Application Data Characteristics Types Everything Is Not The Same

Application Data Characteristics Types Everything Is Not The Same
This is part three of a five-part mini-series looking at Application Data Value Characteristics everything is not the same as a companion excerpt from chapter 2 of my new book Software Defined Data Infrastructure Essentials – Cloud, Converged and Virtual Fundamental Server Storage I/O Tradecraft (CRC Press 2017). available at Amazon.com and other global venues. In this post, we continue looking at application and data characteristics with a focus on different types of data. There is more to data than simply being big data, fast data, big fast or unstructured, structured or semistructured, some of which has been touched on in this series, with more to follow. Note that there is also data in terms of the programs, applications, code, rules, policies as well as configuration settings, metadata along with other items stored.

Various Types of Data
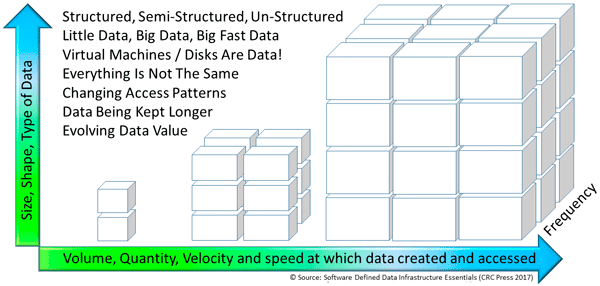
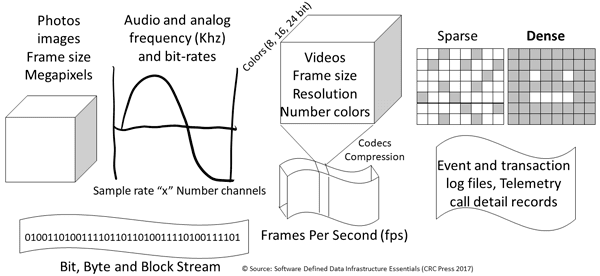
Data types along with characteristics include big data, little data, fast data, and old as well as new data with a different value, life-cycle, volume and velocity. There are data in files and objects that are big representing images, figures, text, binary, structured or unstructured that are software defined by the applications that create, modify and use them.
There are many different types of data and applications to meet various business, organization, or functional needs. Keep in mind that applications are based on programs which consist of algorithms and data structures that define the data, how to use it, as well as how and when to store it. Those data structures define data that will get transformed into information by programs while also being stored in memory and on data stored in various formats.
Just as various applications have different algorithms, they also have different types of data. Even though everything is not the same in all environments, or even how the same applications get used across various organizations, there are some similarities. Even though there are different types of applications and data, there are also some similarities and general characteristics. Keep in mind that information is the result of programs (applications and their algorithms) that process data into something useful or of value.
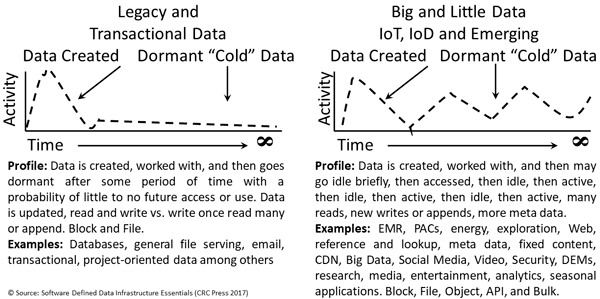
Data typically has a basic life cycle of:
- Creation and some activity, including being protected
- Dormant, followed by either continued activity or going inactive
- Disposition (delete or remove)
In general, data can be
- Temporary, ephemeral or transient
- Dynamic or changing (“hot data”)
- Active static on-line, near-line, or off-line (“warm-data”)
- In-active static on-line or off-line (“cold data”)
Data is organized
- Structured
- Semi-structured
- Unstructured
General data characteristics include:
- Value = From no value to unknown to some or high value
- Volume = Amount of data, files, objects of a given size
- Variety = Various types of data (small, big, fast, structured, unstructured)
- Velocity = Data streams, flows, rates, load, process, access, active or static
The following figure shows how different data has various values over time. Data that has no value today or in the future can be deleted, while data with unknown value can be retained.
Different data with various values over time
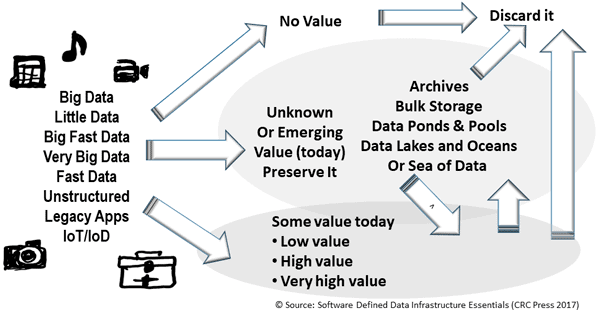
Data Value Known, Unknown and No Value
General characteristics include the value of the data which in turn determines its performance, availability, capacity, and economic considerations. Also, data can be ephemeral (temporary) or kept for longer periods of time on persistent, non-volatile storage (you do not lose the data when power is turned off). Examples of temporary scratch include work and scratch areas such as where data gets imported into, or exported out of, an application or database.
Data can also be little, big, or big and fast, terms which describe in part the size as well as volume along with the speed or velocity of being created, accessed, and processed. The importance of understanding characteristics of data and how their associated applications use them is to enable effective decision-making about performance, availability, capacity, and economics of data infrastructure resources.
Data Value
There is more to data storage than how much space capacity per cost.
All data has one of three basic values:
- No value = ephemeral/temp/scratch = Why keep it?
- Some value = current or emerging future value, which can be low or high = Keep
- Unknown value = protect until value is unlocked, or no remaining value
In addition to the above basic three, data with some value can also be further subdivided into little value, some value, or high value. Of course, you can keep subdividing into as many more or different categories as needed, after all, everything is not always the same across environments.
Besides data having some value, that value can also change by increasing or decreasing in value over time or even going from unknown to a known value, known to unknown, or to no value. Data with no value can be discarded, if in doubt, make and keep a copy of that data somewhere safe until its value (or lack of value) is fully known and understood.
The importance of understanding the value of data is to enable effective decision-making on where and how to protect, preserve, and cost-effectively store the data. Note that cost-effective does not necessarily mean the cheapest or lowest-cost approach, rather it means the way that aligns with the value and importance of the data at a given point in time.
Where to learn more
Learn more about Application Data Value, application characteristics, PACE along with data protection, software-defined data center (SDDC), software-defined data infrastructures (SDDI) and related topics via the following links:
- Part 1 – Application Data Value Characteristics Everything Is Not The Same
- Part 2 – 4 3 2 1 Data Protection Application Data Availability
- Part 3 – Application Data Characteristics Types Everything Is Not The Same
- Part 4 – Application Data Volume Velocity Variety Everything Is Not The Same
- Part 5 – Application Data Access life cycle Patterns Everything Not The Same
- Data Infrastructure server storage I/O network Recommended Reading
- World Backup Day 2018 Data Protection Readiness Reminder
- Data Infrastructure Server Storage I/O related Tradecraft Overview
- Data Infrastructure Overview, Its What’s Inside of Data Centers
- 4 3 2 1 and 3 2 1 data protection best practices
- Garbage data in, garbage information out, big data or big garbage?
- GDPR (General Data Protection Regulation) Resources Are You Ready?
- Which Enterprise HDD to use for a Content Server Platform
- The SSD Place (SSD, NVM, PM, SCM, Flash, NVMe, 3D XPoint, MRAM and related topics)
- The NVMe Place (NVMe related topics, trends, tools, technologies, tip resources)
- Data Protection Diaries (Archive, Backup/Restore, BC, BR, DR, HA,Replication, Security)

Additional learning experiences along with common questions (and answers), as well as tips can be found in Software Defined Data Infrastructure Essentials book.
What this all means and wrap-up
Data has different value at various times, and that value is also evolving. Everything Is Not The Same across various organizations, data centers, data infrastructures spanning legacy, cloud and other software defined data center (SDDC) environments. Continue reading the next post (Part IV Application Data Volume Velocity Variety Everything Not The Same) in this series here.
Ok, nuff said, for now.
Gs
Greg Schulz – Microsoft MVP Cloud and Data Center Management, VMware vExpert 2010-2017 (vSAN and vCloud). Author of Software Defined Data Infrastructure Essentials (CRC Press), as well as Cloud and Virtual Data Storage Networking (CRC Press), The Green and Virtual Data Center (CRC Press), Resilient Storage Networks (Elsevier) and twitter @storageio. Courteous comments are welcome for consideration. First published on https://storageioblog.com any reproduction in whole, in part, with changes to content, without source attribution under title or without permission is forbidden.
All Comments, (C) and (TM) belong to their owners/posters, Other content (C) Copyright 2006-2026 Server StorageIO and UnlimitedIO. All Rights Reserved. StorageIO is a registered Trade Mark (TM) of Server StorageIO.