Data Infrastructure Primer Overview

Updated 1/17/2018
Data Infrastructure Primer Overview looks at the resources that combine to support business, cloud and information technology (IT) among other applications that transform data into information or services. The fundamental role of data infrastructures is to provide a platform environment for applications and data that is resilient, flexible, scalable, agile, efficient as well as cost-effective. Put another way, data infrastructures exist to protect, preserve, process, move, secure and serve data as well as their applications for information services delivery. Technologies that make up data infrastructures include hardware, software, cloud or managed services, servers, storage, I/O and networking along with people, processes, policies along with various tools spanning legacy, software-defined virtual, containers and cloud.
Various Types and Layers of Infrastructures
Depending on your role or focus, you may have a different view than somebody else of what is infrastructure, or what an infrastructure is. Generally speaking, people tend to refer to infrastructure as those things that support what they are doing at work, at home, or in other aspects of their lives. For example, the roads and bridges that carry you over rivers or valleys when traveling in a vehicle are referred to as infrastructure.
Similarly, the system of pipes, valves, meters, lifts, and pumps that bring fresh water to you, and the sewer system that takes away waste water, are called infrastructure. The telecommunications network. This includes both wired and wireless, such as cell phone networks, along with electrical generating and transmission networks are considered infrastructure. Even the airplanes, trains, boats, and buses that transport us locally or globally are considered part of the transportation infrastructure. Anything that is below what you do, or that supports what you do is considered infrastructure.
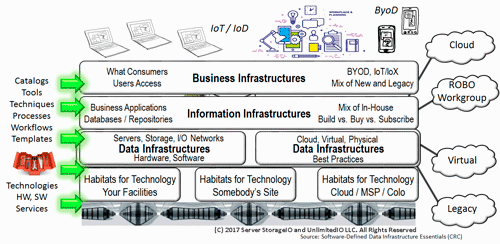
Figure 1 Business, IT Information, Data and other Infrastructures
This is also the situation with IT systems and services where, depending on where you sit or use various services, anything below what you do may be considered infrastructure. However, that also causes a context issue in that infrastructure can mean different things. For example in figure 1, the user, customer, client, or consumer who is accessing some service or application may view IT in general as infrastructure, or perhaps as business infrastructure.
Those who develop, service, and support the business infrastructure and its users or clients may view anything below them as infrastructure, from desktop to database, servers to storage, network to security, data protection to physical facilities. Moving down a layer (lower altitude) in figure 1 is the information infrastructure which, depending on your view, may also include servers, storage, and I/O hardware and software.
To help make a point, let’s think of the information infrastructure as the collection of databases, key-value stores, repositories, and applications along with development tools that support the business infrastructure. This is where you may find developers who maintain and create real business applications for the business infrastructure. Those in the information infrastructure usually refer to what’s below them as infrastructure. Meanwhile, those lower in the stack shown in figure 1 may refer to what’s above them as the customer, user, or application, even if the real user is up another layer or two.
Whats inside a data infrastructure
Context matters in the discussion of infrastructure. So for our of server storage I/O fundamentals, the data infrastructures support the databases and applications developers as well as things above, while existing above the physical facilities infrastructure, leveraging power, cooling, and communication network infrastructures below.

Figure 2 Data Infrastructure fundamental building blocks (hardware, software, services).
Figure 2 shows the fundamental pillars or building blocks for a data infrastructure, including servers for computer processing, I/O networks for connectivity, and storage for storing data. These resources including both hardware and software as well as services and tools. The size of the environment, organization, or application needs will determine how large or small the data infrastructure is or can be.
For example, at one extreme you can have a single high-performance laptop with a hypervisor running OpenStack; along with various operating systems along with their applications leveraging flash SSD and high-performance wired or wireless networks powering a home lab or test environment. On the other hand, you can have a scenario with tens of thousands (or more) servers, networking devices, and hundreds of petabytes (PBs) of storage (or more).
In figure 2 the primary data infrastructure components or pillar (server, storage, and I/O) hardware and software resources are packaged and defined to meet various needs. Software-defined storage management includes configuring the server, storage, and I/O hardware and software as well as services for use, implementing data protection and security, provisioning, diagnostics, troubleshooting, performance analysis, and other activities. Server storage and I/O hardware and software can be individual components, prepackaged as bundles or application suites and converged, among other options.
Figure 3 shows a deeper look into the data infrastructure shown at a high level in figure 2. The lower left of figure 2 shows the common-to-all-environments hardware, software, people, processes, and practices that include tradecraft (experiences, skills, techniques) and “valueware”. Valueware is how you define the hardware and software along with any customization to create a resulting service that adds value to what you are doing or supporting. Also shown in figure 3 are common application and services attributes including performance, availability, capacity, and economics (PACE), which vary with different applications or usage scenarios.

Figure 3 Data Infrastructure server storage I/O hardware and software components.
Applications are what transform data into information. Figure 4 shows how applications, which are software defined by people and software, consist of algorithms, policies, procedures, and rules that are put into some code to tell the server processor (CPU) what to do.

Figure 4 How data infrastructure resources transform data into information.
Application programs include data structures (not to be confused with infrastructures) that define what data looks like and how to organize and access it using the “rules of the road” (the algorithms). The program algorithms along with data structures are stored in memory, together with some of the data being worked on (i.e., the active working set). Additional data is stored in some form of extended memory storage devices such as Non-Volatile Memory (NVM) solid-state devices (SSD), hard disk drives (HDD), or tape, among others, either locally or remotely. Also shown in figure 4 are various devices that do input/output (I/O) with the applications and server, including mobile devices as well as other application servers.
Bringing IT All Together (for now)

Figure 5 Data Infrastructure fundamentals “big picture”
A fundamental theme is that servers process data using various applications programs to create information; I/O networks provide connectivity to access servers and storage; storage is where data gets stored, protected, preserved, and served from; and all of this needs to be managed. There are also many technologies involved, including hardware, software, and services as well as various techniques that make up a server, storage, and I/O enabled data infrastructure.
Server storage I/O and data infrastructure fundamental focus areas include:
- Organizations: Markets and industry focus, organizational size
- Applications: What’s using, creating, and resulting in server storage I/O demands
- Technologies: Tools and hard products (hardware, software, services, packaging)
- Trade craft: Techniques, skills, best practices, how managed, decision making
- Management: Configuration, monitoring, reporting, troubleshooting, performance, availability, data protection and security, access, and capacity planning
Where To Learn More
View additional Data Infrastructure and related topics via the following links.
- NVMe overview and primer – Part I
- Part II – NVMe overview and primer (Different Configurations)
- Part III – NVMe overview and primer (Need for Performance Speed)
- Part IV – NVMe overview and primer (Where and How to use NVMe)
- Part V – NVMe overview and primer (Where to learn more, what this all means)
- PCIe Server I/O Fundamentals
- If NVMe is the answer, what are the questions?
- NVMe Wont Replace Flash By Itself
- Via Computerweekly – NVMe discussion: PCIe card vs U.2 and M.2
- Intel and Micron unveil new 3D XPoint Non Volatie Memory (NVM) for servers and storage
- Part II – Intel and Micron new 3D XPoint server and storage NVM
- Part III – 3D XPoint new server storage memory from Intel and Micron
- Server storage I/O benchmark tools, workload scripts and examples (Part I) and (Part II)
- Data Infrastructure Overview, Its Whats Inside of Data Centers
- All You Need To Know about Remote Office/Branch Office Data Protection Backup (free webinar with registration)
- Software Defined, Converged Infrastructure (CI), Hyper-Converged Infrastructure (HCI) resources
- The SSD Place (SSD, NVM, PM, SCM, Flash, NVMe, 3D XPoint, MRAM and related topics)
- The NVMe Place (NVMe related topics, trends, tools, technologies, tip resources)
- Data Protection Diaries (Archive, Backup/Restore, BC, BR, DR, HA, RAID/EC/LRC, Replication, Security)
- Software Defined Data Infrastructure Essentials (CRC Press 2017) including SDDC, Cloud, Container and more
- Various Data Infrastructure related events, webinars and other activities
Additional learning experiences along with common questions (and answers), as well as tips can be found in Software Defined Data Infrastructure Essentials book.

What This All Means
Whether you realize it or not, you may already be using, rely upon, affiliated with, support or otherwise involved with data infrastructures. Granted what you or others generically refer to as infrastructure or the data center may, in fact, be the data infrastructure. Watch for more discussions and content about as well as related technologies, tools, trends, techniques and tradecraft in future posts as well as other venues, some of which involve legacy, others software-defined, cloud, virtual, container and hybrid.
Ok, nuff said, for now.
Gs
Greg Schulz – Microsoft MVP Cloud and Data Center Management, VMware vExpert 2010-2017 (vSAN and vCloud). Author of Software Defined Data Infrastructure Essentials (CRC Press), as well as Cloud and Virtual Data Storage Networking (CRC Press), The Green and Virtual Data Center (CRC Press), Resilient Storage Networks (Elsevier) and twitter @storageio. Courteous comments are welcome for consideration. First published on https://storageioblog.com any reproduction in whole, in part, with changes to content, without source attribution under title or without permission is forbidden.
All Comments, (C) and (TM) belong to their owners/posters, Other content (C) Copyright 2006-2026 Server StorageIO and UnlimitedIO. All Rights Reserved. StorageIO is a registered Trade Mark (TM) of Server StorageIO.











































{kind=link}