
Some popular 2016 storageioblog posts

Big Files and Lots of Little File Processing and Benchmarking with Vdbench – Need to test, validate, compare, contrast or simply apply workload to file systems, NAS or other file-based access? Want the flexibility and simplicity to software define your benchmark workload to meet various needs? For example, millions of small files or thousands of large 5GB, 10GB, 15GB (or larger) files with various read, write size and access patterns spanning a single directory, or many with various depths? Do you want the flexibility for different platforms including Windows, *NIX, bare metal, container, virtual or cloud without a bulk tool using simple scripts that produce lots of insightful results? Then you will want to check this post out.
Breaking the VMware ESXi 5.5 ACPI boot loop on Lenovo TD350 – Ever have a VMware host server go into a boot loop and purple screen of death (PSD) then displaying a message about ACPI or similar? After spending time searching and applying many filters to sift through the noise of false positive matches, finally found the simple fix (e.g. a BIOS setting) to break the VMware ESXi vSphere boot loop, or at least on a Lenovo server.

Cloud conversations: AWS EBS, Glacier and S3 overview (Part I) – This is one of the perennial favorites that while new features have been added with others extended, the post series still provides a good overview, primer or refresher of various Amazon Web Services (AWS) services including how they work. Interesting in learning more about Microsoft and Azure, then check out this, this, this and this.
Cloud Conversations: AWS EFS Elastic File System (Cloud NAS) – This is a companion to the above AWS as well as other cloud post series that looks at AWS Elastic File System. Note that other cloud service providers have also added NAS file access support, some are intra (e.g. inside AWS cloud), others are inter-cloud (e.g. inside and outside cloud) such as Azure (can work with external Windows Servers using SMB3). Even OpenStack has added NAS file with Manila folders and Ceph with CephFS among others. So when some people tell you that NAS and file access are dead particular for cloud, remind them of the increasing number of services and software stacks that are adding new services to allow their solution to be compatible with existing environments or applications.

Collecting Transaction Per Minute from SQL Server and HammerDB – If you have used the free tool HammerDB (e.g. Hammora) for driving database workloads, simulations or benchmarks you should recall that the resulting statistics are rather lacking. Sure there is a nice GUI chart that shows current executing transactions per second (TPS) along with some very simple counters in the log. However compared to some other tools such as sysbench, Quest Benchmark Factory and YCSB among others, the Hammer metrics are rather lacking. In this post I show how you can collect some more metrics from SQL Server if you have to use HammerDB. View more server storage I/O performance benchmark and monitoring tools resources here.

Gaining Server Storage I/O Insight into Microsoft Windows Server 2016 – Microsoft released into general availability Windows Server 2016 and this post looks at some of the new features along with functionality including Storage Spaces Direct (S2D), Storage Replica (SR) as well as other enhancements. With these new and enhanced features Windows Servers increase their interoperability with Azure, as well as supporting aggregated hyper-converged infrastructure (HCI), disaggregated converged (CI) as well as traditional workloads along with Hyper-V (and containers). One of the other new enhancements in Windows Server 2016 which now uses ReFS (Reliable File System) as its default file system that you can read more about here. RIP Windows SIS (Single Instance Storage), or at least in Server 2016 With Windows Server 2016 Microsoft removed single instance storage replacing with new capabilities that you can read more about in the this post.

Garbage data in, garbage information out, big data or big garbage? There is a classic IT expression of garbage data in results in garbage data (or information out) in that your algorithms and data structures (which equals programs e.g. Niklaus Wirth) are only as good as the data they work on. What this means then is that if there is a large amount of big data then there can also be a big garbage in and garbage out problem unless addressed.
Hard product vs. soft product – Hard product refers to something such as hardware, software or a service resource that is obtained and then joined with other resources in a particular way to create a soft product. Not to be confused with software, the soft product is the result or how resources get defined that give some ability or benefit. Think of a soft product as for how airlines can use the same airplane, serve the same coca cola, have same seats, yet their soft product is the service experience of how those are delivered, as well as how you find and buy or use them. Another way of thinking about it is hard products are the ingredients for a recipe, the recipe defines how those ingredients result in some food dish.

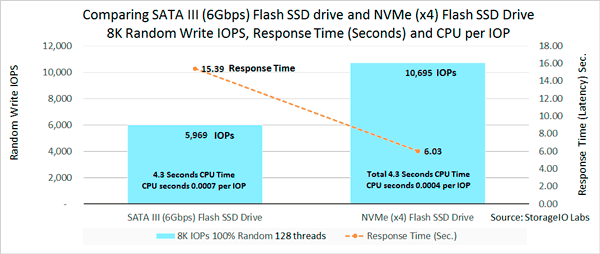
Part II: How many IOPS can a HDD, HHDD or SSD do with VMware? – This is part of a multi-post series looking at how many IOPs (or bandwidth) various HDD and SSDs can do handling different workloads. Of course, your results will vary with configuration settings, tools among other considerations. However, some of the older rules of thumb (RUT) about RPM and other considerations for HDDs have changed and continue to do so. As an example of how HDDs continue to evolve check out this popular post from the 2016 list Which Enterprise HDDs to use for a Content Server Platform.
Part II: What I did with Lenovo TS140 in my Server and Storage I/O Review – This is a popular post series of some things I have done with a Lenovo TS140 including defining with various software as well as hardware. This is a great price performer value system that several years ago after testing one Lenovo sent me, I returned that to Lenovo and bought several of them to join my other systems.
Server and Storage I/O Benchmarking and Performance Resources – This is a collection of various server, storage I/O and networking hardware, software as well as services tools, techniques as well as tips for benchmarking, comparing, simulation, testing, gaining insight across cloud, virtual, container and legacy resources. Server and Storage I/O Benchmark Tools: Microsoft Diskspd (Part I) – This is one of the tools found on the server, storage I/O benchmarking and performance resources page. Diskspd is a tool developed by Microsoft as an alternative to using Iometer, vdbench, fio.exe, SQLIO among many others, plus, it is on github.

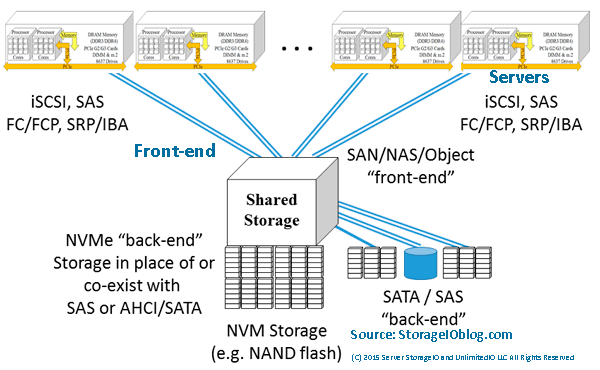
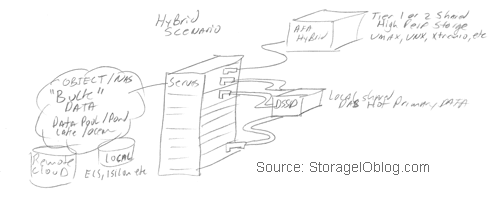
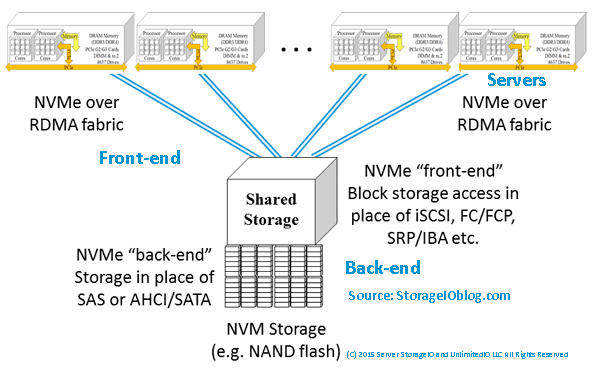
The NVM (Non Volatile Memory) and NVMe Place – Interesting and adoption in nand flash, nvram, 3D XPoint among other SSD and Non-volatile Memory (NVM) continues. Another popular post that you can find at thenvmeplace.com is this NVMe overview and primer – Part I. There is a growing interest, awareness and deployment adoption around NVM Express (NVMe) the new protocol for accessing NVMs and SSDs. Some of the common conversations and questions I encounter is confusion between NVM and NVMe, too which the answer is one (the former) are the media or devices, the other is the access method alternative to using AHCI/SATA or SCSI (e.g. SAS, iSCSI, FCP, SRP) among others.
VMware VVOLs and storage I/O fundamentals (Part 1) – VMware Virtual Volumes (VVOL) continue to gain adoption and this post is part of an overview and primer. If you want to go deeper into VVOL as well as see some adoption insights check out Eric Sieberts post here over at vsphere-land.com
Welcome to the Object Storage Center page – This is a micro site that has a primer and overview of cloud as well as object storage along with an expanding list of links to various resources, tips, technologies, tools, trends and industry activity.
Where To Learn More
www.storageio.com particular if you have not been there for awhile to check out the new streamlined look and navigation to various content including Server StorageIO update newsletters (free subscription) among other resources.
Additional learning experiences along with common questions (and answers), as well as tips can be found in Software Defined Data Infrastructure Essentials book.

What this all means and wrapping up
Some of the popular posts for 2016 are perennial favorites and based on experience will probably appear on the 2017 list. However there are also several new posts that appeared in 2016 that I suspect will also appear on the 2017 version of the above list, along with new content from 2017.
Thank you to all of you who frequent StorageIOblog.com as well as StorageIO.com along with our various micro sites including server storage I/O performance and benchmarking resources, thenvmeplace.com, thessdplace.com, cloud and objectstoragecenter.com, data protection diaries among others.
Also thank you for viewing various partner venues and syndicates with extra ones appearing throughout 2017. Watch for more content in the coming weeks, months and throughout 2017 on software defined data infrastructures (SDDI) along with server, storage I/O, networking, hardware, software, cloud, container, data protection and related topics, trends, technologies, tools and tips.
Again, thank you
Ok, nuff said, for now.
Gs
Greg Schulz – Microsoft MVP Cloud and Data Center Management, VMware vExpert 2010-2017 (vSAN and vCloud). Author of Software Defined Data Infrastructure Essentials (CRC Press), as well as Cloud and Virtual Data Storage Networking (CRC Press), The Green and Virtual Data Center (CRC Press), Resilient Storage Networks (Elsevier) and twitter @storageio. Courteous comments are welcome for consideration. First published on https://storageioblog.com any reproduction in whole, in part, with changes to content, without source attribution under title or without permission is forbidden.
All Comments, (C) and (TM) belong to their owners/posters, Other content (C) Copyright 2006-2026 Server StorageIO and UnlimitedIO. All Rights Reserved. StorageIO is a registered Trade Mark (TM) of Server StorageIO.


































{kind=link}