over the past couple of months, I have been migrating from S3 Infrequent Access (IA) as well as standard into One Zone Availability. Some of my active data remains in S3 Standard storage class, while cold archives are in Glacier.
A tip about migrating to One Zone Availability, as well as between other S3 storage classes is paid attention to your API calls and monthly budget. You might see an increase in S3 costs during the migration time, that then settles into the lower prices once data has been moved due to API calls (gets, puts, lists, dir). In other words, pay attention to how many API calls you are allowed per storage class per month, along with other fees beyond focusing only on cost per TByte. Read about other recent AWS news updates here.
Software-defined storage startup Cloudian announced their technology available for test drive on Google Cloud Platform as part of a continued industry trend. That trend is for storage vendors to make their storage software technology available on different cloud platforms such as AWS, Azure, Google, Softlayer among others.

Dell Technologies made several announcements as part of Dell Technologies World that are covered in a series of posts here. Announcements included PowerMax the successor to VMAX, XtremIO X2 updates, new servers, workstations among many other items, read more here.
Besides the data infrastructure, cloud service providers and systems vendors, component suppliers including Cavium announced NVMe over Fibre Channel updates (here and here), along with Marvel NVMe updates here. HPE announced new thin clients and software (t430 Thin Client, HP mt44 Mobile Thin Client, HP ThinPro software), as well as updates to 3PAR and other storage solutions.
IBM announced various storage enhancements (and here) as well as a Happy 30th anniversary to the IBM Power9 based i systems. In other news, Kaseya bought backup data protection vendor Unitrends.

Micron announced the first quad layer cell (QLC) nand flash solid state device (SSD) named 52100 has begun shipping to select customers (and vendors). QLC packs or stacks 4 bits per cell. The 5200 is optimized for read-intensive workloads with up to 33% higher densities compared to previous generation TLC (triple layer cell) NAND flash. Broader market availability is expected to occur later fall 2018, 5210 form factor is 2.5” as a standard SSD or HDD, with capacities from 1.92TB to 7.68TB.
In other news, Micron also announced a $10 Billion (USD) stock repurchase plan, along with an extension of Intel 3D NAND flash memory partnership involving 3D NAND flash, as well as 96 layer 3D NAND. Meanwhile, various vendors are increasingly talking about how their systems are or will be storage class memory (SCM) ready including for use such as Micron 3D XPoint also known as Intel Optane among others.
Microsoft has placed into public preview Azure Active Directory (AAD) Storage authentication for Azure Blobs and Queues. Azure Storage Explorer is now released as version 1.0. AAD storage authentication enables organizations to implement role-based access control of Azure storage resources. Speaking of Azure, Microsoft has published several architectures, reference and other content at the Azure Virtual Datacenter portal here.
If you have not done so, check out Azure File Sync which is currently in public preview. Having been involved and using it for over a year including during private preview, Azure File Sync is an exciting, useful technology for creating a hybrid distributed file sharing with cloud tiering solutions. Learn more Azure File Sync here and here. In other news, Microsoft has announced a preview as part of the April 2018 Windows 10 build for a Hyper-V Google Android emulator support.
NetApp has had Azure based NAS storage in preview for a while now, and also announced Cloud Volumes on Google Cloud Platform (GCP). In addition to Cloud Volumes on AWS, Azure, and GCP, NetApp also announced enhanced NVMe based storage systems among other updates.
Two companies that have similar names are Opendrives (video workflow acceleration) and Opendrive (cloud storage, backup, and data protection). Meanwhile, data infrastructure startup Pavilion has received new funding as well as begun talking about their NVMe including NVMe over Fabric (NVMeOF) hardware storage system. Long-time data infrastructure converged server storage startup Pivot3 announced additional cloud workload mobility.
Pure storage made a couple of announcements including FlashArray//X NVMe based shared accelerated storage system as well as NVIDIA (GPU powered) based AIRI Mini for AI/DL/ML.
Have you heard about Snowflake computing, aka, the cloud data warehouse solution? If not, check them out here. Another cloud-related data infrastructure vendor to look into is Upbound.io who have received additional funding for their multi-cloud management solutions.
Building off of recent VMware vSphere updates (here), and Dell Technology World here, the following is an excellent post about Instant Clone in vSphere 6.7, and VMware vSAN HCI assessment tool here.
Check out other industry news, comments, trends perspectives here.

Recent Server StorageIO industry trends perspectives commentary in the news.
Via SearchStorage: Comments Managing storage for IoT data at the enterprise edge
Via SearchCloudComputing: Comments Hybrid cloud deployment demands a change in security mindset
Via SearchStorage: Comments Dell EMC storage IPO, VMware merger plans still unclear
Via SearchStorage: Comments Dell EMC midrange storage keeps its overlapping arrays
Via SearchStorage: Comments Dell EMC all-flash PowerMax replaces VMAX, injects NVMe
Via IronMountain InfoGoto: The growing Trend of Secondary Data Storage
View more Server, Storage and I/O trends and perspectives comments here.
Recent and popular Server StorageIOblog posts include:
Dell Technology World 2018 Announcement Summary
Part II Dell Technology World 2018 Modern Data Center Announcement Details
Part III Dell Technology World 2018 Storage Announcement Details
Part IV Dell Technology World 2018 PowerEdge MX Gen-Z Composable Infrastructure
Part V Dell Technology World 2018 Server Converged Announcement Details
April 2018 Server StorageIO Data Infrastructure Update Newsletter
VMware vSphere vSAN vCenter version 6.7 SDDC Update Summary
PCIe Fundamentals Server Storage I/O Network Essentials
Have you heard about the new CLOUD Act data regulation?
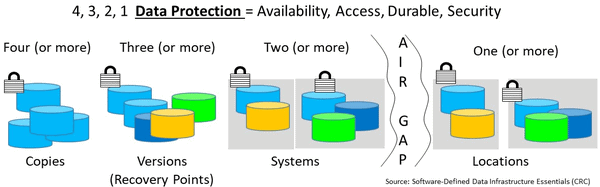
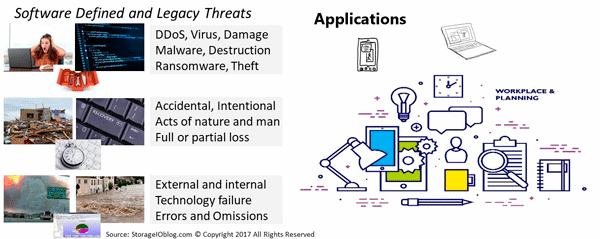
Data Protection Recovery Life Post World Backup Day Pre GDPR
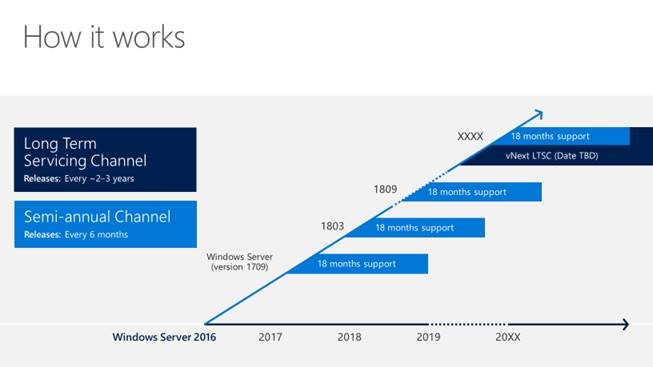
Microsoft Windows Server 2019 Insiders Preview
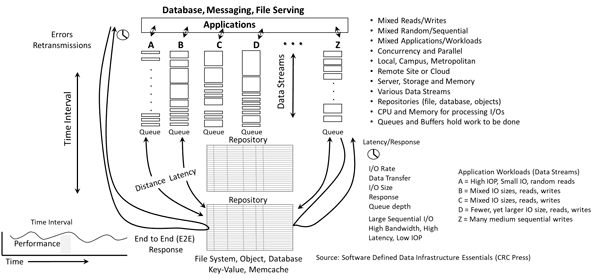
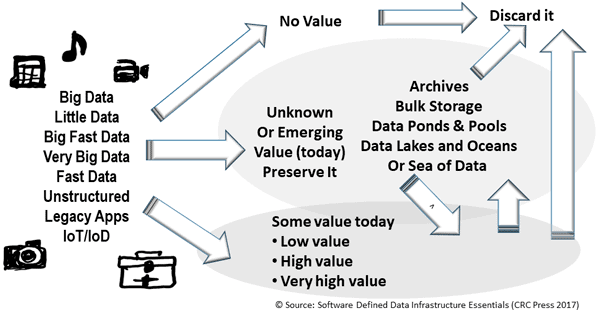
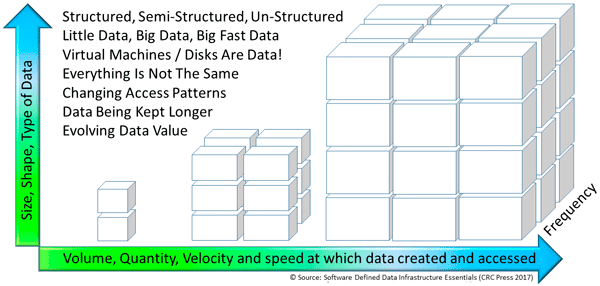
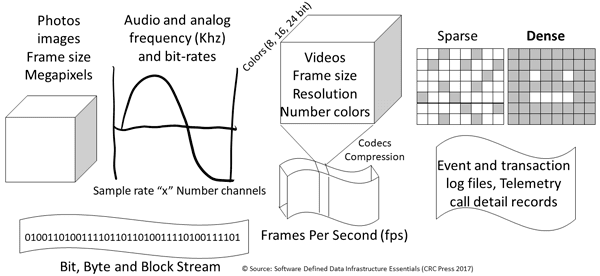
Application Data Value Characteristics Everything Is Not The Same
Data Infrastructure Resource Links cloud data protection tradecraft trends
IT transformation Serverless Life Beyond DevOps Podcast
Data Protection Diaries Fundamental Topics Tools Techniques Technologies Tips
Introducing Windows Subsystem for Linux WSL Overview
Data Infrastructure Primer Overview (Its Whats Inside The Data Center)
If NVMe is the answer, what are the questions?
View other recent as well as past StorageIOblog posts here

In addition to my own books including Software Defined Data Infrastructure Essentials (CRC Press 2017) available at Amazon.com (check out special sale price), the following are Server StorageIO data infrastructure recommended reading, watching and listening list items. The Server StorageIO data infrastructure recommended reading list includes various IT, Data Infrastructure and related topics including Intel Recommended Reading List (IRRL) for developers is a good resource to check out. Speaking of my books, Didier Van Hoye (@WorkingHardInIt) has a good review over on his site you can view here, also check out the rest of his great content while there.
Containers, serverless, kubernetes continue to gain in industry adoption, as well as customer deployments. Here is some information about Microsoft Azure Kubernetes Service (AKS). Note that AWS has Elastic Kubernetes Service (EKS), Google, VMware and Pivotal with Pivotal Kubernetes Service (PKS) among others.
Here is an interesting perspective by Ben Kepps about Serverless (e.g. life beyond Kubernetes and containers (e.g. life beyond virtualization which to some is or was life (e.g. life beyond bare metal))) as well as the all to often punditry, evangelism of something new causing something else to be dead.
SNIA has updated their Emerald aka Green energy effectiveness (focus on productivity) measurement specification (V3.01) including NAS NFS file activity (besides block). Learn more at snia.org/forums/green.
Watch for more items to be added to the recommended reading list book shelf soon.

Recent and upcoming event activities.
June 27, 2018 – Webinar – TBA
May 29, 2018 – Webinar – Microsoft Windows as a Service
April 24, 2018 – Webinar – AWS and on-site, on-premises hybrid data protection
See more webinars and activities on the Server StorageIO Events page here.
Various useful links and resources:
Data Infrastructure Recommend Reading and watching list
Microsoft TechNet – Various Microsoft related from Azure to Docker to Windows
storageio.com/links – Various industry links (over 1,000 with more to be added soon)
objectstoragecenter.com – Cloud and object storage topics, tips and news items
OpenStack.org – Various OpenStack related items
storageio.com/downloads – Various presentations and other download material
storageio.com/protect – Various data protection items and topics
thenvmeplace.com – Focus on NVMe trends and technologies
thessdplace.com – NVM and Solid State Disk topics, tips and techniques
storageio.com/converge – Various CI, HCI and related SDS topics
storageio.com/performance – Various server, storage and I/O benchmark and tools
VMware Technical Network – Various VMware related items
What this all means and wrap-up
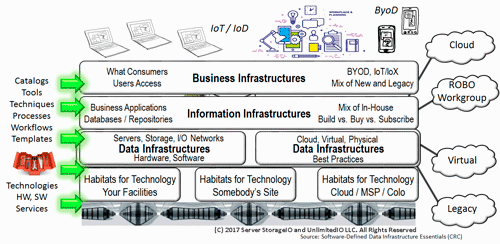
Data Infrastructures are what exists inside physical data centers spanning cloud, converged, hyper-converged, virtual, serverless and other software defined as well as legacy environments. So far this spring there has been a lot of data infrastructure related activity, from new technology announcements, to events, trends among others. Enjoy this edition of the Server StorageIO Data Infrastructure update newsletter and watch for more NVMe, Gen-Z, cloud, data protection among other topics in future posts, articles, events, and newsletters.
Ok, nuff said, for now.
Gs
Greg Schulz – Microsoft MVP Cloud and Data Center Management, VMware vExpert 2010-2018. Author of Software Defined Data Infrastructure Essentials (CRC Press), as well as Cloud and Virtual Data Storage Networking (CRC Press), The Green and Virtual Data Center (CRC Press), Resilient Storage Networks (Elsevier) and twitter @storageio. Courteous comments are welcome for consideration. First published on https://storageioblog.com any reproduction in whole, in part, with changes to content, without source attribution under title or without permission is forbidden.
All Comments, (C) and (TM) belong to their owners/posters, Other content (C) Copyright 2006-2026 Server StorageIO and UnlimitedIO. All Rights Reserved. StorageIO is a registered Trade Mark (TM) of Server StorageIO.