Clustered storage can be iSCSI, Fibre Channel block based or NAS (NFS or CIFS or proprietary file system) file system based. Clustered storage can also be found in virtual tape library (VTL) including dedupe solutions along with other storage solutions such as those for archiving, cloud, medical or other specialized grids among others.
Recently in the IT and data storage specific industry, there has been a flurry of merger and acquisition (M&A) (Here and here), new product enhancement or announcement activity around clustered storage. For example, HP buying clustered file system vendor IBRIX complimenting their previous acquisition of another clustered file system vendor (PolyServe) a few years ago, or, of iSCSI block clustered storage software vendor LeftHand earlier this year. Another recent acquisition is that of LSI buying clustered NAS vendor ONstor, not to mention Dell buying iSCSI block clustered storage vendor EqualLogic about a year and half ago, not to mention other vendor acquisitions or announcements involving storage and clustering.
Where the confusion enters into play is the term cluster which means many things to different people, and even more so when clustered storage is combined with NAS or file based storage. For example, clustered NAS may infer a clustered file system when in reality a solution may only be multiple NAS filers, NAS heads, controllers or storage processors configured for availability or failover.
What this means is that a NFS or CIFS file system may only be active on one node at a time, however in the event of a failover, the file system shifts from one NAS hardware device (e.g. NAS head or filer) to another. On the other hand, a clustered file system enables a NFS or CIFS or other file system to be active on multiple nodes (e.g. NAS heads, controllers, etc.) concurrently. The concurrent access may be for small random reads and writes for example supporting a popular website or file serving application, or, it may be for parallel reads or writes to a large sequential file.
Clustered storage is no longer exclusive to the confines of high-performance sequential and parallel scientific computing or ultra large environments. Small files and I/O (read or write), including meta-data information, are also being supported by a new generation of multipurpose, flexible, clustered storage solutions that can be tailored to support different applications workloads.
There are many different types of clustered and bulk storage systems. Clustered storage solutions may be block (iSCSI or Fibre Channel), NAS or file serving, virtual tape library (VTL), or archiving and object-or content-addressable storage. Clustered storage in general is similar to using clustered servers, providing scale beyond the limits of a single traditional system—scale for performance, scale for availability, and scale for capacity and to enable growth in a modular fashion, adding performance and intelligence capabilities along with capacity.
For smaller environments, clustered storage enables modular pay-as-you-grow capabilities to address specific performance or capacity needs. For larger environments, clustered storage enables growth beyond the limits of a single storage system to meet performance, capacity, or availability needs.
Applications that lend themselves to clustered and bulk storage solutions include:
- Unstructured data files, including spreadsheets, PDFs, slide decks, and other documents
- Email systems, including Microsoft Exchange Personal (.PST) files stored on file servers
- Users’ home directories and online file storage for documents and multimedia
- Web-based managed service providers for online data storage, backup, and restore
- Rich media data delivery, hosting, and social networking Internet sites
- Media and entertainment creation, including animation rendering and post processing
- High-performance databases such as Oracle with NFS direct I/O
- Financial services and telecommunications, transportation, logistics, and manufacturing
- Project-oriented development, simulation, and energy exploration
- Low-cost, high-performance caching for transient and look-up or reference data
- Real-time performance including fraud detection and electronic surveillance
- Life sciences, chemical research, and computer-aided design
Clustered storage solutions go beyond meeting the basic requirements of supporting large sequential parallel or concurrent file access. Clustered storage systems can also support random access of small files for highly concurrent online and other applications. Scalable and flexible clustered file servers that leverage commonly deployed servers, networking, and storage technologies are well suited for new and emerging applications, including bulk storage of online unstructured data, cloud services, and multimedia, where extreme scaling of performance (IOPS or bandwidth), low latency, storage capacity, and flexibility at a low cost are needed.
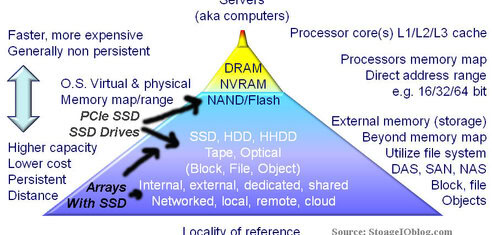
The bandwidth-intensive and parallel-access performance characteristics associated with clustered storage are generally known; what is not so commonly known is the breakthrough to support small and random IOPS associated with database, email, general-purpose file serving, home directories, and meta-data look-up (Figure 1). Note that a clustered storage system, and in particular, a clustered NAS may or may not include a clustered file system.

Figure 1 – Generic clustered storage model (Courtesy “The Green and Virtual Data Center (CRC)”
More nodes, ports, memory, and disks do not guarantee more performance for applications. Performance depends on how those resources are deployed and how the storage management software enables those resources to avoid bottlenecks. For some clustered NAS and storage systems, more nodes are required to compensate for overhead or performance congestion when processing diverse application workloads. Other things to consider include support for industry-standard interfaces, protocols, and technologies.
Scalable and flexible clustered file server and storage systems provide the potential to leverage the inherent processing capabilities of constantly improving underlying hardware platforms. For example, software-based clustered storage systems that do not rely on proprietary hardware can be deployed on industry-standard high-density servers and blade centers and utilizes third-party internal or external storage.
Clustered storage is no longer exclusive to niche applications or scientific and high-performance computing environments. Organizations of all sizes can benefit from ultra scalable, flexible, clustered NAS storage that supports application performance needs from small random I/O to meta-data lookup and large-stream sequential I/O that scales with stability to grow with business and application needs.
Additional considerations for clustered NAS storage solutions include the following.
- Can memory, processors, and I/O devices be varied to meet application needs?
- Is there support for large file systems supporting many small files as well as large files?
- What is the performance for small random IOPS and bandwidth for large sequential I/O?
- How is performance enabled across different application in the same cluster instance?
- Are I/O requests, including meta-data look-up, funneled through a single node?
- How does a solution scale as the number of nodes and storage devices is increased?
- How disruptive and time-consuming is adding new or replacing existing storage?
- Is proprietary hardware needed, or can industry-standard servers and storage be used?
- What data management features, including load balancing and data protection, exists?
- What storage interface can be used: SAS, SATA, iSCSI, or Fibre Channel?
- What types of storage devices are supported: SSD, SAS, Fibre Channel, or SATA disks?
As with most storage systems, it is not the total number of hard disk drives (HDDs), the quantity and speed of tiered-access I/O connectivity, the types and speeds of the processors, or even the amount of cache memory that determines performance. The performance differentiator is how a manufacturer combines the various components to create a solution that delivers a given level of performance with lower power consumption.
To avoid performance surprises, be leery of performance claims based solely on speed and quantity of HDDs or the speed and number of ports, processors and memory. How the resources are deployed and how the storage management software enables those resources to avoid bottlenecks are more important. For some clustered NAS and storage systems, more nodes are required to compensate for overhead or performance congestion.
Learn more about clustered storage (block, file, VTL/dedupe, archive), clustered NAS, clustered file system, grids and cloud storage among other topics in the following links:
"The Many faces of NAS – Which is appropriate for you?"
Article: Clarifying Storage Cluster Confusion
Presentation: Clustered Storage: “From SMB, to Scientific, to File Serving, to Commercial, Social Networking and Web 2.0”
Video Interview: How to Scale Data Storage Systems with Clustering
Guidelines for controlling clustering
The benefits of clustered storage
Along with other material on the StorageIO Tips and Tools or portfolio archive or events pages.
Ok, nuff said.
Cheers gs
Greg Schulz – Author Cloud and Virtual Data Storage Networking (CRC Press), The Green and Virtual Data Center (CRC Press) and Resilient Storage Networks (Elsevier)
twitter @storageio
All Comments, (C) and (TM) belong to their owners/posters, Other content (C) Copyright 2006-2026 Server StorageIO and UnlimitedIO LLC All Rights Reserved









{kind=link}