
Driving ROI with Cloud Storage Consolidation Seminars

Driving ROI with Cloud Storage Consolidation Seminars
Join me in a series of in-person seminars driving ROI with cloud storage consolidation for unstructured file data.
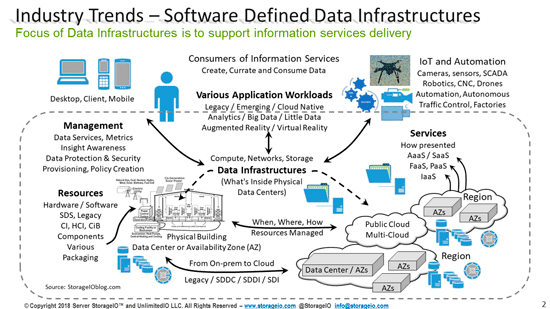
Various Data Infrastructure options from on-prem to edge to cloud and beyond
These initial seminars are being held at Amazon Web Services (AWS) locations April 30 in New York City, May 1 in Chicago and May 2 in Houston Amazon. At each of these three cities, I will be joined by experts from NetApp, Talon and AWS as we look at issues, trends and what can be done today (including hands on demos) driving ROI with cloud storage consolidation for unstructured file data.
What The Seminars Are About
These seminars look at how remove cost and complexity while boosting productivity for distributed sites with unstructured data and NAS file servers. The seminars look at making informed decisions balancing technical considerations with a business return on investment (ROI) model, along with return on innovation (the other ROI) from boosting productivity. It’s not about simply cutting costs that can create chaos or compromise elsewhere, it’s about removing complexity and cost while boosting productivity with smart cloud storage consolidation for unstructured file data.

Distributed File Server Cloud Storage Consolidation ROI Economic Comparison
During these seminars I will discuss various industry and customer trends, challenges as well as solutions, particular for environments with distributed file servers for unstructured file data. As part of my discussion, we will look at both technical, as well as ROI business based model for distributed file server cloud storage consolidation based on the Server StorageIO white paper report titled Cloud File Data Storage Consolidation and Economic Comparison Model (Free PDF download here).
Where When and How to Register
New York City Tuesday April 30, 2019 9:00AM
Amazon Web Services
7 West 34th St.
6th Floor
Learn more and register here.
Chicago Illinois Wednesday May 1, 2019 9:00AM
Amazon Web Services
222 West Adams Street
Suite 1400
Learn more and register here
Houston Texas Thursday May 2, 2019 9:00AM
Amazon Web Services
825 Town and Country Lane
Suite 1000
Learn more and register here
Where to learn more
Learn more about world backup day, recovery and data protection along with other related topics via the following links:
- Cloud File Data Storage Consolidation and Economic Comparison Model (PDF)
- Cloud File Data Storage Consolidation and Economic Comparison Model
- Cloud Ready Data Protection for Hybrid Data Centers Are In Your Future
- Announcing My New Book Data Infrastructure Management Insight Strategies
- World Backup Day Reminder Don’t Be an April Fool Test Your Data Recovery
- Virtual, Cloud and IT Availability, it’s a shared responsibility and common sense
- Don’t Stop Learning Expand Your Skills Experiences Everyday
- Data Infrastructure server storage I/O network Recommended Reading
- Data Infrastructure Overview, Its What’s Inside of a Data Center
- Application Data Value Characteristics Everything Is Not The Same (five-part mini-series)
- Data Protection Diaries Fundamental Topics Tools Techniques Technologies Tips
- Data Infrastructure Server Storage I/O related Tradecraft Overview
- The SSD Place (SSD, NVM, PM, SCM, Flash, NVMe, 3D XPoint, Optane, MRAM and related topics)
- The NVMe Place (NVMe related topics, trends, tools, technologies, tip resources
Additional learning experiences along with common questions (and answers), as well as tips can be found in Software Defined Data Infrastructure Essentials book.

What this all means
Making informed decisions for data infrastructure resources including cloud storage consolidation and distributed file servers involves technical, application workload as well as business economic analysis. Which of the three (technical, application workload, financial) is more important for enabling a business benefit will depend on your perspective, as well as area of focus. However, all the above need to be considered in the balance as part of making an informed data infrastructure resource decision. That is where a discussion about a business financial ROI model (pro forma if you prefer) comes into play as part of cloud storage consolidation, including for distributed file server of unstructured file data.
I look forward to meeting with attendees and hope to see you at the events April 30th in New York City, May 1 in Chicago, and Houston May 2nd as we discuss driving ROI with cloud storage consolidation at these seminars.
Ok, nuff said, for now.
Cheers GS
Greg Schulz – Multi-year Microsoft MVP Cloud and Data Center Management, ten-time VMware vExpert. Author of Data Infrastructure Insights (CRC Press), Software Defined Data Infrastructure Essentials (CRC Press), as well as Cloud and Virtual Data Storage Networking (CRC Press), The Green and Virtual Data Center (CRC Press), Resilient Storage Networks (Elsevier) and twitter @storageio. Also visit www.picturesoverstillwater.com to view various UAS/UAV e.g. drone based aerial content created by Greg Schulz. Courteous comments are welcome for consideration. First published on https://storageioblog.com any reproduction in whole, in part, with changes to content, without source attribution under title or without permission is forbidden.
All Comments, (C) and (TM) belong to their owners/posters, Other content (C) Copyright 2006-2026 Server StorageIO and UnlimitedIO. Visit our companion site https://picturesoverstillwater.com to view drone based aerial photography and video related topics. All Rights Reserved. StorageIO is a registered Trade Mark (TM) of Server StorageIO.












{kind=link}