
Revisiting RAID data protection remains relevant and resources

Updated 2/10/2018
RAID data protection remains relevant including erasure codes (EC), local reconstruction codes (LRC) among other technologies. If RAID were really not relevant anymore (e.g. actually dead), why do some people spend so much time trying to convince others that it is dead or to use a different RAID level or enhanced RAID or beyond raid with related advanced approaches?
When you hear RAID, what comes to mind?
A legacy monolithic storage system that supports narrow 4, 5 or 6 drive wide stripe sets or a modern system support dozens of drives in a RAID group with different options?
RAID means many things, likewise there are different implementations (hardware, software, systems, adapters, operating systems) with various functionality, some better than others.
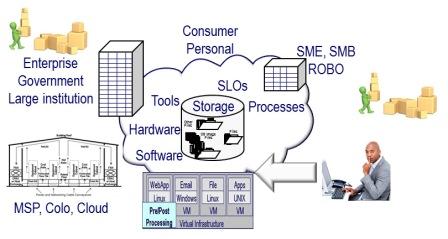
For example, which of the items in the following figure come to mind, or perhaps are new to your RAID vocabulary?

There are Many Variations of RAID Storage some for the enterprise, some for SMB, SOHO or consumer. Some have better performance than others, some have poor performance for example causing extra writes that lead to the perception that all parity based RAID do extra writes (some actually do write gathering and optimization).
Some hardware and software implementations using WBC (write back cache) mirrored or battery backed-BBU along with being able to group writes together in memory (cache) to do full stripe writes. The result can be fewer back-end writes compared to other systems. Hence, not all RAID implementations in either hardware or software are the same. Likewise, just because a RAID definition shows a particular theoretical implementation approach does not mean all vendors have implemented it in that way. |
RAID is not a replacement for backup rather part of an overall approach to providing data availability and accessibility.

What’s the best RAID level? The one that meets YOUR needs
There are different RAID levels and implementations (hardware, software, controller, storage system, operating system, adapter among others) for various environments (enterprise, SME, SMB, SOHO, consumer) supporting primary, secondary, tertiary (backup/data protection, archiving).

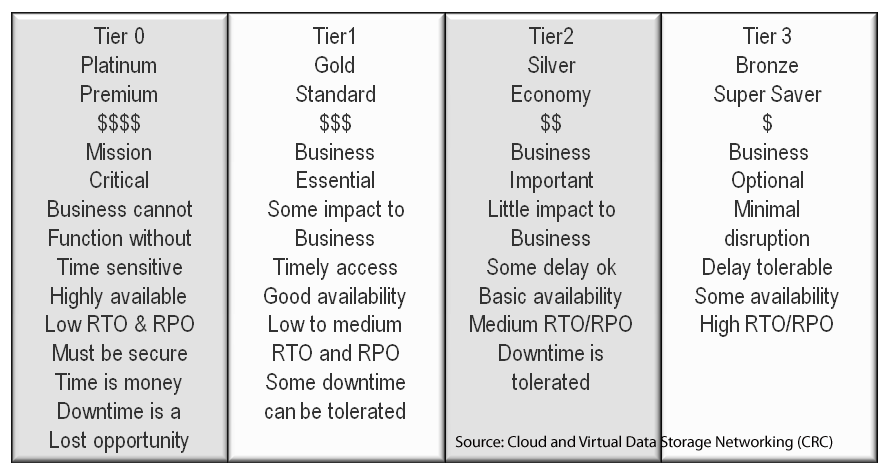
General RAID comparisons
Thus one size or approach does fit all solutions, likewise RAID rules of thumbs or guides need context. Context means that a RAID rule or guide for consumer or SOHO or SMB might be different for enterprise and vise versa, not to mention on the type of storage system, number of drives, drive type and capacity among other factors.

General basic RAID comparisons
Thus the best RAID level is the one that meets your specific needs in your environment. What is best for one environment and application may be different from what is applicable to your needs.
Key points and RAID considerations include: · Not all RAID implementations are the same, some are very much alive and evolving while others are in need of a rest or rewrite. So it is not the technology or techniques that are often the problem, rather how it is implemented and then deployed. · It may not be RAID that is dead, rather the solution that uses it, hence if you think a particular storage system, appliance, product or software is old and dead along with its RAID implementation, then just say that product or vendors solution is dead. · RAID can be implemented in hardware controllers, adapters or storage systems and appliances as well as via software and those have different features, capabilities or constraints. · Long or slow drive rebuilds are a reality with larger disk drives and parity-based approaches; however, you have options on how to balance performance, availability, capacity, and economics. · RAID can be single, dual or multiple parity or mirroring-based. · Erasure and other coding schemes leverage parity schemes and guess what umbrella parity schemes fall under. · RAID may not be cool, sexy or a fun topic and technology to talk about, however many trendy tools, solutions and services actually use some form or variation of RAID as part of their basic building blocks. This is an example of using new and old things in new ways to help each other do more without increasing complexity. · Even if you are not a fan of RAID and think it is old and dead, at least take a few minutes to learn more about what it is that you do not like to update your dead FUD. |
Wait, Isn’t RAID dead?
There is some dead marketing that paints a broad picture that RAID is dead to prop up something new, which in some cases may be a derivative variation of parity RAID.
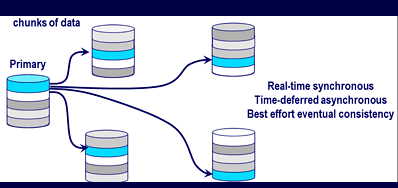
Data dispersal and durability

RAID continues to evolve with rapid rebuilds for some systems
Otoh, there are some specific products, technologies, implementations that may be end of life or actually dead. Likewise what might be dead, dying or simply not in vogue are specific RAID implementations or packaging. Certainly there is a lot of buzz around object storage, cloud storage, forward error correction (FEC) and erasure coding including messages of how they cut RAID. Catch is that some object storage solutions are overlayed on top of lower level file systems that do things such as RAID 6, granted they are out of sight, out of mind.

General RAID parity and erasure code/FEC comparisons
Then there are advanced parity protection schemes which include FEC and erasure codes that while they are not your traditional RAID levels, they have characteristic including chunking or sharding data, spreading it out over multiple devices with multiple parity (or derivatives of parity) protection.
Bottom line is that for some environments, different RAID levels may be more applicable and alive than for others.
Via BizTech – How to Turn Storage Networks into Better Performers
|
If RAID is alive, what to do with it?
If you are new to RAID, learn more about the past, present and future keeping mind context. Keeping context in mind means that there are different RAID levels and implementations for various environments. Not all RAID 0, 1, 1/0, 10, 2, 3, 4, 5, 6 or other variations (past, present and emerging) are the same for consumer vs. SOHO vs. SMB vs. SME vs. Enterprise, nor are the usage cases. Some need performance for reads, others for writes, some for high-capacity with low performance using hardware or software. RAID Rules of thumb are ok and useful, however keep them in context to what you are doing as well as using.
What to do next?
Take some time to learn, ask questions including what to use when, where, why and how as well as if an approach or recommendation are applicable to your needs. Check out the following links to read some extra perspectives about RAID and keep in mind, what might apply to enterprise may not be relevant for consumer or SMB and vise versa.
Some advise needed on SSD’s and Raid (Via Spiceworks)
RAID 5 URE Rebuild Means The Sky Is Falling (Via BenchmarkReview)
Double drive failures in a RAID-10 configuration (Via SearchStorage)
Industry Trends and Perspectives: RAID Rebuild Rates (Via StorageIOblog)
RAID, IOPS and IO observations (Via StorageIOBlog)
RAID Relevance Revisited (Via StorageIOBlog)
HDDs Are Still Spinning (Rust Never Sleeps) (Via InfoStor)
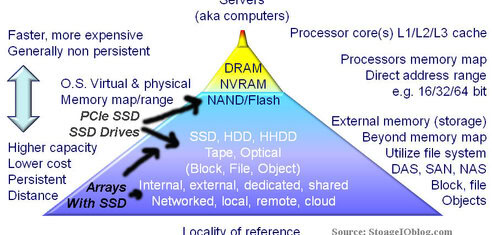
When and Where to Use NAND Flash SSD for Virtual Servers (Via TheVirtualizationPractice)
What’s the best way to learn about RAID storage? (Via Spiceworks)
Design considerations for the host local FVP architecture (Via Frank Denneman)
Some basic RAID fundamentals and definitions (Via SearchStorage)
Can RAID extend nand flash SSD life? (Via StorageIOBlog)
I/O Performance Issues and Impacts on Time-Sensitive Applications (Via CMG)
The original RAID white paper (PDF) that while over 20 years old, it provides a basis, foundation and some history by Katz, Gibson, Patterson et al
Storage Interview Series (Via Infortrend)
Different RAID methods (Via RAID Recovery Guide)
A good RAID tutorial (Via TheGeekStuff)
Basics of RAID explained (Via ZDNet)
RAID and IOPs (Via VMware Communities)
Where To Learn More
View additional NAS, NVMe, SSD, NVM, SCM, Data Infrastructure and HDD related topics via the following links.
- Data Protection Diaries Fundamental Topics Tools Techniques Technologies Tips
- Can we get a side of context with them IOPS and other storage metrics?
- WHEN AND WHERE TO USE NAND FLASH SSD FOR VIRTUAL SERVERS
- Revisiting RAID storage remains relevant and resources
- NVMe overview and primer – Part I
- Part 1 of HDD for content servers series Trends and Content Application Servers
- Part 2 of HDD for content servers series Content application server decisions and testing plans
- Part 3 of HDD for content servers series Test hardware and software configuration
- Part 4 of HDD for content servers series Large file I/O processing
- Part 5 of HDD for content servers series Small file I/O processing
- Part 6 of HDD for content servers series General I/O processing
- Part 7 of HDD for content servers series How HDD continue to evolve over different generations and wrap up
- As the platters spin, HDD’s for cloud, virtual and traditional storage environments
- How many IOPS can a HDD, HHDD or SSD do?
- Hard Disk Drives (HDD) for Virtual Environments
- Server and Storage I/O performance and benchmarking tools
- Server storage I/O performance benchmark workload scripts Part I and Part II
- How to test your HDD, SSD or all flash array (AFA) storage fundamentals
- What is the best server storage I/O workload benchmark? It depends
- I/O, I/O how well do you know about good or bad server and storage I/Os?
- Big Files Lots of Little File Processing Benchmarking with Vdbench
- Part II – NVMe overview and primer (Different Configurations)
- Part III – NVMe overview and primer (Need for Performance Speed)
- Part IV – NVMe overview and primer (Where and How to use NVMe)
- Part V – NVMe overview and primer (Where to learn more, what this all means)
- PCIe Server I/O Fundamentals
- If NVMe is the answer, what are the questions?
- NVMe Wont Replace Flash By Itself
- Via Computerweekly – NVMe discussion: PCIe card vs U.2 and M.2
- Intel and Micron unveil new 3D XPoint Non Volatie Memory (NVM) for servers and storage
- Part II – Intel and Micron new 3D XPoint server and storage NVM
- Part III – 3D XPoint new server storage memory from Intel and Micron
- Server storage I/O benchmark tools, workload scripts and examples (Part I) and (Part II)
- Data Infrastructure Overview, Its Whats Inside of Data Centers
- All You Need To Know about Remote Office/Branch Office Data Protection Backup (free webinar with registration)
- Software Defined, Converged Infrastructure (CI), Hyper-Converged Infrastructure (HCI) resources
- The SSD Place (SSD, NVM, PM, SCM, Flash, NVMe, 3D XPoint, MRAM and related topics)
- The NVMe Place (NVMe related topics, trends, tools, technologies, tip resources)
- Data Protection Diaries (Archive, Backup/Restore, BC, BR, DR, HA, RAID/EC/LRC, Replication, Security)
- Software Defined Data Infrastructure Essentials (CRC Press 2017) including SDDC, Cloud, Container and more
- Various Data Infrastructure related events, webinars and other activities
- www.objectstoragecenter.com and Software Defined, Cloud, Bulk and Object Storage Fundamentals
- Server Storage I/O Network PCIe Fundamentals
Additional learning experiences along with common questions (and answers), as well as tips can be found in Software Defined Data Infrastructure Essentials book.

What This All Means
What is my favorite or preferred RAID level?
That depends, for some things its RAID 1, for others RAID 10 yet for others RAID 4, 5, 6 or DP and yet other situations could be a fit for RAID 0 or erasure codes and FEC. Instead of being focused on just one or two RAID levels as the solution for different problems, I prefer to look at the environment (consumer, SOHO, small or large SMB, SME, enterprise), type of usage (primary or secondary or data protection), performance characteristics, reads, writes, type and number of drives among other factors. What might be a fit for one environment would not be a fit for others, thus my preferred RAID level along with where implemented is the one that meets the given situation. However also keep in mind is tying RAID into part of an overall data protection strategy, remember, RAID is not a replacement for backup.
What this all means
Like other technologies that have been declared dead for years or decades, aka the Zombie technologies (e.g. dead yet still alive) RAID continues to be used while the technologies evolves. There are specific products, implementations or even RAID levels that have faded away, or are declining in some environments, yet alive in others. RAID and its variations are still alive, however how it is used or deployed in conjunction with other technologies also is evolving.
Ok, nuff said, for now.
Gs
Greg Schulz – Microsoft MVP Cloud and Data Center Management, VMware vExpert 2010-2017 (vSAN and vCloud). Author of Software Defined Data Infrastructure Essentials (CRC Press), as well as Cloud and Virtual Data Storage Networking (CRC Press), The Green and Virtual Data Center (CRC Press), Resilient Storage Networks (Elsevier) and twitter @storageio. Courteous comments are welcome for consideration. First published on https://storageioblog.com any reproduction in whole, in part, with changes to content, without source attribution under title or without permission is forbidden.
All Comments, (C) and (TM) belong to their owners/posters, Other content (C) Copyright 2006-2026 Server StorageIO and UnlimitedIO. All Rights Reserved. StorageIO is a registered Trade Mark (TM) of Server StorageIO.








































{kind=link}