March 2018 Server StorageIO Data Infrastructure Update Newsletter

Volume 18, Issue 3 (March 2018)
Hello and welcome to the March 2018 Server StorageIO Data Infrastructure Update Newsletter.
If you are wondering where the January and February 2018 update newsletters are, they are rolled into this combined edition. In addition to the short email version (free signup here), you can access full versions (html here and PDF here) along with previous editions here.
In this issue:
- Data Infrastructure Industry Activity
- News Commentary and Tips
- Server StorageIOblog posts
- Recommended Reading
- Various Events and Webinars
- Industry Resources and Links
Enjoy this edition of the Server StorageIO Data Infrastructure update newsletter.
Cheers GS
Data Infrastructure and IT Industry Activity Trends
World Backup day is coming up on March 31 which is a good time to remember to verify and validate that your data protection is working as intended. On one hand I think it is a good idea to call out the importance of making sure your data is protected including backed up.
On the other hand data protection is not a once a year, rather a year around, 7 x 24 x 365 day focus. Also the focus needs to be on more than just backup, rather, all aspects of data protection from archiving to business continuance (BC), business resiliency (BR), disaster recovery (DR), always on, always accessible, along with security and recovery.
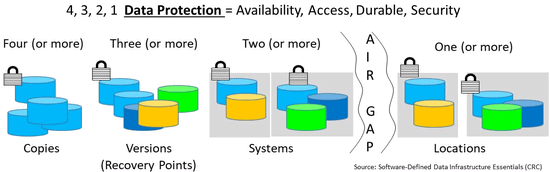
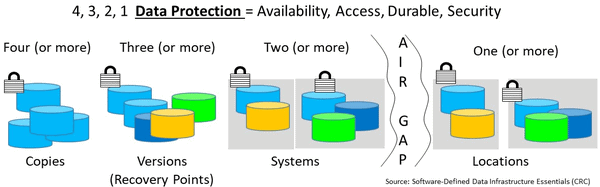
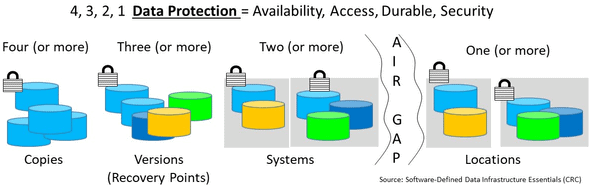
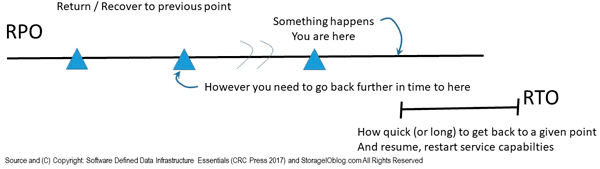
Data Infrastructure 4 3 2 1 Data Protection and Backup
Some data spring thoughts, perspectives and reminders. Data lakes may swell beyond their banks causing rivers of data to flood as they flow into larger reservoirs, great data lakes, gulfs of data, seas and oceans of data. Granted, some of that data will be inactive cold parked like glaciers while others semi-active floating around like icebergs. Hopefully your data is stored on durable storage solutions or services and does not melt.
- Application Data Availability 4 3 2 1 Data Protection
- Veeam GDPR preparedness experiences Webinar walking the talk
- Benefits of Moving Hyper-V Disaster Recovery to the Cloud Webinar
- World Backup Day 2018 Data Protection Readiness Reminder
- Part 1 – Data Infrastructure Data Protection Fundamentals
- Data Protection Diaries series

Various NAND Flash SSD devices and SAS, SATA, NVMe, M.2 interfaces
Non-Volatile Memory (NVM) including various solid state device (SSD) mediums (e.g. nand flash, 3D XPoint, MRAM among others), packaging (drives, PCIe Add in cars [AiC] along with entire systems, appliances or arrays). Also part of the continue evolution of NVM, SSD and other persistent memories (PM) including storage class memories (SCM) are different access protocol interfaces.
Keep in mind that there is a difference between NVM (medium) and NVMe (access), NVM is the generic category of mediums or media and devices such as nand flash, nvram, 3D XPoint among others SCM (and PMs). In other words, NVM is what data devices use for storing data, NVMe is how devices and systems are accessed. NVMe and its variations is how NVM, SSD, PM, SCM media and devices get accessed locally, as well as over network fabrics (e.g. NVMe-oF an FC-NVMe).
NVMe continues to evolve including with networked fabric variations such as RDMA based NVMe over Fabric (NVMe-oF), along with Fibre Channel based (FC-NVMe). The Fibre Channel Industry Association trade group recently held its second multi-vendor plugfest in support of NVMe over Fibre Channel.
Read more about NVM, NVMe, SSD, SCM, flash and related technologies, tools, trends, tips via the following resources:
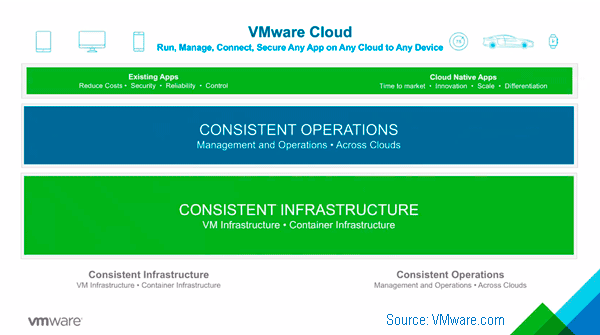
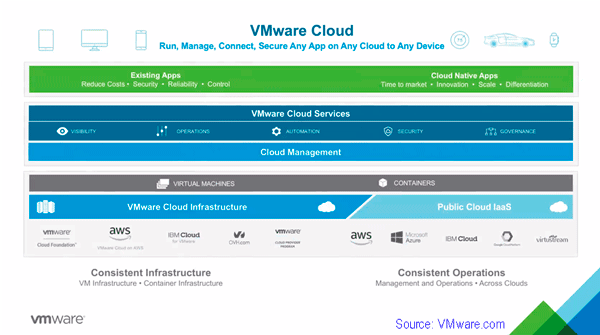
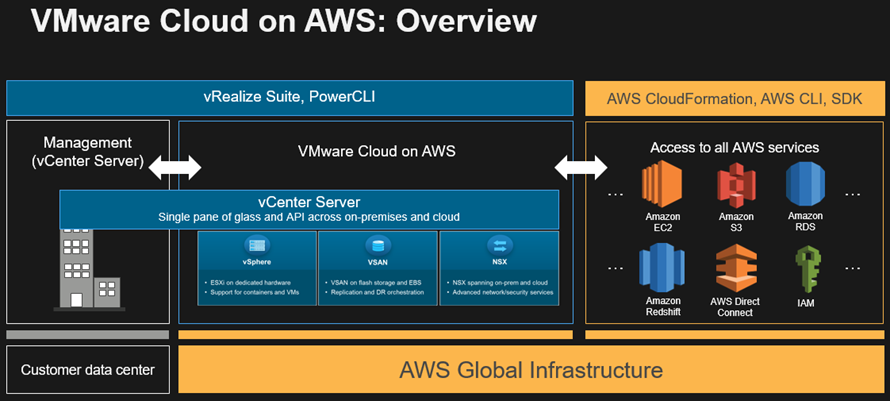
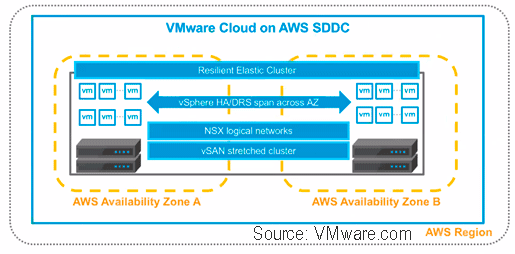
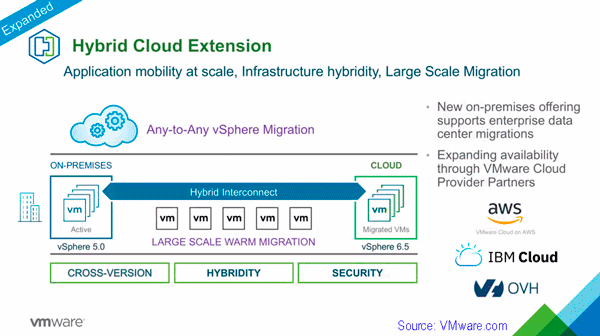
- VMware continues cloud construction with March announcements
- Use Intel Optane NVMe U.2 SFF 8639 SSD drive in PCIe slot
- PCIe Server Storage I/O Network Fundamentals #blogtober
- If Answer is NVMe, what are the questions?
- NVMe Wont Replace Flash By Itself They Complement Each Other
- www.thessdplace.com and www.thenvmeplace.com
Has Object Storage failed to live up to its industry hype lacking traction? Or, is object storage (also known as blobs) progressing with customer adoption and deployment on normal realistic timelines? Recently I have seen some industry comments about object storage not catching on with customers or failing to live up to its hyped expectation. IMHO object storage is very much alive along with block, file, table (e.g. database SQL and NoSQL repositories), message/queue among others, as well as emerging blockchain aka data exchanges.
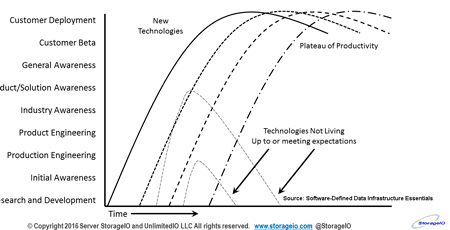
Various Industry and Customer Adoption Deployment Timeline (Via: StorageIOblog.com)
An issue with object storage is that it is still new, still evolving, many IT environments applications do not yet speak or access objects and blobs natively. Likewise as is often the case, industry adoption and deployment is usually early and short term around the hype, vs. the longer cycle of customer adoption and deployment. The downside for those who only focus on object storage (or blobs) is that they may be under pressure to do things short term instead of adjusting to customer cycles which take longer, however real adoption and deployment also last longer.
While the hype and industry buzz around object storage (and blobs) may have faded, customer adoption continues and is here to stay, along with block, file among others, learn more at www.objectstoragecenter.com. Also keep in mind that there is a difference between industry and customer adoption along with deployment.
Some recent Industry Activities, Trends, News and Announcements include:
In case you missed it, Amazon Web Services (e.g. AWS) announced EKS (Elastic Kubernetes Service) which as its name implies, is an easy to use and manage Kubernetes (containers, serverless data infrastructure) running on AWS. AWS joins others including Microsoft Azure Kubernetes Services (AKS), Googles Kubernetes Engine, EasyStack (ESContainer for openstack and Kubernetes),VMware Pivotal Container Service (PKS) among others. What this means is that in the container serverless data infrastructure ecosystem Kubernetes container management (orchestration platform) is gaining in both industry as well as customer adoption along with deployment.
Check out other industry news, comments, trends perspectives here.

Server StorageIO Commentary in the news, tips and articles
Recent Server StorageIO industry trends perspectives commentary in the news.
Via BizTech: Why Hybrid (SSD and HDD) Storage Might Be Fit for SMB environments
Via Excelero: Server StorageIO white paper enabling database DBaaS productivity
Via Cloudian: YouTube video interview file services on object storage with HyperFile
Via CDW Solutions: Comments on Software Defined Access
Via SearchStorage: Comments on Cloudian HyperStore on demand cloud like pricing
Via EnterpriseStorageForum: Comments and tips on Software Defined Storage Best Practices
Via PRNewsWire: Comments on Excelero NVMe NVMesh Database and DBaaS solutions
Via SearchStorage: Comments on NooBaa multi-cloud storage management
Via CDW: Comments on New IT Strategies Improve Your Bottom Line
Via EnterpriseStorageForum: Comments on Software Defined Storage: Pros and Cons
Via DataCenterKnowledge: Comments on The Great Data Center Headache IoT
Via SearchStorage: Comments on Dell and VMware merger scenario options
Via PRNewswire: Comments on Chelsio Microsoft Validation of iWARP/RDMA
Via SearchStorage: Comments on Server Storage Industry trends and Dell EMC
Via ChannelProSMB: Comments on Hybrid HDD and SSD storage solutions
Via ChannelProNetwork: Comments on What the Future Holds for HDDs
Via HealthcareITnews: Comments on MOUNTAINS OF MOBILE DATA
Via SearchStorage: Comments on Cloudian HyperStore 7 targets multi-cloud complexities
Via GlobeNewsWire: Comments on Cloudian HyperStore 7
Via GizModo: Comments on Intel Optane 800P NVMe M.2 SSD
Via DataCenterKnowledge: Comments on getting data centers ready for IoT
Via DataCenterKnowledge: Comments on Beyond the Hype: AI in the Data Center
Via DataCenterKnowledge: Comments on Data Center and Cloud Disaster Recovery
Via SearchStoragae: Comments on Cloudian HyperFile marries NAS and object storage
Via SearchStoragae: Comments on Top 10 Tips on Solid State Storage Adoption Strategy
Via SearchStoragae: Comments on 8 Top Tips for Beating the Big Data Deluge
View more Server, Storage and I/O trends and perspectives comments here.
Server StorageIOblog Data Infrastructure Posts
Recent and popular Server StorageIOblog posts include:
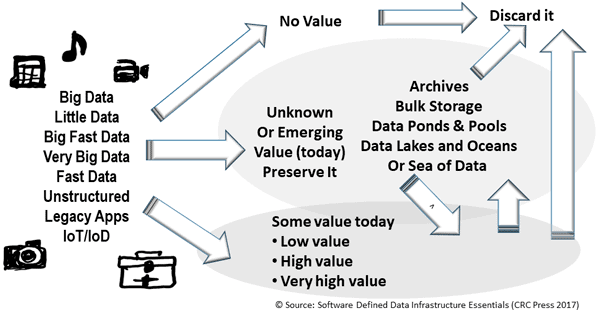
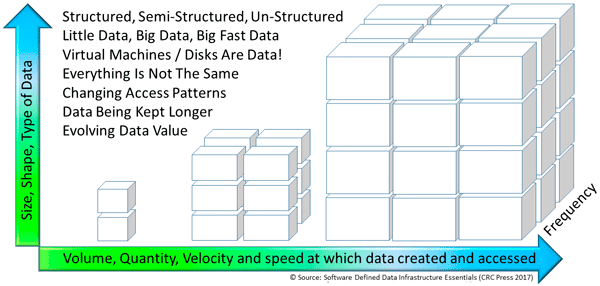
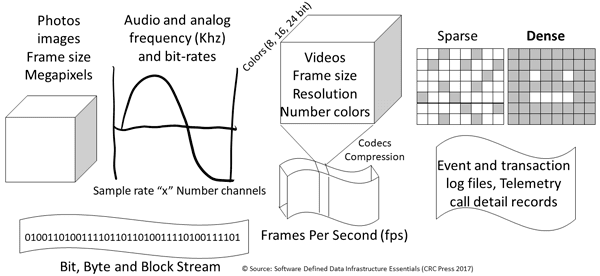
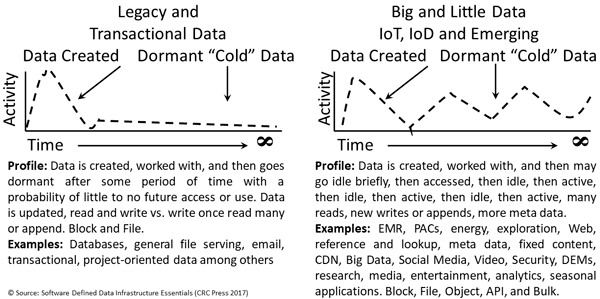
Application Data Value Characteristics Everything Is Not The Same
Application Data Availability 4 3 2 1 Data Protection
AWS Cloud Application Data Protection Webinar
Microsoft Windows Server 2019 Insiders Preview
Application Data Characteristics Types Everything Is Not The Same
Application Data Volume Velocity Variety Everything Is Not The Same
Application Data Access Lifecycle Patterns Everything Is Not The Same
Veeam GDPR preparedness experiences Webinar walking the talk
VMware continues cloud construction with March announcements
Benefits of Moving Hyper-V Disaster Recovery to the Cloud Webinar
World Backup Day 2018 Data Protection Readiness Reminder
Use Intel Optane NVMe U.2 SFF 8639 SSD drive in PCIe slot
Data Infrastructure Resource Links cloud data protection tradecraft trends
How to Achieve Flexible Data Protection Availability with All Flash Storage Solutions
November 2017 Server StorageIO Data Infrastructure Update Newsletter
IT transformation Serverless Life Beyond DevOps Podcast
Data Protection Diaries Fundamental Topics Tools Techniques Technologies Tips
HPE Announces AMD Powered Gen 10 ProLiant DL385 For Software Defined Workloads
AWS Announces New S3 Cloud Storage Security Encryption Features
Introducing Windows Subsystem for Linux WSL Overview #blogtober
Hot Popular New Trending Data Infrastructure Vendors To Watch
View other recent as well as past StorageIOblog posts here
Server StorageIO Recommended Reading (Watching and Listening) List

In addition to my own books including Software Defined Data Infrastructure Essentials (CRC Press 2017) available at Amazon.com (check out special sale price), the following are Server StorageIO data infrastructure recommended reading, watching and listening list items. The Server StorageIO data infrastructure recommended reading list includes various IT, Data Infrastructure and related topics including Intel Recommended Reading List (IRRL) for developers is a good resource to check out. Speaking of my books, Didier Van Hoye (@WorkingHardInIt) has a good review over on his site you can view here, also check out the rest of his great content while there.
In case you may have missed it, here is a good presentation from AWS re:invent 2017 by Brendan Gregg (@brendangregg) about how Netflix does EC2 and other AWS tuning along with plenty of great resource links. Keith Tenzer (@keithtenzer) provides a good perspective piece about containers in a large IT enterprise environment here including various options.
Speaking of IT data centers and data infrastructure environments, checkout the list of some of the worlds most extreme habitats for technology here. Mark Betz (@markbetz) has a series of Docker and Kubernetes networking fundamentals posts on his site here, as well as over at Medium including mention of Google Cloud (@googlecloud). The posts in Marks series are good refresher or intros to how Docker and Kubernetes handles basic networking between containers, pods, nodes, hosts in clusters. Check out part I here and part II here.
Image via https://stevetodd.typepad.com
Steve Todd (@Stevetodd) has some good perspectives about Trusted Data Exchanges e.g. life beyond blockchain and bitcoin here along with core element considerations (beyond the product pitch) here, along with associated data infrastructure and storage evolution vs. revolution here.
Watch for more items to be added to the recommended reading list book shelf soon.

Events and Activities
Recent and upcoming event activities.
March 27, 2018 – Webinar – Veeams Road to GDPR Compliancy The 5 Lessons Learned
Feb 28, 2018 – Webinar – Benefits of Moving Hyper-V Disaster Recovery to the Cloud
Jan 30, 2018 – Webinar – Achieve Flexible Data Protection and Availability with All Flash Storage
Nov. 9, 2017 – Webinar – All You Need To Know about ROBO Data Protection Backup
See more webinars and activities on the Server StorageIO Events page here.
Data Infrastructure Server StorageIO Industry Resources and Links
Various useful links and resources:
Data Infrastructure Recommend Reading and watching list
Microsoft TechNet – Various Microsoft related from Azure to Docker to Windows
storageio.com/links – Various industry links (over 1,000 with more to be added soon)
objectstoragecenter.com – Cloud and object storage topics, tips and news items
OpenStack.org – Various OpenStack related items
storageio.com/downloads – Various presentations and other download material
storageio.com/protect – Various data protection items and topics
thenvmeplace.com – Focus on NVMe trends and technologies
thessdplace.com – NVM and Solid State Disk topics, tips and techniques
storageio.com/converge – Various CI, HCI and related SDS topics
storageio.com/performance – Various server, storage and I/O benchmark and tools
VMware Technical Network – Various VMware related items
Connect and Converse With Us




What this all means and wrap-up
Data Infrastructures are what exists inside physical data centers spanning cloud, converged, hyper-converged, virtual, serverless and other software defined as well as legacy environments. The fundamental role of data infrastructures comprising server (compute), storage, I/O networking hardware, software, services defined by management tools, best practices and policies is to provide a platform for applications along with their data to deliver information services. With March 31 being world backup day, also focus on making sure that on April 1st you are not a fool trying to recover from a bad data protection copy. With the continued movement to flash SSD along with other forms of storage class memory (SCM) and persistent memories (PM), data moves at a faster rate meaning data protection is even more important to get you out of trouble as fast as you get into issues.
Ok, nuff said, for now.
Gs
Greg Schulz – Microsoft MVP Cloud and Data Center Management, VMware vExpert 2010-2017 (vSAN and vCloud). Author of Software Defined Data Infrastructure Essentials (CRC Press), as well as Cloud and Virtual Data Storage Networking (CRC Press), The Green and Virtual Data Center (CRC Press), Resilient Storage Networks (Elsevier) and twitter @storageio. Courteous comments are welcome for consideration. First published on https://storageioblog.com any reproduction in whole, in part, with changes to content, without source attribution under title or without permission is forbidden.
All Comments, (C) and (TM) belong to their owners/posters, Other content (C) Copyright 2006-2026 Server StorageIO and UnlimitedIO. All Rights Reserved. StorageIO is a registered Trade Mark (TM) of Server StorageIO.