Recently Hailey Lynne McKeefry (@HaileyMcK), Editor in Chief over at Data Center Acceleration (@DataAccelerate) reached out for a conversation about well, data center themes and topics. Given Hailey’s background in covering technology as well as business supply chain we somehow ended up talking about business, IT and data center sustainability. Hailey wrote a piece about Driving for Datacenter Sustainability and in addition I was honored to be an invited guest for a live on-line chat yesterday (you can view the conversation here).
Excerpt from Haileys piece:
Too often, sustainability efforts in the datacenter are written off as feel-good, public relations efforts. In reality, green is about economics — and done well, it can save the datacenter tons of cash.
"You mention green, and datacenter managers run or cringe and roll their eyes, because there’s been so much green washing done in the past few years," said Greg Schulz, founder of IT consultancy StorageIO. "It’s really about green economics, though, and getting more work done with the same budget."
Read more of Hailey’s piece here
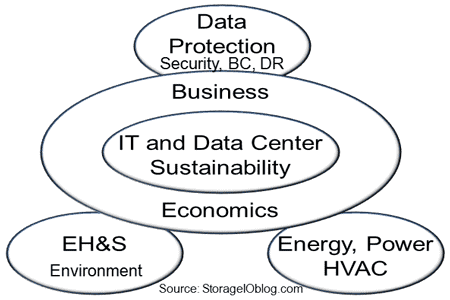
Many different faces of IT and data center sustainability
Granted, when you here the term sustainability, IT and data centers you may think of different things depending on your view or area of focus.
For some it will be Green or environmental focused such as use of renewable and EH&S themes, recycling among others Related to the previous item some will see sustainability as being tied to energy, either tied to cost, availability/accessibility, standby or alternative and renewable Yet for others, it will mean business continuance (BC), disaster recovery (DR), business resiliency (BR), high availability or reliability availability service (RAS) among others Then the economics concerns of keeping the business running to discuss top and bottom line concerns.
Otoh, if your focus is on one of the above or a subset of one of them, you might not view the other areas as being tied to sustainability.
Likewise, you might even want to not be included in another other, let alone share your area with others. For example if your focus is on security you may not want to see or hear that data protection is part of sustainability, not to mention backup/restore, bc, dr and so forth.
Learning, education and knowledge sustainability
Part of sustainability is also continuing to learn about new things not only in your field or focus area, also in adjacent spaces.
Keep in mind that there is more of a data center or information factory than just a building or facility with power, cooling as there are the technologies, tools, people, process, delivery/distribution network, warehouse for storing raw and finished material, metrics and management that all go into delivering the product which is information services.
Hence there are many aspects to IT and data center sustainability and thus think more pragmatically about sustaining information factories, however lets also be realistic and not jump the shark by declaring everything as sustainable ;).
Check out the live talk chat that we had yesterday over at Data Center Acceleration by clicking here.
Can we get a side of context with them server storage metrics?
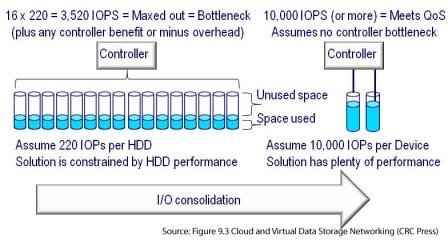
Whats the best server storage I/O network metric or benchmark? It depends as there needs to be some context with them IOPS and other server storage I/O metrics that matter.
In the meantime, let’s get a side of some context with them IOPS from vendors, marketers and their pundits who are tossing them around for server, storage and IO metrics that matter.
Expanding the conversation, the need for more context
The good news is that people are beginning to discuss storage beyond space capacity and cost per GByte, TByte or PByte for both DRAM or nand flash Solid State Devices (SSD), Hard Disk Drives (HDD) along with Hybrid HDD (HHDD) and Solid State Hybrid Drive (SSHD) based solutions. This applies to traditional enterprise or SMB IT data center with physical, virtual or cloud based infrastructures.
This is good because it expands the conversation beyond just cost for space capacity into other aspects including performance (IOPS, latency, bandwidth) for various workload scenarios along with availability, energy effective and management.
Adding a side of context
The catch is that IOPS while part of the equation are just one aspect of performance and by themselves without context, may have little meaning if not misleading in some situations.
Granted it can be entertaining, fun to talk about or simply make good press copy for a million IOPS. IOPS vary in size depending on the type of work being done, not to mention reads or writes, random and sequential which also have a bearing on data throughout or bandwidth (Mbytes per second) along with response time. Not to mention block, file, object or blob as well as table.
However, are those million IOP’s applicable to your environment or needs?
Likewise, what do those million or more IOPS represent about type of work being done? For example, are they small 64 byte or large 64 Kbyte sized, random or sequential, cached reads or lazy writes (deferred or buffered) on a SSD or HDD?
How about the response time or latency for achieving them IOPS?
In other words, what is the context of those metrics and why do they matter?
Metrics that matter give context for example IO sizes closer to what your real needs are, reads and writes, mixed workloads, random or sequential, sustained or bursty, in other words, real world reflective.
As with any benchmark take them with a grain (or more) of salt, they key is use them as an indicator then align to your needs. The tool or technology should work for you, not the other way around.
Here are some examples of context that can be added to help make IOP’s and other metrics matter:
What is the IOP size, are they 512 byte (or smaller) vs. 4K bytes (or larger)?
Are they reads, writes, random, sequential or mixed and what percentage?
How was the storage configured including RAID, replication, erasure or dispersal codes?
Then there is the latency or response time and IO queue depths for the given number of IOPS.
Let us not forget if the storage systems (and servers) were busy with other work or not.
If there is a cost per IOP, is that list price or discount (hint, if discount start negotiations from there)
What was the number of threads or workers, along with how many servers?
What tool was used, its configuration, as well as raw or cooked (aka file system) IO?
Was the IOP’s number with one worker or multiple workers on a single or multiple servers?
Did the IOP’s number come from a single storage system or total of multiple systems?
Fast storage needs fast serves and networks, what was their configuration?
Was the performance a short burst, or long sustained period?
What was the size of the test data used; did it all fit into cache?
Were write data committed synchronously to storage, or deferred (aka lazy writes used)?
The above are just a sampling and not all may be relevant to your particular needs, however they help to put IOP’s into more contexts. Another consideration around IOPS are the configuration of the environment, from an actual running application using some measurement tool, or are they generated from a workload tool such as IOmeter, IOrate, VDbench among others.
Sure, there are more contexts and information that would be interesting as well, however learning to walk before running will help prevent falling down.
Does size or age of vendors make a difference when it comes to context?
Some vendors are doing a good job of going for out of this world record-setting marketing hero numbers.
Meanwhile other vendors are doing a good job of adding context to their IOP or response time or bandwidth among other metrics that matter. There is a mix of startup and established that give context with their IOP’s or other metrics, likewise size or age does not seem to matter for those who lack context.
Some vendors may not offer metrics or information publicly, so fine, go under NDA to learn more and see if the results are applicable to your environments.
Likewise, if they do not want to provide the context, then ask some tough yet fair questions to decide if their solution is applicable for your needs.
What this means is let us start putting and asking for metrics that matter such as IOP’s with context.
If you have a great IOP metric, if you want it to matter than include some context such as what size (e.g. 4K, 8K, 16K, 32K, etc.), percentage of reads vs. writes, latency or response time, random or sequential.
IMHO the most interesting or applicable metrics that matter are those relevant to your environment and application. For example if your main application that needs SSD does about 75% reads (random) and 25% writes (sequential) with an average size of 32K, while fun to hear about, how relevant is a million 64 byte read IOPS? Likewise when looking at IOPS, pay attention to the latency, particular if SSD or performance is your main concern.
Get in the habit of asking or telling vendors or their surrogates to provide some context with them metrics if you want them to matter.
So how about some context around them IOP’s (or latency and bandwidth or availability for that matter)?
All Comments, (C) and (TM) belong to their owners/posters, Other content (C) Copyright 2006-2026 Server StorageIO and UnlimitedIO. All Rights Reserved. StorageIO is a registered Trade Mark (TM) of Server StorageIO.
This is the second post of a two-part series looking at storage performance, specifically in the context of drive or device (e.g. mediums) characteristics of How many IOPS can a HDD HHDD SSD do with VMware. In the first post the focus was around putting some context around drive or device performance with the second part looking at some workload characteristics (e.g. benchmarks).
Here are some examples to give you some more insight.
For example, the following shows how IOPS vary by changing the percent of reads, writes, random and sequential for a 4K (4,096 bytes or 4 KBytes) IO size with each test step (4 minutes each).
IO Size for test
Workload Pattern of test
Avg. Resp (R+W) ms
Avg. IOP Sec (R+W)
Bandwidth KB Sec (R+W)
4KB
100% Seq 100% Read
0.0
29,736
118,944
4KB
60% Seq 100% Read
4.2
236
947
4KB
30% Seq 100% Read
7.1
140
563
4KB
0% Seq 100% Read
10.0
100
400
4KB
100% Seq 60% Read
3.4
293
1,174
4KB
60% Seq 60% Read
7.2
138
554
4KB
30% Seq 60% Read
9.1
109
439
4KB
0% Seq 60% Read
10.9
91
366
4KB
100% Seq 30% Read
5.9
168
675
4KB
60% Seq 30% Read
9.1
109
439
4KB
30% Seq 30% Read
10.7
93
373
4KB
0% Seq 30% Read
11.5
86
346
4KB
100% Seq 0% Read
8.4
118
474
4KB
60% Seq 0% Read
13.0
76
307
4KB
30% Seq 0% Read
11.6
86
344
4KB
0% Seq 0% Read
12.1
82
330
Dell/Western Digital (WD) 1TB 7200 RPM SATA HDD (Raw IO) thread count 1 4K IO size
In the above example the drive is a 1TB 7200 RPM 3.5 inch Dell (Western Digital) 3Gb SATA device doing raw (non file system) IO. Note the high IOP rate with 100 percent sequential reads and a small IO size which might be a result of locality of reference due to drive level cache or buffering.
Some drives have larger buffers than others from a couple to 16MB (or more) of DRAM that can be used for read ahead caching. Note that this level of cache is independent of a storage system, RAID adapter or controller or other forms and levels of buffering.
Does this mean you can expect or plan on getting those levels of performance?
I would not make that assumption, and thus this serves as an example of using metrics like these in the proper context.
Building off of the previous example, the following is using the same drive however with a 16K IO size.
IO Size for test
Workload Pattern of test
Avg. Resp (R+W) ms
Avg. IOP Sec (R+W)
Bandwidth KB Sec (R+W)
16KB
100% Seq 100% Read
0.1
7,658
122,537
16KB
60% Seq 100% Read
4.7
210
3,370
16KB
30% Seq 100% Read
7.7
130
2,080
16KB
0% Seq 100% Read
10.1
98
1,580
16KB
100% Seq 60% Read
3.5
282
4,522
16KB
60% Seq 60% Read
7.7
130
2,090
16KB
30% Seq 60% Read
9.3
107
1,715
16KB
0% Seq 60% Read
11.1
90
1,443
16KB
100% Seq 30% Read
6.0
165
2,644
16KB
60% Seq 30% Read
9.2
109
1,745
16KB
30% Seq 30% Read
11.0
90
1,450
16KB
0% Seq 30% Read
11.7
85
1,364
16KB
100% Seq 0% Read
8.5
117
1,874
16KB
60% Seq 0% Read
10.9
92
1,472
16KB
30% Seq 0% Read
11.8
84
1,353
16KB
0% Seq 0% Read
12.2
81
1,310
Dell/Western Digital (WD) 1TB 7200 RPM SATA HDD (Raw IO) thread count 1 16K IO size
The previous two examples are excerpts of a series of workload simulation tests (ok, you can call them benchmarks) that I have done to collect information, as well as try some different things out.
The following is an example of the summary for each test output that includes the IO size, workload pattern (reads, writes, random, sequential), duration for each workload step, totals for reads and writes, along with averages including IOP’s, bandwidth and latency or response time.
Want to see more numbers, speeds and feeds, check out the following table which will be updated with extra results as they become available.
Performance characteristics 1 worker (thread count) for RAW IO (non-file system)
Note: (1) Seagate Momentus XT is a Hybrid Hard Disk Drive (HHDD) based on a 7.2K 2.5 HDD with SLC nand flash integrated for read buffer in addition to normal DRAM buffer. This model is a XT I (4GB SLC nand flash), may add an XT II (8GB SLC nand flash) at some future time.
As a starting point, these results are raw IO with file system based information to be added soon along with more devices. These results are for tests with one worker or thread count, other results will be added with such as 16 workers or thread counts to show how those differ.
The above results include all reads, all writes, mix of reads and writes, along with all random, sequential and mixed for each IO size. IO sizes include 4K, 8K, 16K, 32K, 64K, 128K, 256K, 512K, 1024K and 2048K. As with any workload simulation, benchmark or comparison test, take these results with a grain of salt as your mileage can and will vary. For example you will see some what I consider very high IO rates with sequential reads even without file system buffering. These results might be due to locality of reference of IO’s being resolved out of the drives DRAM cache (read ahead) which vary in size for different devices. Use the vendor model numbers in the table above to check the manufactures specs on drive DRAM and other attributes.
If you are used to seeing 4K or 8K and wonder why anybody would be interested in some of the larger sizes take a look at big fast data or cloud and object storage. For some of those applications 2048K may not seem all that big. Likewise if you are used to the larger sizes, there are still applications doing smaller sizes. Sorry for those who like 512 byte or smaller IO’s as they are not included. Note that for all of these unless indicated a 512 byte standard sector or drive format is used as opposed to emerging Advanced Format (AF) 4KB sector or block size. Watch for some more drive and device types to be added to the above, along with results for more workers or thread counts, along with file system and other scenarios.
Using VMware as part of a Server, Storage and IO (aka StorageIO) test platform
The above performance results were generated on Ubuntu 12.04 (since upgraded to 14.04 which was hosted on a VMware vSphere 5.1 (upgraded to 5.5U2) purchased version (you can get the ESXi free version here) with vCenter enabled system. I also have VMware workstation installed on some of my Windows-based laptops for doing preliminary testing of scripts and other activity prior to running them on the larger server-based VMware environment. Other VMware tools include vCenter Converter, vSphere Client and CLI. Note that other guest virtual machines (VMs) were idle during the tests (e.g. other guest VMs were quiet). You may experience different results if you ran Ubuntu native on a physical machine or with different adapters, processors and device configurations among many other variables (that was a disclaimer btw ;) ).
All of the devices (HDD, HHDD, SSD’s including those not shown or published yet) were Raw Device Mapped (RDM) to the Ubuntu VM bypassing VMware file system.
Example of creating an RDM for local SAS or SATA direct attached device.
The above uses the drives address (find by doing a ls -l /dev/disks via VMware shell command line) to then create a vmdk container stored in a dat. Note that the RDM being created does not actually store data in the .vmdk, it’s there for VMware management operations.
If you are not familiar with how to create a RDM of a local SAS or SATA device, check out this post to learn how.This is important to note in that while VMware was used as a platform to support the guest operating systems (e.g. Ubuntu or Windows), the real devices are not being mapped through or via VMware virtual drives.
The above shows examples of RDM SAS and SATA devices along with other VMware devices and dats. In the next figure is an example of a workload being run in the test environment.
One of the advantages of using VMware (or other hypervisor) with RDM’s is that I can quickly define via software commands where a device gets attached to different operating systems (e.g. the other aspect of software defined storage). This means that after a test run, I can quickly simply shutdown Ubuntu, remove the RDM device from that guests settings, move the device just tested to a Windows guest if needed and restart those VMs. All of that from where ever I happen to be working from without physically changing things or dealing with multi-boot or cabling issues.
All Comments, (C) and (TM) belong to their owners/posters, Other content (C) Copyright 2006-2026 Server StorageIO and UnlimitedIO. All Rights Reserved. StorageIO is a registered Trade Mark (TM) of Server StorageIO.
How many i/o iops can flash ssd or hdd do with vmware?
Updated 2/10/2018
A common question I run across is how many I/O iopsS can flash SSD or HDD storage device or system do or give.
The answer is or should be it depends.
This is the first of a two-part series looking at storage performance, and in context specifically around drive or device (e.g. mediums) characteristics across HDD, HHDD and SSD that can be found in cloud, virtual, and legacy environments. In this first part the focus is around putting some context around drive or device performance with the second part looking at some workload characteristics (e.g. benchmarks).
Lets leave those for a different discussion at another time.
Getting started
Part of my interest in tools, metrics that matter, measurements, analyst, forecasting ties back to having been a server, storage and IO performance and capacity planning analyst when I worked in IT. Another aspect ties back to also having been a sys admin as well as business applications developer when on the IT customer side of things. This was followed by switching over to the vendor world involved with among other things competitive positioning, customer design configuration, validation, simulation and benchmarking HDD and SSD based solutions (e.g. life before becoming an analyst and advisory consultant).
Btw, if you happen to be interested in learn more about server, storage and IO performance and capacity planning, check out my first book Resilient Storage Networks (Elsevier) that has a bit of information on it. There is also coverage of metrics and planning in my two other books The Green and Virtual Data Center (CRC Press) and Cloud and Virtual Data Storage Networking (CRC Press). I have some copies of Resilient Storage Networks available at a special reader or viewer rate (essentially shipping and handling). If interested drop me a note and can fill you in on the details.
There are many rules of thumb (RUT) when it comes to metrics that matter such as IOPS, some that are older while others may be guess or measured in different ways. However the answer is that it depends on many things ranging from if a standalone hard disk drive (HDD), Hybrid HDD (HHDD), Solid State Device (SSD) or if attached to a storage system, appliance, or RAID adapter card among others.
Taking a step back, the big picture
Various HDD, HHDD and SSD’s
Server, storage and I/O performance and benchmark fundamentals
Even if just looking at a HDD, there are many variables ranging from the rotational speed or Revolutions Per Minute (RPM), interface including 1.5Gb, 3.0Gb, 6Gb or 12Gb SAS or SATA or 4Gb Fibre Channel. If simply using a RUT or number based on RPM can cause issues particular with 2.5 vs. 3.5 or enterprise and desktop. For example, some current generation 10K 2.5 HDD can deliver the same or better performance than an older generation 3.5 15K. Other drive factors (see this link for HDD fundamentals) including physical size such as 3.5 inch or 2.5 inch small form factor (SFF), enterprise or desktop or consumer, amount of drive level cache (DRAM). Space capacity of a drive can also have an impact such as if all or just a portion of a large or small capacity devices is used. Not to mention what the drive is attached to ranging from in internal SAS or SATA drive bay, USB port, or a HBA or RAID adapter card or in a storage system.
HDD fundamentals
How about benchmark and performance for marketing or comparison tricks including delayed, deferred or asynchronous writes vs. synchronous or actually committed data to devices? Lets not forget about short stroking (only using a portion of a drive for better IOP’s) or even long stroking (to get better bandwidth leveraging spiral transfers) among others.
Almost forgot, there are also thick, standard, thin and ultra thin drives in 2.5 and 3.5 inch form factors. What’s the difference? The number of platters and read write heads. Look at the following image showing various thickness 2.5 inch drives that have various numbers of platters to increase space capacity in a given density. Want to take a wild guess as to which one has the most space capacity in a given footprint? Also want to guess which type I use for removable disk based archives along with for onsite disk based backup targets (compliments my offsite cloud backups)?
Thick, thin and ultra thin devices
Beyond physical and configuration items, then there are logical configuration including the type of workload, large or small IOPS, random, sequential, reads, writes or mixed (various random, sequential, read, write, large and small IO). Other considerations include file system or raw device, number of workers or concurrent IO threads, size of the target storage space area to decide impact of any locality of reference or buffering. Some other items include how long the test or workload simulation ran for, was the device new or worn in before use among other items.
Tools and the performance toolbox
Then there are the various tools for generating IO’s or workloads along with recording metrics such as reads, writes, response time and other information. Some examples (mix of free or for fee) include Bonnie, Iometer, Iorate, IOzone, Vdbench, TPC, SPC, Microsoft ESRP, SPEC and netmist, Swifttest, Vmark, DVDstore and PCmark 7 among many others. Some are focused just on the storage system and IO path while others are application specific thus exercising servers, storage and IO paths.
Server, storage and IO performance toolbox
Having used Iometer since the late 90s, it has its place and is popular given its ease of use. Iometer is also long in the tooth and has its limits including not much if any new development, never the less, I have it in the toolbox. I also have Futremark PCmark 7 (full version) which turns out has some interesting abilities to do more than exercise an entire Windows PC. For example PCmark can use a secondary drive for doing IO to.
PCmark can be handy for spinning up with VMware (or other tools) lots of virtual Windows systems pointing to a NAS or other shared storage device doing real world type activity. Something that could be handy for testing or stressing virtual desktop infrastructures (VDI) along with other storage systems, servers and solutions. I also have Vdbench among others tools in the toolbox including Iorate which was used to drive the workloads shown below.
What I look for in a tool are how extensible are the scripting capabilities to define various workloads along with capabilities of the test engine. A nice GUI is handy which makes Iometer popular and yes there are script capabilities with Iometer. That is also where Iometer is long in the tooth compared to some of the newer generation of tools that have more emphasis on extensibility vs. ease of use interfaces. This also assumes knowing what workloads to generate vs. simply kicking off some IOPs using default settings to see what happens.
Another handy tool is for recording what’s going on with a running system including IO’s, reads, writes, bandwidth or transfers, random and sequential among other things. This is where when needed I turn to something like HiMon from HyperIO, if you have not tried it, get in touch with Tom West over at HyperIO and tell him StorageIO sent you to get a demo or trial. HiMon is what I used for doing start, stop and boot among other testing being able to see IO’s at the Windows file system level (or below) including very early in the boot or shutdown phase.
All Comments, (C) and (TM) belong to their owners/posters, Other content (C) Copyright 2006-2026 Server StorageIO and UnlimitedIO. All Rights Reserved. StorageIO is a registered Trade Mark (TM) of Server StorageIO.
This is the second in a two-part industry trends and perspective looking at learning from cloud incidents, view part I here.
There is good information, insight and lessons to be learned from cloud outages and other incidents.
Sorry cynics no that does not mean an end to clouds, as they are here to stay. However when and where to use them, along with what best practices, how to be ready and configure for use are part of the discussion. This means that clouds may not be for everybody or all applications, or at least today. For those who are into clouds for the long haul (either all in or partially) including current skeptics, there are many lessons to be learned and leveraged.
In order to gain confidence in clouds, some questions that I routinely am asked include are clouds more or less reliable than what you are doing? Depends on what you are doing, and how you will be using the cloud services. If you are applying HA and other BC or resiliency best practices, you may be able to configure and isolate from the more common situations. On the other hand, if you are simply using the cloud services as a low-cost alternative selecting the lowest price and service class (SLAs and SLOs), you might get what you paid for. Thus, clouds are a shared responsibility, the service provider has things they need to do, and the user or person designing how the service will be used have some decisions making responsibilities.
Keep in mind that high availability (HA), resiliency, business continuance (BC) along with disaster recovery (DR) are the sum of several pieces. This includes people, best practices, processes including change management, good design eliminating points of failure and isolating or containing faults, along with how the components or technology used (e.g. hardware, software, networks, services, tools). Good technology used in goods ways can be part of a highly resilient flexible and scalable data infrastructure. Good technology used in the wrong ways may not leverage the solutions to their full potential.
While it is easy to focus on the physical technologies (servers, storage, networks, software, facilities), many of the cloud services incidents or outages have involved people, process and best practices so those need to be considered.
These incidents or outages bring awareness, a level set, that this is still early in the cloud evolution lifecycle and to move beyond seeing clouds as just a way to cut cost, and seeing the importance and value HA, resiliency, BC and DR. This means learning from mistakes, taking action to correct or fix errors, find and cut points of failure are part of a technology maturing or the use of it. These all tie into having services with service level agreements (SLAs) with service level objectives (SLOs) for availability, reliability, durability, accessibility, performance and security among others to protect against mayhem or other things that can and do happen.
The reason I mentioned earlier that AWS had another incident is that like their peers or competitors who have incidents in the past, AWS appears to be going through some growing, maturing, evolution related activities. During summer 2012 there was an AWS incident that affected Netflix (read more here: AWS and the Netflix Fix?). It should also be noted that there were earlier AWS outages where Netflix (read about Netflix architecture here) leveraged resiliency designs to try and prevent mayhem when others were impacted.
Is AWS a lightning rod for things to happen, a point of attraction for Mayhem and others?
Granted given their size, scope of services and how being used on a global basis AWS is blazing new territory and experiences, similar to what other information services delivery platforms did in the past. What I mean is that while taken for granted today, open systems Unix, Linux, Windows-based along with client-server, midrange or distributed systems, not to mention mainframe hardware, software, networks, processes, procedures, best practices all went through growing pains.
There are a couple of interesting threads going on over in various LinkedIn Groups based on some reporters stories including on speculation of what happened, followed with some good discussions of what actually happened and how to prevent recurrence of them in the future.
Over in the Cloud Computing, SaaS & Virtualization group forum, this thread is based on a Forbes article (Amazon AWS Takes Down Netflix on Christmas Eve) and involves conversations about SLAs, best practices, HA and related themes. Have a look at the story the thread is based on and some of the assertions being made, and ensuing discussions.
Also over at LinkedIn, in the Cloud Hosting & Service Providers group forum, this thread is based on a story titled Why Netflix’ Christmas Eve Crash Was Its Own Fault with a good discussion on clouds, HA, BC, DR, resiliency and related themes.
Over at the Virtualization Practice, there is a piece titled Is Amazon Ruining Public Cloud Computing? with comments from me and Adrian Cockcroft (@Adrianco) a Netflix Architect (you can read his blog here). You can also view some presentations about the Netflix architecture here.
What this all means
Saying you get what you pay for would be too easy and perhaps not applicable.
There are good services free, or low-cost, just like good free content and other things, however vice versa, just because something costs more, does not make it better.
Otoh, there are services that charge a premium however may have no better if not worse reliability, same with content for fee or perceived value that is no better than what you get free.
Clouds are real and can be used safely; however, they are a shared responsibility.
Only you can prevent cloud data loss, which means do your homework, be ready.
If something can go wrong, it probably will, particularly if humans are involved.
Prepare for the unexpected and clarify assumptions vs. realities of service capabilities.
Leverage fault isolation and containment to prevent rolling or spreading disasters.
Look at cloud services beyond lowest cost or for cost avoidance.
What is your organizations culture for learning from mistakes vs. fixing blame?
Ask yourself if you, your applications and organization are ready for clouds.
Ask your cloud providers if they are ready for you and your applications.
Identify what your cloud concerns are to decide what can be done about them.
Do a proof of concept to decide what types of clouds and services are best for you.
Do not be scared of clouds, however be ready, do your homework, learn from the mistakes, misfortune and errors of others. Establish and leverage known best practices while creating new ones. Look at the past for guidance to the future, however avoid clinging to, and bringing the baggage of the past to the future. Use new technologies, tools and techniques in new ways vs. using them in old ways.
All Comments, (C) and (TM) belong to their owners/posters, Other content (C) Copyright 2006-2026 Server StorageIO and UnlimitedIO LLC All Rights Reserved
In the spirit of Halloween and zombies season, a couple of thoughts come to mind about vendor tricks and treats. This is an industry trends and perspectives post, part of an ongoing series looking at various technology and fun topics.
The first trick or treat game pertains to the blame game; you know either when something breaks, or at the other extreme, before you have even made a decision to buy something. The trick or treat game for decision-making goes something like this.
Vendor “A” says products succeed with their solution while failure results with a solution from “B” when doing “X”. Otoh, vendor “B” claims that “X” will fail when using a solution from vendor “A”. In fact, you can pick what you want to substitute for “X”, perhaps VDI, PCIe, Big Data, Little Data, Backup, Archive, Analytics, Private Cloud, Public Cloud, Hybrid Cloud, eDiscovery you name it.
This is not complicated math or big data problem requiring a high-performance computing (HPC) platform. A HPC Zetta-Flop processing ability using 512 bit addressing of 9.9 (e.g. 1 nine) PettaBytes of battery-backed DRAM and an IO capability of 9.99999 (e.g. 5 9’s) trillion 8 bit IOPS to do table pivots or runge kutta numerical analysis, map reduce, SAS or another modeling with optional iProduct or Android interface are not needed.
StorageIO images of touring Texas Advanced Computing (e.g. HPC) Center
Can you solve this equation? Hint it does not need a PhD or any other advanced degree. Another hint, if you have ever been at any side of the technology product and services decision-making table, regardless of the costume you wore, you should know the answer.
Of course the question of would “X” fail regardless of who or what “A” or “B” let alone a “C”, “D” or “F”? In other words, it is not the solution, technology, vendor or provider, rather the problem or perhaps even lack thereof that is the issue. Or is it a case where there is a solution from “A”, “B” or any others that is looking for a problem, and if it is the wrong problem, there can be a wrong solution thus failure?
Another trick or treat game is vendors public relations (PR) or analyst relations (AR) people to ask for one thing and delivery or ask another. For example, some vendor, service provider, their marketing AR and PR people or surrogates make contact wanting to tell of various success and failure story. Of course, this is usually their success and somebody else’s failure, or their victory over something or someone who sometimes can be interesting. Of course, there are also the treats to get you to listen to the above, such as tempt you with a project if you meet with their subject, which may be a trick of a disappearing treat (e.g. magic, poof it is gone after the discussion).
There are another AR and PR trick and treat where they offer on behalf of their representative organization or client to a perspective or exclusive insight on their competitor. Of course, the treat from their perspective is that they will generously expose all that is wrong with what a competitor is saying about their own (e.g. the competitors) product.
Let me get this straight, I am not supposed to believe what somebody says about his or her own product, however, supposed to believe what a competitor says is wrong with the competition’s product, and what is right with his or her own product.
Hmm, ok, so let me get this straight, a competitor say “A” wants to tell me what somebody say from “B” has told me is wrong and I should schedule a visit with a truth squad member from “A” to get the record set straight about “B”?
Does that mean then that I go to “B” for a rebuttal, as well as an update about “A” from “B”, assuming that what “A” has told me is also false about themselves, and perhaps about “B” or any other?
Too be fair, depending on your level of trust and confidence in either a vendor, their personal or surrogates, you might tend to believe more from them vs. others, or at least until you been tricked after given treats. There may be some that have been tricked, or they tried applying to many treats to present a story that behind the costume might be a bit scary.
Having been through enough of these, and I candidly believe that sometimes “A” or “B” or any other party actually do believe that they have more or better info about their competitor and that they can convince somebody about what their competitor is doing better than the competitor can. I also believe that there are people out there who will go to “A” or “B” and believe what they are told by based on their preference, bias or interests.
When I hear from vendors, VARs, solution or service providers and others, it’s interesting hearing point, counterpoint and so forth, however if time is limited, I’am more interested in hearing from such as “A” about them, what they are doing, where success, where challenges, where going and if applicable, under NDA go into more detail.
Customer success stories are good, however again, if interested in what works, what kind of works, or what does not work, chances are when looking for G2 vs. GQ, a non-scripted customer conversation or perspective of the good, the bad and the ugly is preferred, even if under NDA. Again, if time is limited which it usually is, focus on what is being done with your solution, where it is going and if compelled send follow-up material that can of course include MUD and FUD about others if that is your preference.
Then there is when during a 30 minute briefing, the vendor or solution provider is still talking about trends, customer pain points, what competitors are doing at 21 minutes into the call with no sign of an announcement, update or news in site
Lets not forget about the trick where the vendor marketing or PR person reaches out and says that the CEO, CMO, CTO or some other CxO or Chief Jailable Officer (CJO) wants to talk with you. Part of the trick is when the CxO actually makes it to the briefing and is not ready, does not know why the call is occurring, or, thinks that a request for an audience has been made with them for an interview or something else.
A treat is when 3 to 4 minutes into a briefing, the vendor or solution provider has already framed up what and why they are doing something. This means getting to what they are announcing or planning on doing and getting into a conversation to discuss what they are doing and making good follow-up content and resources available.
Sometimes a treat is when a briefer goes on autopilot nailing their script for 29 of a 30 minute session then use the last-minute to ask if there are any questions. The reason autopilot briefings can be a treat is when they are going over what is in the slide deck, webex, or press release thus affording an opportunity to get caught up on other things while talk at you. Hmm, perhaps need to consider playing some tricks in reward for those kind of treats? ;)
Do not be scared, not everybody is out to trick you with treats, and not all treats have tricks attached to them. Be prepared, figure out who is playing tricks with treats, and who has treats without tricks.
Oh, and as a former IT customer, vendor and analyst, one of my favorites is contact information of my dogs to vendors who require registration on their websites for basic things such as data sheets. Another is supplying contact information of competing vendors sales reps to vendors who also require registration for basic data sheets or what should otherwise be generally available information as opposed to more premium treats. Of course there are many more fun tricks, however lets leave those alone for now.
Note: Zombie voting rules apply which means vote early, vote often, and of course vote for those who cannot include those that are dead (real or virtual).
Where To Learn More
View additiona related material via the following links.
All Comments, (C) and (TM) belong to their owners/posters, Other content (C) Copyright 2006-2026 Server StorageIO and UnlimitedIO. All Rights Reserved. StorageIO is a registered Trade Mark (TM) of Server StorageIO.
In the past when Green IT and Green storage was mentioned, discussions focused around energy avoidance along with space capacity reduction. While storage efficiency and optimization in the context of space-saving and capacity consolidation are part of Green storage, so too are storage IO consolidation with SSD. For inactive or less frequently accessed data, storage optimization and efficiency can focus on using various data footprint reduction techniques including archive, backup and data protection modernization, compression, dedupe, data management and deletion, along with storage tiering and thin provisioning among others.
On the other hand, for active data where performance is important, the focus expands to how to be more effective and boosting productivity with IO consolidation using SSD and other technologies.
Note that if your data center infrastructure is not efficient, then it is possible that for every watt of energy consumed, a watt (or more) of energy is needed to cool. However if your data center cooling is effective with a resulting low or good PUE, you may not be seeing a 1:1 watt or energy used for storage to cooling ratio as was more common a few years ago.
IMHO while reducing carbon footprints is a noble and good thing, however if that is your own focus or value proposition for a solution such as SSD or other Green technologies and techniques including data footprint reduction, you are missing many opportunities.
Have a read of John’s article that includes some of my comments on energy efficiency and effectiveness to support enhanced productivity, or the other aspect of Green IT being economic enabling to avoid missed opportunities.
The U.S. EPA is ready to release DRAFT 3 of the Energy Star for data center storage specification and has an upcoming web session that you can sign up for if are not on their contact list of interested stake holders. If you are not familiar with the EPA Energy star for data center storage program, here is some background information.
Thus if you are interested, see the email and information below, signup and take part if so inclined as opposed to saying that you did not have a chance to comment.
Dear ENERGY STAR® Data Center Storage Manufacturer or Other Interested Party:
The U.S. Environmental Protection Agency (EPA) would like to announce the release of the Draft 3 Version 1.0 ENERGY STAR Specification for Data Center Storage. The draft is attached and is accompanied by a cover letter and Draft Test Method. Stakeholders are invited to review these documents and submit comments to EPA via email to storage@energystar.gov by Friday, July 27, 2012.
EPA will host a webinar on Wednesday, July 11, 2012, tentatively starting at 1:00PM EST. The agenda will be focused on elements from Draft 3, Product Families, and other key topics. PleaseRSVP to storage@energystar.gov no later than Tuesday, July 3, 2012 with the subject "RSVP – Storage Draft 3 specification meeting."
If you have any questions, please contact Robert Meyers, EPA, at Meyers.Robert@epa.gov or (202) 343-9923; or John Clinger, ICF International, at John.Clinger@icfi.com or (202) 572-9432.
Thank you for your continued support of the ENERGY STAR program.
This message was sent to you on behalf of ENERGY STAR. Each ENERGY STAR partner organization must have at least one primary contact receiving e-mail to maintain partnership. If you are no longer working on ENERGY STAR, and wish to be removed as a contact, please update your contact status in your MESA account. If you are not a partner organization and wish to opt out of receiving e-mails, you may call the ENERGY STAR Hotline at 1-888-782-7937 and request to have your mass mail settings changed. Unsubscribing means that you will no longer receive program-wide or product-specific e-mails from ENERGY STAR.
What is the best kind of IO? The one you do not have to do
Updated 2/10/2018
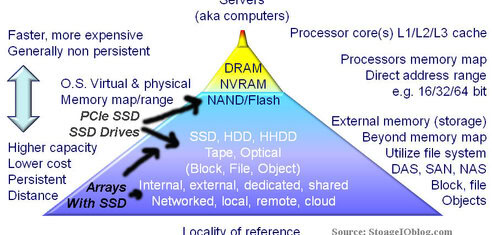
What is the best kind of IO? If no IO (input/output) operation is the best IO, than the second best IO is the one that can be done as close to the application and processor with best locality of reference. Then the third best IO is the one that can be done in less time, or at least cost or impact to the requesting application which means moving further down the memory and storage stack (figure 1).
Figure 1 memory and storage hierarchy
The problem with IO is that they are basic operation to get data into and out of a computer or processor so they are required; however, they also have an impact on performance, response or wait time (latency). IO require CPU or processor time and memory to set up and then process the results as well as IO and networking resources to move data to their destination or retrieve from where stored. While IOs cannot be eliminated, their impact can be greatly improved or optimized by doing fewer of them via caching, grouped reads or writes (pre-fetch, write behind) among other techniques and technologies.
Think of it this way, instead of going on multiple errands, sometimes you can group multiple destinations together making for a shorter, more efficient trip; however, that optimization may also take longer. Hence sometimes it makes sense to go on a couple of quick, short low latency trips vs. one single larger one that takes half a day however accomplishes many things. Of course, how far you have to go on those trips (e.g. locality) makes a difference of how many you can do in a given amount of time.
What is locality of reference?
Locality of reference refers to how close (e.g location) data exists for where it is needed (being referenced) for use. For example, the best locality of reference in a computer would be registers in the processor core, then level 1 (L1), level 2 (L2) or level 3 (L3) onboard cache, followed by dynamic random access memory (DRAM). Then would come memory also known as storage on PCIe cards such as nand flash solid state device (SSD) or accessible via an adapter on a direct attached storage (DAS), SAN or NAS device. In the case of a PCIe nand flash SSD card, even though physically the nand flash SSD is closer to the processor, there is still the overhead of traversing the PCIe bus and associated drivers. To help offset that impact, PCIe cards use DRAM as cache or buffers for data along with Meta or control information to further optimize and improve locality of reference. In other words, help with cache hits, cache use and cache effectiveness vs. simply boosting cache utilization.
All Comments, (C) and (TM) belong to their owners/posters, Other content (C) Copyright 2006-2026 Server StorageIO and UnlimitedIO. All Rights Reserved. StorageIO is a registered Trade Mark (TM) of Server StorageIO.
If you are not familiar with the Intel Recommended Reading List for Developers, it is a leading comprehensive list of different books across various technology domains covering hardware, software, servers, storage, networking, facilities, management, development and more.
So what are you waiting for, check out the Intel Recommended Reading list for Developers where you can find a diverse line up of different books of which I’m honored to have two of mine join the esteemed list. Here is a link to a free chapter download from Cloud and Virtual Data Storage Networking.
Warning: Do not be scared, however be ready for some trick and treat fun, it is after all, the Halloween season.
I like new emerging technologies and trends along with Zombie technologies, you know, those technologies that have been declared dead yet are still being enhanced, sold and used.
Zombie technologies as a name may be new for some, while others will have a realization of experiencing something from the past, technologies being declared deceased yet still alive and being used. Zombie technologies are those that have been declared dead, yet still alive enabling productivity for customers that use them and often profits for the vendors who sell them.
Some people consider a technology or trend dead once it hits the peak of hype as that can signal a time to jump to the next bandwagon or shiny new technology (or toy).
Others will see a technology as being dead when it is on the down slope of the hype curve towards the trough of disillusionment citing that as enough cause for being deceased.
Yet others will declare something dead while it matures working its way through the trough of disillusionment evolving from market adoption to customer deployment eventually onto the plateau of productivity (or profitability).
Then there are those who see something as being dead once it finally is retired from productive use, or profitable for sale.
Of course then there are those who just like to call anything new or other than what they like or that is outside of their comfort zone as being dead. In other words, if your focus or area of interest is tied to new products, technology trends and their promotion, rest assured you better be where the resources are being applied and view other things as being dead and thus probably not a fan of Zombie technologies (or at least publicly).
On the other hand, if your area of focus is on leveraging technologies and products in a productive way, including selling things that are profitable without a lot of marketing effort, your view of what is dead or not will be different. For example if you are risk averse letting someone else be on the leading bleeding edge (unless you have a dual redundant HA blood bank attached to your environment) your view of what is dead or not will be much different from those promoting the newest trend.
Funny thing about being declared dead, often it is not the technology, implementation, research and development or customer acquisitions, rather simply a lack of promotion, marketing and general awareness. Take tape for example which has been a multi decade member of the Zombie technology list. Recently vendors banded together investing or spending on marketing awareness reaching out to say tape is alive. Guess what, lo and behold, there was a flurry of tape activity in venues that normally might not be talking about tape. Funny how marketing resources can bring something back from the dead including Zombie technologies to become popular or cool to discuss again.
With the 2011 Halloween season among us, it is time to take a look this years list of Zombie technologies. Keep in mind that being named a Zombie technology is actually an honor in that it usually means someone wants to see it dead so that his or her preferred product or technology can take it place.
Here are 2011 Zombie technologies.
Backup: Far from being dead, its focus is changing and evolving with a broader emphasis on data protection. While many technologies associated with backup have been declared dead along with some backup software tools, the reality is that it is time or modernizes how backups and data protection are performed. Thus, backup is on the Zombie technology list and will live on, like it or not until it is exorcised from, your environment replaced with a modern resilient and flexible protected data infrastructure.
Big Data: While not declared dead yet, it will be soon by some creative marketer trying to come up with something new. On the other hand, there are those who have done big data analytics across different Zombie platforms for decades which of course is a badge of honor. As for some of the other newer or shiny technologies, they will have to wait to join the big data Zombies.
Cloud: Granted clouds are still on the hype cycle, some argue that it has reached its peak in terms of hype and now heading down into the trough of disillusionment, which of course some see as meaning dead. In my opinion cloud, hype has or is close to peaking, real work is occurring which means a gradual shift from industry adoption to customer deployment. Put a different way, clouds will be on the Zombie technology list of a couple of decades or more. Also, keep in mind that being on the Zombie technology list is an honor indicating shift towards adoption and less on promotion or awareness fan fare.
Data centers: With the advent of the cloud, data centers or habitats for technology have been declared dead, yet there is continued activity in expanding or building new ones all the time. Even the cloud relies on data centers for housing the physical resources including servers, storage, networks and other components that make up a Green and Virtual Data Center or Cloud environment. Needless to day, data centers will stay on the zombie list for some time.
Disk Drives: Hard disk drives (HDD) have been declared dead for many years and more recently due to popularity of SSDs have lost their sex appeal. Ironically, if tape is dead at the hands of HDDs, then how can HDDs be dead, unless of course they are on the Zombie technology list. What is happening is like tape, HDDs role are changing as the technology continues to evolve and will be around for another decade or so.
Fibre Channel (FC): This is a perennial favorite having been declared dead on a consistent basis over three decades now going back to the early 90s. While there are challengers as there have been in the past, FC is far from dead as a technology with 16 Gb (16GFC) now rolling out and a transition path for Fibre Channel over Ethernet (FCoE). My take is that FC will be on the zombie list for several more years until finally retired.
Fibre Channel over Ethernet (FCoE): This is a new entrant and one uniquely qualified for being declared dead as it is still in its infancy. Like its peer FC which was also declared dead a couple of decades ago, FCoE is just getting started and looks to be on the Zombie list for a couple of decades into the future.
Green IT: I have heard that Green IT is dead, after all, it was hyped before the cloud era which has been declared dead by some, yet there remains a Green gap or disconnect between messaging and issues thus missed opportunities. For a dead trend, SNIA recently released their Emerald program which consists of various metrics and measurements (remember, zombies like metrics to munch on) for gauging energy effectiveness for data storage. The hype cycle of Green IT and Green storage may be dead, however Green IT in the context of a shift in focus to increased productivity using the same or less energy is underway. Thus Green IT and Green storage are on the Zombie list.
iPhone: With the advent of Droid and other smart phones, I have heard iPhones declared dead, granted some older versions are. However while the Apple cofounder Steve Jobs has passed on (RIP), I suspect we will be seeing and hearing more about the iPhone for a few years more if not longer.
IBM Mainframe: When it comes to information technology (IT), the king of the Zombie list is the venerable IBM mainframe aka zSeries. The IBM mainframe has been declared dead for over 30 years if not longer and will be on the zombie list for another decade or so. After all, IBM keeps investing in the technology as people buy them not to mention IBM built a new factory to assemble them in.
NAS: Congratulations to Network Attached Storage (NAS) including Network File System (NFS) and Windows Common Internet File System (CIFS) aka Samba or SMB for making the Zombie technology list. This means of course that NAS in general is no longer considered an upstart or immature technology; rather it is being used and enhanced in many different directions.
PC: The personal computer was touted as killing off some of its Zombie technology list members including the IBM mainframe. With the advent of tablets, smart phones, virtual desktops infrastructures (VDI), the PC has been declared dead. My take is that while the IBM mainframe may eventually drop of the Zombie list in another decade or two if it finds something to do in retirement, the PC will be on the list for many years to come. Granted, the PC could live on even longer in the form of a virtual server where the majority of guest virtual machines (VMs) are in support of Windows based PC systems.
Printers: How long have we heard that printers are dead? The day that printers are dead is the day that the HP board of directors should really consider selling off that division.
RAID: Its been over twenty years since the first RAID white paper and early products appeared. Back in the 90s RAID was a popular buzzword and bandwagon topic however, people have moved on to new things. RAID has been on the Zombie technology list for several years now while it continues to find itself being deployed at the high end of the market down into consumer products. The technology continues to evolve in both hardware as well as software implementations on a local and distributed basis. Look for RAID to be on the Zombie list for at least the next couple of decades while it continues to evolve, after all, there is still room for RAID 7, RAID 8, RAID 9 not to mention moving into hexadecimal or double digit variants.
SAN: Storage Area Networks (SANs) have been declared dead and thus on the Zombie technology list before, and will be mentioned again well into the next decade. While the various technologies will continue to evolve, networking your servers to storage will also expand into different directions.
tape summit resources: Magnetic tape has been on the Zombie technology list almost as long as the IBM mainframe and it is hard to predict which one will last longer. My opinion is that tape will outlast the IBM mainframe, as it will be needed to retrieve the instructions on how to de install those Zombie monsters. Tape has seen resurgence in vendors spending some marketing resources and to no surprise, there has been an increase in coverage about it being alive, even at Google. Rest assured, tape is very safe on the Zombie technology list for another decade or more.
Windows: Similar to the PC, Microsoft Windows has been touted in the past as causing other platforms to be dead, however has been added to the Zombie list for many years now. Given that Windows is the most commonly virtualized platform or guest VM, I think we will be hearing about Windows on the Zombie list for a few decades more. There are particular versions of Windows as with any technology that have gone into maintenance or sustainment mode or even discontinued.
Poll: What are the most popular Zombie technologies?
Keep in mind that a Zombie technology is one that is still in use, being developed or enhanced, sold usually at a profit and used typically in a productive way. In some cases, a declared dead or Zombie technology may only be just in its infancy getting started having either just climbed over the peak of hype or coming out of the trough of disillusionment. In other instance, the Zombie technology has been around for a long time yet continues to be used (or abused).
Note: Zombie voting rules apply which means vote early, vote often, and of course vote for those who cannot include those that are dead (real or virtual).
Ok, nuff said, enough fun, lets get back to work, at least for now
Given the buzz about big data and conversations or confusion around clouds along with virtualizing virtually anything possible, Green IT has fallen off the Buzzword Bingo Bandwagon.
Green IT like so many other buzzwords and trends typically go through a hype cycle before getting tired, worn out, or disillusioned (see here and here). Often these buzzwords will go to Some Day Isle for some rest and recuperation before reappearing later as part of a second or third buzzword wave either making it to broad adoption which means the plateau of profitability (for vendors or vars) and productivity (for customers) or disappearing.
Some Day Isle for those not familiar with it is a visional or fictional place that some day you will go to, a wishful happy place so to speak that is perfect for hyperbole R and R. After some R and R, these trends, technologies or techniques often reappear well rested and ready for the next wave of buzz, FUD, hype and activity.
Keep in mind that industry adoption (e.g. everybody is talking about it) can differ from industry deployment (e.g. some people have actually paid for, deployed and using the technology) to broad customer adoption (e.g. many people are actually paying for, deploying and using the technology on a routine basis).
Confusion still reigns around Green IT not surprising given the heavy dose of Green Washing that has occurred.
Consequently Green IT themes or pitches often fall on deaf ears as people have either become numb or ignore the Green washing hype or FUD. For example many people will skip reading this post because the word Green is in the title assuming that it is another CO2 or related themed piece missing out on the other themes or messages here. Unfortunately as I have discussed in the past, there remains a Green Gap that results in missed opportunities for vendors, vars, service providers, IT organizations along with those who would like to see environmental benefits or change.
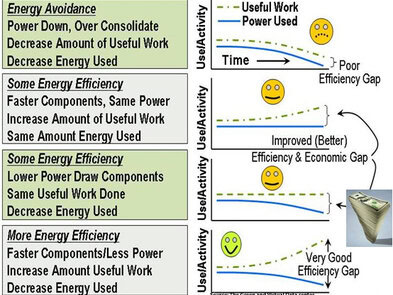
Another example of a Green gap is messaging around energy avoidance as being efficient vs. using energy in a more productive or effective manner (doing more work with the same or fewer resources) shown in the figure below.
In routine conversations with IT professionals it is clear that the Green Gap and thus missed opportunities will continue for some time until the business and economic values of efficient, effective, smart and productive IT are understood to have environmental benefits as a by product and thus being Green. Watch for more missed messaging around CO2 and related themes popular with so called Greenies (or if you prefer environmentalists) that miss the mark with most business and IT organizations.
Business and thus IT are driven by economics and as such will invest where they can reduce complexity and costs, become more efficient and effective while increasing productivity and reducing waste by working smarter. In other words, by changing how information services are delivered in a smarter more effective efficient manner maximizes what resources are used enabling more to be done in a denser footprint (budget, people staffing, management, power, cooling, floor space) that have positive environmental benefits. Put another way, a benefit for IT organizations to remove complexity results in lower costs, by becoming more efficient and effective reducing waste results in better productivity and fewer missed opportunities meaning enhanced profits. The net result is that environmental concerns get a free ride or being funded as a result of IT organizations improving their productivity which of course should have a business benefit.
Wheel of Opportunity: Various techniques and technologies for infrastructure optimization
Efficient and effective IT (aka the other Green IT) that links to common technology and business issues with the benefit of helping the environment can be accomplished using a combination approaches. The approaches for enabling an efficient, effective, smarter and productive IT environment includes from a generic perspective various technologies, techniques and best practices shown in the wheel of opportunity figure.
For example:
Best practices, policies and procedures, streamlined work flows
Metrics and measurements for end to end (E2E) management insight
Despite having been repeatedly declared dead at the hands of some new emerging technology over the past several decades, the Hard Disk Drive (HDD) continues to spin and evolve as it moves towards its 60th birthday.
More recently HDDs have been declared dead due to flash SSD that according to some predictions, should have caused the HDD to be extinct by now.
Meanwhile, having not yet died in addition to having qualified for its AARP membership a few years ago, the HDD continues to evolve in capacity, smaller form factor, performance, reliability, density along with cost improvements.
Back in 2006 I did an article titled Happy 50th, hard drive, but will you make it to 60?
IMHO it is safe to say that the HDD will be around for at least a few more years if not another decade (or more).
This is not to say that the HDD has outlived its usefulness or that there are not other tiered storage mediums to do specific jobs or tasks better (there are).
Instead, the HDD continues to evolve and is complimented by flash SSD in a way that HDDs are complimenting magnetic tape (another declared dead technology) each finding new roles to support more data being stored for longer periods of time.
What the importance of this is about technology tiering and resource alignment, matching the applicable technology to the task at hand.
Technology tiering (Servers, storage, networking, snow removal) is about aligning the applicable resource that is best suited to a particular need in a cost as well as productive manner. The HDD remains a viable tiered storage medium that continues to evolve while taking on new roles coexisting with SSD and tape along with cloud resources. These and other technologies have their place which ideally is finding or expanding into new markets instead of simply trying to cannibalize each other for market share.
Here is a link to a good story by Lucas Mearian on the history or evolution of the hard disk drive (HDD) including how a 1TB device that costs about $60 today would have cost about a trillion dollars back in the 1950s. FWIW, IMHO the 1 trillion dollars is low and should be more around 2 to 5 trillion for the one TByte if you apply common costs for management, people, care and feeding, power, cooling, backup, BC, DR and other functions.
IMHO, it is safe to say that the HDD is here to stay for at least a few more years (if not decades) or at least until someone decides to try a new creative marketing approach by declaring it dead (again).
All Comments, (C) and (TM) belong to their owners/posters, Other content (C) Copyright 2006-2026 Server StorageIO and UnlimitedIO. All Rights Reserved. StorageIO is a registered Trade Mark (TM) of Server StorageIO.
Data Footprint Reduction (DFR) is a collection of techniques, technologies, tools and best practices that are used to address data growth management challenges. Dedupe is currently the industry darling for DFR particularly in the scope or context of backup or other repetitive data.
However DFR expands the scope of expanding data footprints and their impact to cover primary, secondary along with offline data that ranges from high performance to inactive high capacity.
Consequently the focus of DFR is not just on reduction ratios, its also about meeting time or performance rates and data protection windows.
This means DFR is about using the right tool for the task at hand to effectively meet business needs, and cost objectives while meeting service requirements across all applications.
Examples of DFR technologies include Archiving, Compression, Dedupe, Data Management and Thin Provisioning among others.
All Comments, (C) and (TM) belong to their owners/posters, Other content (C) Copyright 2006-2026 Server StorageIO and UnlimitedIO. All Rights Reserved. StorageIO is a registered Trade Mark (TM) of Server StorageIO.

























{kind=link}