EMCworld 2015 How Do You Want Your Storage Wrapped?
Back in early May I was invited by EMC to attend EMCworld 2015 which included both the public sessions, as well as several NDA based discussions. Keep in mind that there is the known, there is the unknown (or assumed or speculated) and in between there are NDA’s, nuff said on that. EMC covered my hotel and registration costs to attend the event in Las Vegas (thanks EMC, that’s a disclosure btw ;) and here is a synopsis of various EMCworld 2015 announcements.
What EMC announced
- VMAX3 enhancements to the EMC enterprise flagship storage platform to keep it relevant for traditional legacy workloads as well as for in a converged, scale-out, cloud, virtual and software defined environment.
- VNX 3200 entry-level All Flash Array (AFA) flash SSD system starting at $25,000 USD for a 3TB unified platform with full data services found in other VNX products.
- vVNX aka Virtual VNX aka "project liberty" which is a community (e.g. free) software version of the VNX. vVNX is a Virtual Storage Appliance (VSA) that you download and run on a VMware platform. Learn more and download here. Note the install will do a CPU type check so forget about trying to run it on a Intel Nuc or similar, I tried just because I could, the install will protect you from doing such things.
- Various data protection related items including new Datadomain platforms as well as software updates and integration with other EMC platforms (storage systems).
- All Flash Array (AFA) XtremIO 4.0 enhancements including larger clusters, larger nodes to boost performance, capacity and availability, along with copy service updates among others improvements.
- Preview of DSSD shared (inside a rack) external flash Solid State Device (SSD) including more details. While much of DSSD is still under NDA, EMC did provide more public details at EMCworld. Between what was displayed and announced publicly at EMCworld as well as what can be found via Google (or other searches) you can piece together more of the DSSD story. What is known publicly today is that DSSD leverages the new Non-Volatile Memory express (NVMe) access protocol built upon underlying PCIe technology. More on DSSD in future discussions,if you have not done so, get an NDA deep dive briefing on it from EMC.
- ScaleIO is now available via a free download here including both Windows and Linux clients as well as instructions for those operating systems as well as VMware.
- ViPR can also be downloaded here for free (has been previously available) from here as well as it has been placed into open source by EMC.
What EMC announced since EMCworld 2015
- Acquisition of cloud services (and software tools) vendor Virtustream for $1.2B adding to the federation cloud services portfolio (companion to VMware vCloud Air).
- Release of ECS 2.0 including a free download here. This new version of ECS (Elastic Cloud Storage) can be used independent of the ViPR controller, or in conjunction with ViPR. In addition ECS now has about 80% of the functionality of the Centera object storage platform. The remaining 20% functionality (mainly regulatory compliance governance) of Centera will be added to ECS in the future providing a migration path for Centera customers. In case you are wondering what does EMC do with Centera, Atmos, ViPR and now ECS, answer is that ECS can work with or without ViPR, second is that the functionality of Centera, Atmos are being rolled into ECS. ECS as a refresher is software that transforms general purpose industry standard servers with direct storage into a scale-out HDFS and object storage solution.
- Check out EMCcode including S3motion that I use and have reviewed here. Also check out EMCcode Rex-Ray which if you are into docker containers, it should be of interest, I know I’m interested in it.
What this all means and wrap-up
There were no single major explosive announcements however the sum of all the announcements together should not be over shadowed by the big tent made for TV (or web) big tent productions and entertainment. What EMC announced was effectively how would you like, how do you want and need your storage and associated data services along with management wrapped.

By being wrapped, do you want your software defined storage management and storage wrapped in a legacy turnkey solution such as VMAX3, VNX or Isilon, do you want or need it to be hybrid or all flash, converged and unified, block, file or object.

Or do you need or want the software defined storage management and storage to be "shrink wrapped" as a download so you can deploy on your own hardware "tin wrapped" or as a VSA "virtual wrapped" or cloud wrapped? Do you need or want the software defined storage management and storage to leverage anybody’s hardware while being open source?
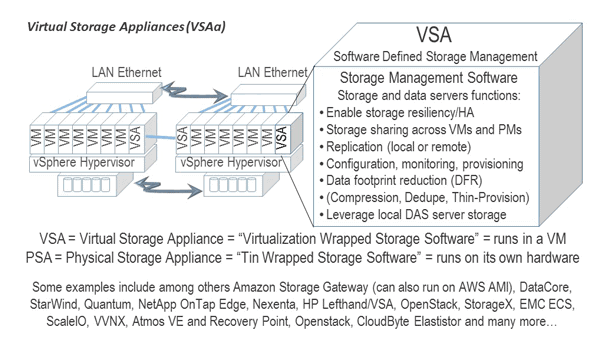
How do you need or want your storage to be wrapped to fit your specific needs, that IMHO was the essence of what EMC announced at EMCworld 2015, granted the motorcycles and other production entertainment was engaging as well as educational.
Ok, nuff said for now
Cheers
Gs
Greg Schulz – Author Cloud and Virtual Data Storage Networking (CRC Press), The Green and Virtual Data Center (CRC Press) and Resilient Storage Networks (Elsevier)
twitter @storageio
All Comments, (C) and (TM) belong to their owners/posters, Other content (C) Copyright 2006-2026 Server StorageIO and UnlimitedIO LLC All Rights Reserved