World Backup Day Reminder Don’t Be an April Fool Test Your Data Recovery

World Backup Day Reminder Don’t Be an April Fool Test Your Data Recovery.
March 31 is the annual world backup day to spotlight awareness around the importance of protecting your data and test your data recovery. The focus of world backup and recovery day spans from the largest enterprise and cloud service providers (e.g., super scalars) to the smallest SMB, SOHO, ROBO and home consumers (including your photos) or other valuable items.
Granted the technology, tools, techniques, trends will differ with a scope as well as scale.
However, the fundamental data protection approaches apply to all. That is, having multiple copies of different points in time spread across separate storage (systems, servers, devices, media, cloud services) as well as offsite (and off-line).
Why The Need For Data Protection And Recovery
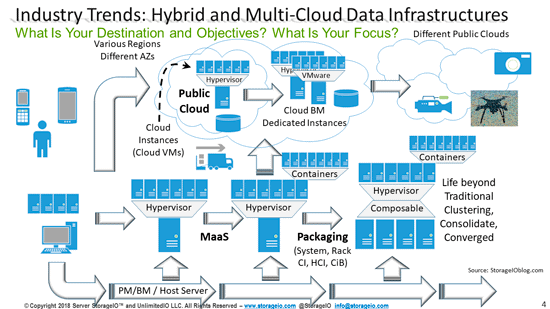
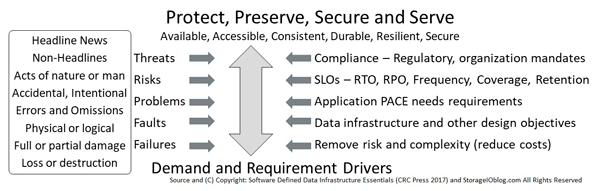
Data Protection encompasses many different things, from accessibility, durability, resiliency, reliability, and serviceability ( RAS) to security and data protection along with consistency. Availability includes basic, high availability ( HA), business continuance ( BC), business resiliency ( BR), disaster recovery ( DR), archiving, backup, logical and physical security, fault tolerance, isolation and containment spanning systems, applications, data, metadata, settings, and configurations.
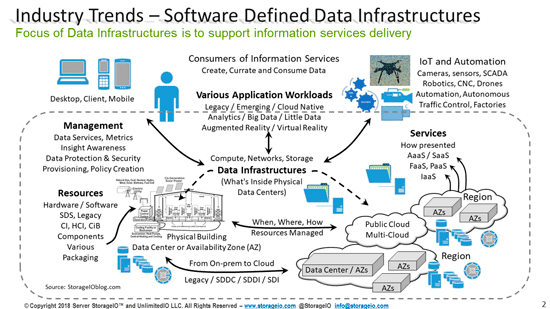
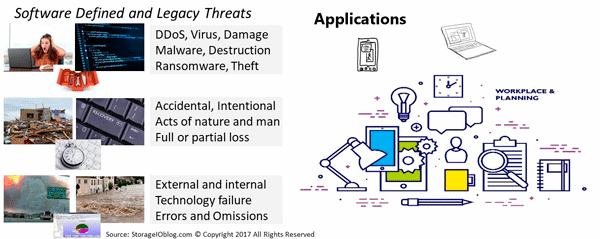
From a data infrastructure perspective, availability of data services spans from local to remote, physical to logical and software-defined, virtual, container, and cloud, as well as mobile devices. On the left side of the following figure are various data protection and security threat risks and scenarios that can impact availability, or result in a data loss event ( DLE), data loss access ( DLA), or disaster. The following figure shows various techniques, tools, technologies, and best practices to protect data infrastructures, applications, and data from threat risks.
Don’t Become An April 1st Recovery Fool
April 1st also known as April Fool’s day should be a reminder to plan as well as test your recovery, so the joke is not on you. Data protection including backup, archiving, security, disaster recovery (DR), business continuance (BC) as well as business resiliency (BR) are not a once a year focus, instead of a 365 day a year continuum. Likewise, the focus needs to expand from just making sure you backed up or made copies of your data to recover. After all, what good is a check box that you did a backup on world backup day only to find out the next day you cannot recover, or, what you thought was protected is not there.
If you already have good backups and data protection copies, verify that they are in fact good-by restoring their contents to a different location. It should go without saying, however all too often common sense needs to be repeated, make sure in the course of testing data protection including restoring that you do not inadvertently cause a disaster. Also, go a step beyond verifying that you can read the data stored on disk, tape, SSD, optical, that is, actually try to use, or open the data. What this does is verify that you can both access and restore the data from the protection medium or cloud location, as well as unlock, decrypt, uncompressed or re-inflate deduped data.
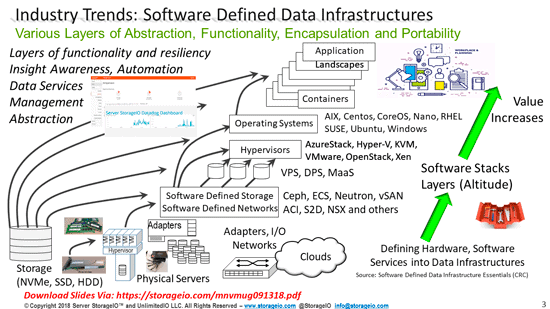
Evolving Data Protection Including Backup and Recovery
While the emphasis of world backup is on the importance of data protection including having backup copies, there also needs to be an emphasis on recovering. It is essential to make sure data is protected which means having multiple copies of different time intervals stored on several mediums or systems across one or more locations. The previous is the basis of 4 3 2 1 data protection, having four or more copies with three or more-time interval versions spread across two or more different systems or storage mediums.
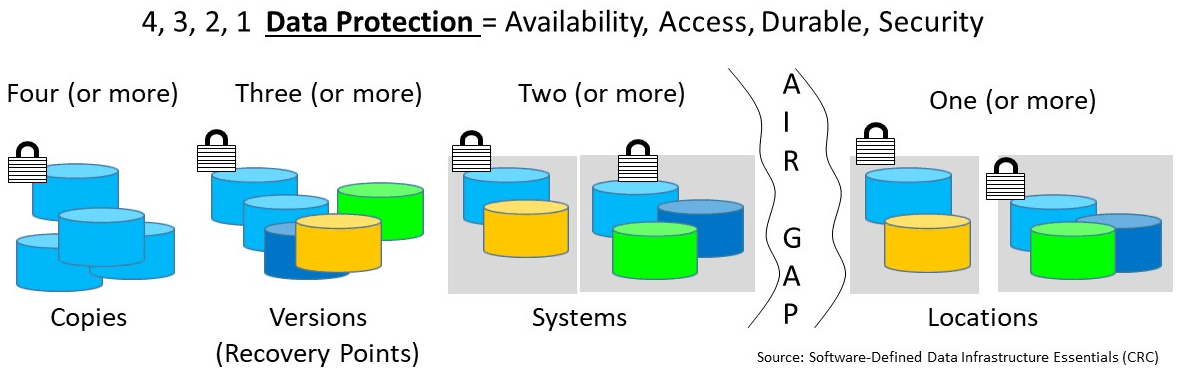
4 3 2 1 data protection (via Software Defined Data Infrastructure Essentials)
4 At least four copies of data (or more), Enables durability in case a copy goes bad, deleted, corrupted, failed device, or site.
3 The number (or more) versions of the data to retain, Enables various recovery points in time to restore, resume, restart from.
2 Data located on two or more systems (devices or media/mediums), Enables protection against device, system, server, file system, or other fault/failure.
1 With at least one of those copies being off-premise and not live (isolated from active primary copy), Enables resiliency across sites, as well as space, time, distance gap for protection.
Also, make sure that at least one of those offsite preferably offline. Likewise, it is crucial that whatever is protected, backed up, copied, cloned, snapshot, checkpoint, consistency point, replicated is also usable. In addition to having multiple copies and versions, those data protection copies should also include occurring at various altitude or layers in the data infrastructure stack from applications to database, file systems to virtual machines or containers among others.
What About Individual Data Protection at Home
For consumers and individuals, as well as small business, make sure that you are copying your essential data from your computer to some other storage medium (or multiple). For example, have a local copy on an external hard disk drive (HDD) or a solid-state device (SSD). Better yet, have a couple of copies for different time intervals both on-site as well as off-site. Anything important you have stored on site including copies of photos, images, video, audio, records, spreadsheets, and other documents should have extra copies including off-site or in the cloud.
Likewise, anything you store in the cloud should have at least one other copy stored elsewhere. Don’t be scared of the cloud, however, do your homework to be prepared. Similar to only having one copy of your data on site, the other extreme only has one copy in the cloud. Instead, put a copy in the cloud as well as have one on-site (or on-prem if you prefer) or elsewhere.
Don’t Forget Your Home Photos and Movies
Speaking of photos and other documents, for those that are not yet digitized, scanned or electronic copies made, get them converted. Get in touch with data protection and backup professional, as well as a photo (and digital asset) organizer. They can provide advice on best practices, techniques, as well as tools, technologies, and services to keep your digital data safe and secure. Some photo organizer professionals also can help with converting your old photos, movies, videos to new digital formats. For example, get in touch with Holly Corbid at Capture Your Photos (www.captureyourphotos.com) who is a certified professional photo organizer and member of Association of Professional Photo Organizers.
Where to learn more
Learn more about world backup day, recovery and data protection along with other related topics via the following links:
- Announcing My New Book Data Infrastructure Management Insight Strategies
- Only you can prevent cloud data loss
- World Backup Day, what about recovery
- The blame game: Does cloud storage result in data loss?
- World Backup Day 2018 Data Protection Readiness Reminder
- Data Protection Recovery Life Post World Backup Day Pre GDPR
- Virtual, Cloud and IT Availability, it’s a shared responsibility and common sense
- Data Protection Diaries Fundamental Topics Tools Techniques Technologies Tips
- Don’t Stop Learning Expand Your Skills Experiences Everyday #blogtobertech
- Data Infrastructure server storage I/O network Recommended Reading
- Data Infrastructure Overview, Its What’s Inside of a Data Center
- Application Data Value Characteristics Everything Is Not The Same (five-part mini-series)
- Application Data Availability 4 3 2 1 Data Protection (part of the mini-series)
- World Backup Day: Best Practices for a Hybrid Approach
- Data Protection Diaries Fundamental Topics Tools Techniques Technologies Tips
- Data Infrastructure Server Storage I/O related Tradecraft Overview
- Driving ROI with Cloud Storage Consolidation Seminars
- 4 3 2 1 and 3 2 1 data protection best practices
- GDPR (General Data Protection Regulation) Resources Are You Ready?
- Have you heard about the new CLOUD Act data regulation?
- What You Need to Know About Air Gaps and Ransomware
- Data Protection Diaries Fundamental Resources
- Which Enterprise HDD to use for a Content Server Platform
- The SSD Place (SSD, NVM, PM, SCM, Flash, NVMe, 3D XPoint, Optane, MRAM and related topics)
- The NVMe Place (NVMe related topics, trends, tools, technologies, tip resources
- Capture Your Photos and photo organizing service
- Check out my new site Pictures Over Stillwater with various content that relies on data infrastructures and data protection.
Additional learning experiences along with common questions (and answers), as well as tips can be found in Software Defined Data Infrastructure Essentials book.

What this all means
March 31 world backup day is more than an annual event for vendors to send out press releases on the importance of data protection. The focus should also expand to world recovery day or something similar as well as span 365 days a year. Now is a good time to review and verify your existing data protection including backup and recovery works as expected. Keep in mind, world backup day reminder don’t be an April fool test your data recovery before you need it.
Ok, nuff said, for now.
Cheers GS
Greg Schulz – Multi-year Microsoft MVP Cloud and Data Center Management, ten-time VMware vExpert. Author of Data Infrastructure Insights (CRC Press), Software Defined Data Infrastructure Essentials (CRC Press), as well as Cloud and Virtual Data Storage Networking (CRC Press), The Green and Virtual Data Center (CRC Press), Resilient Storage Networks (Elsevier) and twitter @storageio. Also visit www.picturesoverstillwater.com to view various UAS/UAV e.g. drone based aerial content created by Greg Schulz. Courteous comments are welcome for consideration. First published on https://storageioblog.com any reproduction in whole, in part, with changes to content, without source attribution under title or without permission is forbidden.
All Comments, (C) and (TM) belong to their owners/posters, Other content (C) Copyright 2006-2026 Server StorageIO and UnlimitedIO. Visit our companion site https://picturesoverstillwater.com to view drone based aerial photography and video related topics. All Rights Reserved. StorageIO is a registered Trade Mark (TM) of Server StorageIO.