Application Data Availability 4 3 2 1 Data Protection

Application Data Availability 4 3 2 1 Data Protection
This is part two of a five-part mini-series looking at Application Data Value Characteristics everything is not the same as a companion excerpt from chapter 2 of my new book Software Defined Data Infrastructure Essentials – Cloud, Converged and Virtual Fundamental Server Storage I/O Tradecraft (CRC Press 2017). available at Amazon.com and other global venues. In this post, we continue looking at application performance, availability, capacity, economic (PACE) attributes that have an impact on data value as well as availability.

Availability (Accessibility, Durability, Consistency)
Just as there are many different aspects and focus areas for performance, there are also several facets to availability. Note that applications performance requires availability and availability relies on some level of performance.
Availability is a broad and encompassing area that includes data protection to protect, preserve, and serve (backup/restore, archive, BC, BR, DR, HA) data and applications. There are logical and physical aspects of availability including data protection as well as security including key management (manage your keys or authentication and certificates) and permissions, among other things.
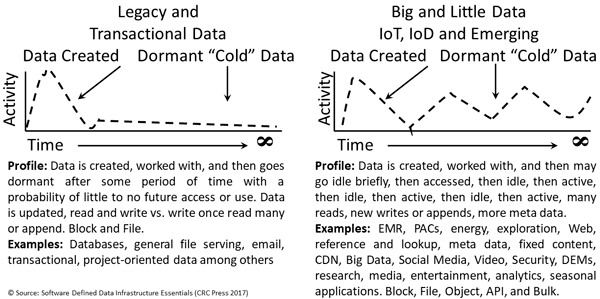
Availability = accessibility (can you get to your application and data) + durability (is the data intact and consistent). This includes basic Reliability, Availability, Serviceability (RAS), as well as high availability, accessibility, and durability. “Durable” has multiple meanings, so context is important. Durable means how data infrastructure resources hold up to, survive, and tolerate wear and tear from use (i.e., endurance), for example, Flash SSD or mechanical devices such as Hard Disk Drives (HDDs). Another context for durable refers to data, meaning how many copies in various places.
Server, storage, and I/O network availability topics include:
- Resiliency and self-healing to tolerate failure or disruption
- Hardware, software, and services configured for resiliency
- Accessibility to reach or be reached for handling work
- Durability and consistency of data to be available for access
- Protection of data, applications, and assets including security
Additional server I/O and data infrastructure along with storage topics include:
- Backup/restore, replication, snapshots, sync, and copies
- Basic Reliability, Availability, Serviceability, HA, fail over, BC, BR, and DR
- Alternative paths, redundant components, and associated software
- Applications that are fault-tolerant, resilient, and self-healing
- Non disruptive upgrades, code (application or software) loads, and activation
- Immediate data consistency and integrity vs. eventual consistency
- Virus, malware, and other data corruption or loss prevention
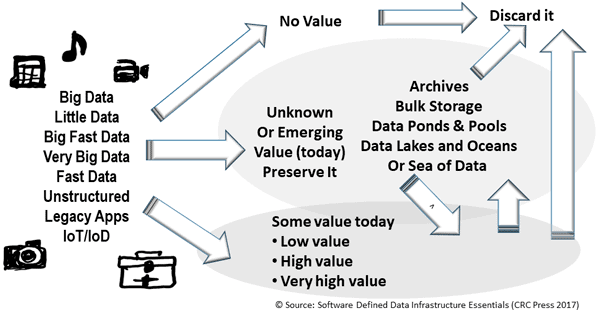
From a data protection standpoint, the fundamental rule or guideline is 4 3 2 1, which means having at least four copies consisting of at least three versions (different points in time), at least two of which are on different systems or storage devices and at least one of those is off-site (on-line, off-line, cloud, or other). There are many variations of the 4 3 2 1 rule shown in the following figure along with approaches on how to manage technology to use. We will go into deeper this subject in later chapters. For now, remember the following.
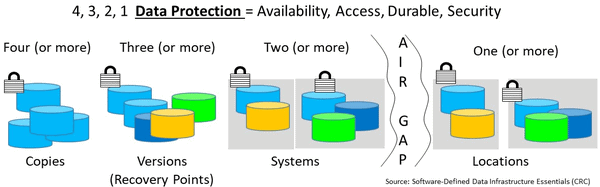
4 3 2 1 data protection (via Software Defined Data Infrastructure Essentials)
4 At least four copies of data (or more), Enables durability in case a copy goes bad, deleted, corrupted, failed device, or site.
3 The number (or more) versions of the data to retain, Enables various recovery points in time to restore, resume, restart from.
2 Data located on two or more systems (devices or media/mediums), Enables protection against device, system, server, file system, or other fault/failure.
1 With at least one of those copies being off-premise and not live (isolated from active primary copy), Enables resiliency across sites, as well as space, time, distance gap for protection.
Capacity and Space (What Gets Consumed and Occupied)
In addition to being available and accessible in a timely manner (performance), data (and applications) occupy space. That space is memory in servers, as well as using available consumable processor CPU time along with I/O (performance) including over networks.
Data and applications also consume storage space where they are stored. In addition to basic data space, there is also space consumed for metadata as well as protection copies (and overhead), application settings, logs, and other items. Another aspect of capacity includes network IP ports and addresses, software licenses, server, storage, and network bandwidth or service time.
Server, storage, and I/O network capacity topics include:
- Consumable time-expiring resources (processor time, I/O, network bandwidth)
- Network IP and other addresses
- Physical resources of servers, storage, and I/O networking devices
- Software licenses based on consumption or number of users
- Primary and protection copies of data and applications
- Active and standby data infrastructure resources and sites
- Data footprint reduction (DFR) tools and techniques for space optimization
- Policies, quotas, thresholds, limits, and capacity QoS
- Application and database optimization
DFR includes various techniques, technologies, and tools to reduce the impact or overhead of protecting, preserving, and serving more data for longer periods of time. There are many different approaches to implementing a DFR strategy, since there are various applications and data.
Common DFR techniques and technologies include archiving, backup modernization, copy data management (CDM), clean up, compress, and consolidate, data management, deletion and dedupe, storage tiering, RAID (including parity-based, erasure codes , local reconstruction codes [LRC] , and Reed-Solomon , Ceph Shingled Erasure Code (SHEC ), among others), along with protection configurations along with thin-provisioning, among others.
DFR can be implemented in various complementary locations from row-level compression in database or email to normalized databases, to file systems, operating systems, appliances, and storage systems using various techniques.
Also, keep in mind that not all data is the same; some is sparse, some is dense, some can be compressed or deduped while others cannot. Likewise, some data may not be compressible or dedupable. However, identical copies can be identified with links created to a common copy.
Economics (People, Budgets, Energy and other Constraints)
If one thing in life and technology that is constant is change, then the other constant is concern about economics or costs. There is a cost to enable and maintain a data infrastructure on premise or in the cloud, which exists to protect, preserve, and serve data and information applications.
However, there should also be a benefit to having the data infrastructure to house data and support applications that provide information to users of the services. A common economic focus is what something costs, either as up-front capital expenditure (CapEx) or as an operating expenditure (OpEx) expense, along with recurring fees.
In general, economic considerations include:
- Budgets (CapEx and OpEx), both up front and in recurring fees
- Whether you buy, lease, rent, subscribe, or use free and open sources
- People time needed to integrate and support even free open-source software
- Costs including hardware, software, services, power, cooling, facilities, tools
- People time includes base salary, benefits, training and education
Where to learn more
Learn more about Application Data Value, application characteristics, PACE along with data protection, software defined data center (SDDC), software defined data infrastructures (SDDI) and related topics via the following links:
- Part 1 – Application Data Value Characteristics Everything Is Not The Same
- Part 2 – 4 3 2 1 Data Protection Application Data Availability
- Part 3 – Application Data Characteristics Types Everything Is Not The Same
- Part 4 – Application Data Volume Velocity Variety Everything Is Not The Same
- Part 5 – Application Data Access life cycle Patterns Everything Not The Same
- Data Infrastructure server storage I/O network Recommended Reading
- World Backup Day 2018 Data Protection Readiness Reminder
- Data Infrastructure Server Storage I/O related Tradecraft Overview
- Data Infrastructure Overview, Its What’s Inside of Data Centers
- 4 3 2 1 and 3 2 1 data protection best practices
- Garbage data in, garbage information out, big data or big garbage?
- GDPR (General Data Protection Regulation) Resources Are You Ready?
- Which Enterprise HDD to use for a Content Server Platform
- The SSD Place (SSD, NVM, PM, SCM, Flash, NVMe, 3D XPoint, MRAM and related topics)
- The NVMe Place (NVMe related topics, trends, tools, technologies, tip resources)
- Data Protection Diaries (Archive, Backup/Restore, BC, BR, DR, HA,Replication, Security)

Additional learning experiences along with common questions (and answers), as well as tips can be found in Software Defined Data Infrastructure Essentials book.
What this all means and wrap-up
Keep in mind that with Application Data Value Characteristics Everything Is Not The Same across various organizations, data centers, data infrastructures spanning legacy, cloud and other software defined data center (SDDC) environments. All applications have some element of performance, availability, capacity, economic (PACE) needs as well as resource demands. There is often a focus around data storage about storage efficiency and utilization which is where data footprint reduction (DFR) techniques, tools, trends and as well as technologies address capacity requirements. However with data storage there is also an expanding focus around storage effectiveness also known as productivity tied to performance, along with availability including 4 3 2 1 data protection. Continue reading the next post (Part III Application Data Characteristics Types Everything Is Not The Same) in this series here.
Ok, nuff said, for now.
Gs
Greg Schulz – Microsoft MVP Cloud and Data Center Management, VMware vExpert 2010-2017 (vSAN and vCloud). Author of Software Defined Data Infrastructure Essentials (CRC Press), as well as Cloud and Virtual Data Storage Networking (CRC Press), The Green and Virtual Data Center (CRC Press), Resilient Storage Networks (Elsevier) and twitter @storageio. Courteous comments are welcome for consideration. First published on https://storageioblog.com any reproduction in whole, in part, with changes to content, without source attribution under title or without permission is forbidden.
All Comments, (C) and (TM) belong to their owners/posters, Other content (C) Copyright 2006-2026 Server StorageIO and UnlimitedIO. All Rights Reserved. StorageIO is a registered Trade Mark (TM) of Server StorageIO.