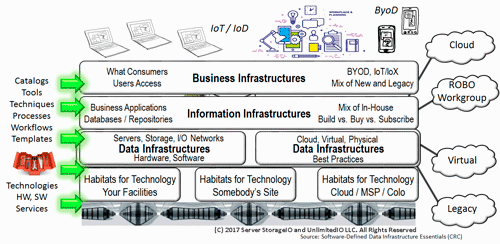
VMware vSphere vSAN vCenter v6.7 SDDC details

VMware vSphere vSAN vCenter v6.7 SDDC details of announcement summary focus on vCenter, Security, and management. This is part two (part one here) of a three-part (part III here) series looking at VMware vSphere vSAN vCenter v6.7 SDDC details of announcement summary.
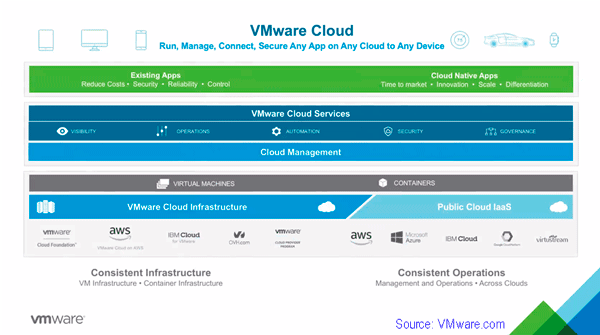
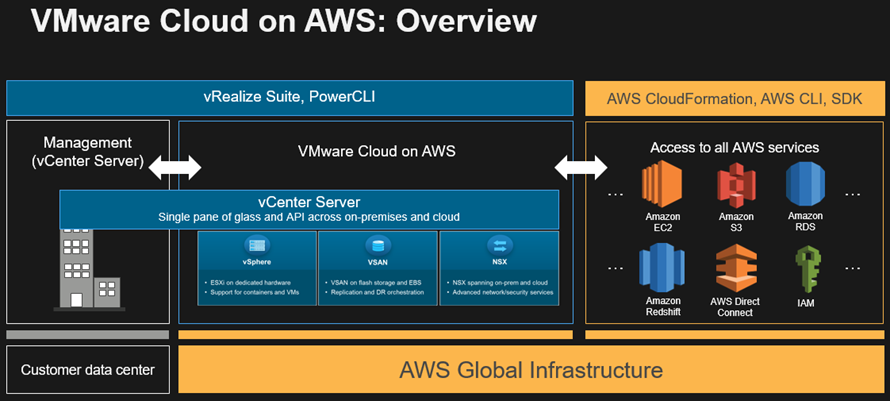
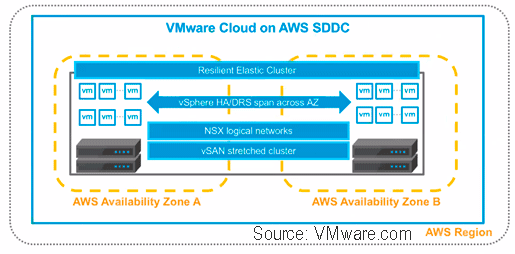
Last week VMware announced vSphere vSAN vCenter v6.7 updates as part of enhancing their software-defined data center (SDDC) and software-defined infrastructure (SDI) solutions core components. This is an expanded post as a companion to the Server StorageIO summary piece here. These April updates followed those from this past March when VMware announced cloud enhancements with partner AWS (more on that announcement here).
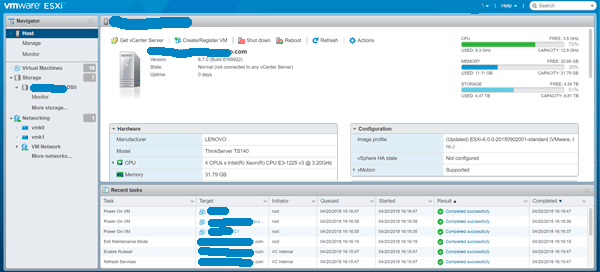
VMware vSphere Web Client with vSphere 6.7
What VMware announced is generally available (GA) meaning you can now download from here the bits (e.g., software) that include:
- ESXi aka vSphere 6.7 hypervisor build 8169922
- vCenter Server 6.7 build 8217866
- vCenter Server Appliance 6.7 build 8217866
- vSAN 6.7 and other related SDDC management tools
- vSphere Operations Management (vROps) 6.7
For those not sure or need a refresher, vCenter Server is the software for extended management across multiple vSphere ESXi hypervisors that run on a Windows platform.
Major themes of the VMware April announcements are focused around:
- Increased enterprise and hybrid cloud scalability
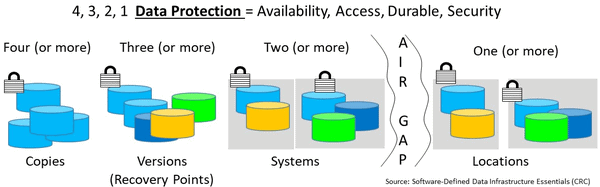
- Resiliency, availability, durable and secure
- Performance, efficiency and elastic
- Intuitive, simplified management at scale
- Expanded support for demanding application workloads
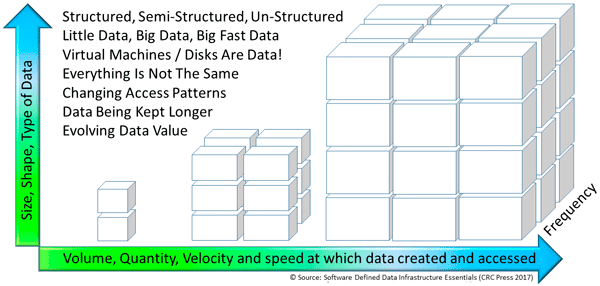
Expanded application support includes for traditional demanding enterprise IT, along with High-Performance Compute (HPC), Big Data, Little Data, Artificial Intelligence (AI), Machine Learning (ML) and Deep Learning (DL), as well as other emerging workloads. Part of supporting demanding workloads includes enhanced support for Graphical Processing Units (GPU)such as those from Nvidia among others.
What was announced
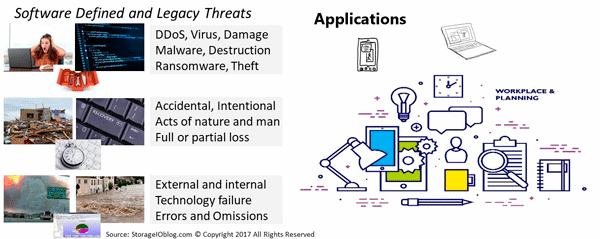
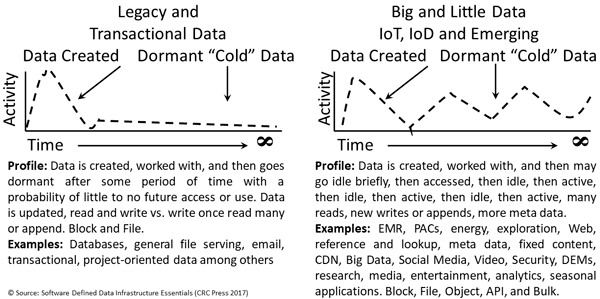
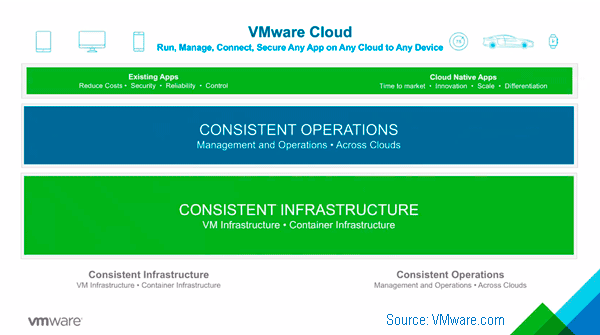
As mentioned above and in other posts in this series, VMware announced new versions of their ESXi hypervisor vSphere v6.7, as well as virtual SAN (vSAN) v6.7, virtual Center (vCenter), v6.7 among other related tools. One of the themes of this announcement by VMware includes hybrid SDDC spanning on-site, on-premises (or on-premisess if you prefer) to the public cloud. Other topics involve increasing scalability, along with stability as well as ease of management along with security, performance updates.
As part of the v6.7 enhancements, VMware is focusing on simplifying, as well as accelerating software-defined data infrastructure along with other SDDC lifecycle operation activities. Additional themes and features focus on server, storage, I/O resource enablement, as well as application extensibility support.
vSphere ESXi hypervisor
With v6.7 ESXi host maintenance times improved with single reboot vs. previous multiple boots for some upgrades, as well as quick boot. Quick boot enables restarting the ESXi hypervisor without rebooting the physical machine skipping time-consuming hardware initialization.
Enhanced HTML5 based vSphere client GUI (along with API and CLI) with increased feature function parity compared to predecessor versions and other VMware tools. Increased functionality includes NSX, vSAN and VMware Upgrade Management (VUM) capabilities among others. In other words, not only are new technologies support, functions you may have in the past resisted using the web-based interfaces due to extensibility are being addressed with this release.
vCenter Server and vCenter Server Appliance (VCSA)
VMware has announced that moving forward the hosted (e.g., running on a Windows server platform) version is being depreciated. What this means is that it is time for those not already doing so to migrate to the vCenter Server Appliance (VCSA). As a refresher, VCSA is a turnkey software-defined virtual appliance that includes vCenter Server software running on VMware Photon Linux operating system as a virtual machine. VMware vCenter.
As part of the update, the enhanced vCenter Server Appliance (VCSA) supports new efficient, effective API management along with multiple vCenters as well as performance improvements. VMware cites 2x faster vCenter operations per second, 3x reduction in memory usage along with 3x quicker Distributed Resource Scheduler (DRS) related activities across powered on VMs).
What this means is that VCSA is a self-contained virtual appliance that can be configured for very large, large, medium and small environments in various configurations. With v6.7 vCenter Server Appliance emphasis on scaling, as well as performance along with security and ease of use features, VCSA is better positioned to support large enterprise deployments along with hybrid cloud. VCSA v6.7 is more than just a UI enhancement with v6.5 shown below followed by an image of v6.7 UI.

VMware vCenter Appliance v6.5 main UI
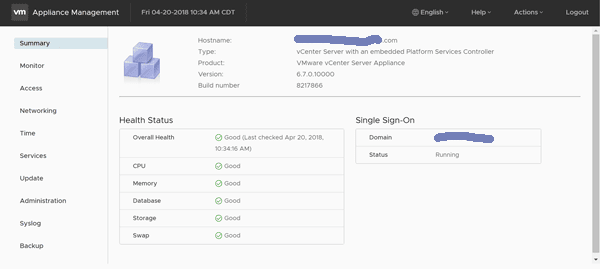
VMware vCenter Appliance v6.7 main UI
Besides UI enhancements (along with API and CLI) for vCenter, other updates include more robust data protection (aka backup) capability for the vCenter Server environment. In the prior v6.5 version there was a fundamental capability to specify a destination for sending vCenter configuration information to for backup data protection (See image below).
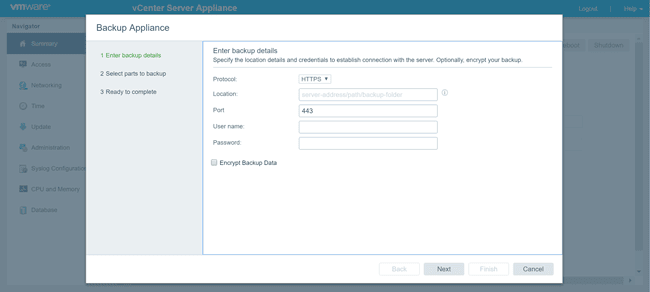
VMware vCenter Appliance 6.5 backup
Note that the VCSA backup only provides data protection for the vCenter Appliance, its configuration, settings along with data collected of the VMware hosts (and VMs) being managed. VCSA backup does not provide data protection of the individual VMware hosts or VMs which is accomplished via other data protection techniques, tools and technologies.
In v6.7 vCenter now has enhanced capabilities (shown below) for enabling data protection of configuration, settings, performance and other metrics. What this means is that with improved UI it is now possible to setup backup schedules as part of enabling automation for data protection of vCenter servers.
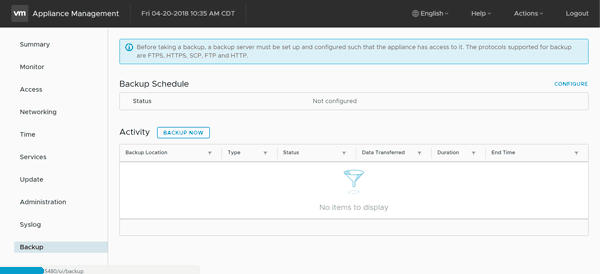
VMware VCSA v6.7 enhanced UI and data protection aka backup
The following shows some of the configuration sizing options as part of VCSA deployment. Note that the vCPU, Memory, and Storage are for the VCSA itself to support a given number of VMware hosts (e.g., physical machines) as well as guest virtual machines (VM).
| VCSA | VCSA | VCSA | VM |
|
Size | vCPU | Memory | Storage | Hosts | VMs |
Tiny | 2 | 10GB | 300GB | 10 | 100 |
Small | 4 | 16GB | 340GB | 100 | 1000 |
Medium | 8GB | 24 | 525GB | 400 | 4000 |
Large | 16 | 32GB | 740GB | 1000 | 10000 |
Extra Large | 24 | 48GB | 1180GB | 2000 | 35000 |
vCenter 6.7 sizing and number of the physical machine (e.g., VM hosts) and virtual machines supported
Keep in mind that in addition to the above individual VCSA configuration limits, multiple vCenters can be grouped including linked mode spanning onsite, on-premisess (on-prem if you prefer) as well as the cloud. VMware vCenter server hybrid linked mode enables seamless visibility and insight across on-site, on-premises (or on-premisess if you prefer) as well as public clouds such as AWS among others.
In other words, vCenter with hybrid linked mode enables you to have situational awareness and avoid flying blind in and among clouds. As part of hybrid vCenter environment support, cross-cloud (public, private) hot and cold migration including clone as well as vMotion across mixed VMware version provisioning is supported. Using linked mode multiple roles, permissions, tags, policies can be managed across different groups (e.g., unified management) as well as locations.
VMware and vSphere Security
Security is a big push for VMware with this release including Trusted Platform Module (TPM) 2.0 along with Virtual TPM 2.0 for protecting both the hypervisors and guest operating systems. Data encryption was introduced in vSphere 6.5 and is enhanced with increased management simplicities along with protection of data at rest and in flight (while in motion).
In other words, encrypted vMotion across different vCenter instances and versions are supported, as well as across hybrid environments (e.g., on-premises and public cloud). Other security enhancements include tighter collaboration and integration with Microsoft for Windows VMs, as well as vSAN, NSX and vRealize for a secure software-defined data infrastructure aka SDDC. For example, VMware has enhanced support for Microsoft Virtualization Based Security (VBS) including credential Guard where vSphere is providing a secure virtual hardware platform.
Additional VMware 6.7 security enhancements include Multiple SYSLOG targets, FIPS 140-2 Validated modules. Note that there is a difference between FIPS certified and FIPS validated, of which VMware vCenter and ESXi leverage two modules (VM Kernel Cryptographic, and OpenSSL) are currently validated. VMware is not playing games like some vendors when it comes to disclosing FIPS 140-2 validated vs. certified. Other VMware security enhancements include
Note, when a vendor mentions FIPS 140-2 and imply or says certified, ask them if they indeed are certified. Any vendor who is actually FIPS 140-2 certified should not get upset if you press them politely. Instead, they should thank you for asking. Otoh, if a vendor gives you a used car salesperson style dance or get upset, ask them why so sensitive, or, perhaps, what are they ashamed of or hiding, just saying. Learn more here.
vRealize Operations Manager (vROps)
vRealize Operations Manager (vROps) v6.7 dashboard for vSphere client plugin provides an overview of cluster view and alerts of both vCenter and vSAN. What this means is that you will want to upgrade vROps to v6.7. The vROps benefit being dashboards for optimal performance, capacity, troubleshooting, and management configuration.
Where to learn more
Learn more about VMware vSphere, vCenter, vSAN and related software-defined data center (SDDC); software-defined data infrastructures (SDDI) topics via the following links:
- Part one here, part two here and part three here of this announcement summary series
- VMware vSphere ESXi vCenter 6.7 release notes and launch announcement
- VMware vSphere (ESXi) 6.7 and vCenter 6.7 overviews
- VMware configuration maximums
- VMware continues cloud construction with March announcements
- Travel Fun Crossword Puzzle For VMworld 2017 Las Vegas
- Hot Popular New Trending Data Infrastructure Vendors To Watch
- Data Infrastructure server storage I/O network Recommended Reading
- Data Infrastructure Overview, Its What’s Inside of Data Centers
Additional learning experiences along with common questions (and answers), as well as tips can be found in Software Defined Data Infrastructure Essentials book.

What this all means and wrap-up
VMware continues to enhance their core SDDC data infrastructure resources to support new and emerging, as well as legacy enterprise applications at scale. VMware enhancements include management, security along with other updates to support the demanding needs of various applications and workloads, along with supporting application developers.
Some examples of demanding workloads include among others AL, Big Data, Machine Learning, In memory and high-performance compute (HPC) among other resource-intensive new workloads, as well as existing applications. This includes enhanced support for Nvidia physical and virtual Graphical Processing Units (GPU) that are used in support for compute-intensive graphics, as well as non-graphic processing (e.g., AI, ML) workloads.
With the v6.7 announcements, VMware is providing proof points that they are continuing to invest in their core SDDC enabling technologies. VMware is also demonstrating the evolution of vSphere ESXi hypervisor along with associated management tools for hybrid environments with ease of use management at scale, along with security. View more about VMware vSphere vSAN vCenter v6.7 SDDC details in part three of this three-part series here ((focus on server storage I/O, deployment information and analysis).
Ok, nuff said, for now.
Cheers Gs
Greg Schulz – Microsoft MVP Cloud and Data Center Management, VMware vExpert 2010-2017 (vSAN and vCloud). Author of Software Defined Data Infrastructure Essentials (CRC Press), as well as Cloud and Virtual Data Storage Networking (CRC Press), The Green and Virtual Data Center (CRC Press), Resilient Storage Networks (Elsevier) and twitter @storageio. Courteous comments are welcome for consideration. First published on https://storageioblog.com any reproduction in whole, in part, with changes to content, without source attribution under title or without permission is forbidden.
All Comments, (C) and (TM) belong to their owners/posters, Other content (C) Copyright 2006-2026 Server StorageIO and UnlimitedIO. All Rights Reserved. StorageIO is a registered Trade Mark (TM) of Server StorageIO.