
Preparing For World Backup Day 2017 Are You Prepared
In case you have forgotten, or were not aware, this coming Friday March 31 is World Backup Day 2017 (and recovery day). The annual day is a to remember to make sure you are protecting your applications, data, information, configuration settings as well as data infrastructures. While the emphasis is on Backup, that also means recovery as well as testing to make sure everything is working properly as part of on-prem and cloud data protection.
What the Vendors Have To Say
Today I received the following from Kylle over at TOUCHDOWNPR on behalf of their clients providing their perspectives on what World Backup Day means, or how to be prepared. Keep in mind these are not Server StorageIO clients (granted some have been in the past, or I know them, that is a disclosure btw), and this is in no way an endorsement of what they are saying, or advocating. Instead, this is simply passing along to you what was given to me.
Not included in this list? No worries, add your perspectives (politely) to the comments, or, drop me a note, and perhaps I will do a follow-up or addition to this.
Kylle O’Sullivan
TOUCHDOWNPR
Email: Kosullivan@touchdownpr.com
Mobile: 508-826-4482
Skype: Kylle.OSullivan
“Data loss and disruption happens far too often in the enterprise. Research by Ponemon in 2016 estimates the average cost of an unplanned outage has spiralled to nearly $9,000 a minute, causing crippling downtime as well as financial and reputational damage. Legacy backups simply aren’t equipped to provide seamless operations, with zero Recovery Point Objectives (RPO) should a disaster strike. In order to guarantee the availability of applications, synchronous replication with real-time analytics needs to be simple to setup, monitor and manage for application owners and economical to the organization. That way, making zero data loss attainable suddenly becomes a reality.” – Chuck Dubuque, VP Product Marketing, Tintri
“With today’s “always-on” business environment, data loss can destroy a company’s brand and customer trust. A multiple software-based strategy with software-defined and hyperconverged storage infrastructure is the most effective route for a flexible backup plan. With this tactic, snapshots, replication and stretched clusters can help protect data, whether in a local data center cluster, across data centers or across the cloud. IT teams rely on these software-based policies as the backbone of their disaster recovery implementations as the human element is removed. This is possible as the software-based strategy dictates that all virtual machines are accurately, automatically and consistently replicated to the DR sites. Through this automatic and transparent approach, no administrator action is required, saving employees time, money and providing peace of mind that business can carry on despite any outage.” – Patrick Brennan, Senior Product Marketing Manager, Atlantis Computing
“It’s only a matter of time before your datacenter experiences a significant outage, if it hasn’t already, due to a wide range of causes, from something as simple as human error or power failure to criminal activity like ransomware and cyberattacks, or even more catastrophic events like hurricanes. Shifting thinking to ‘when’ as opposed to ‘if’ something like this happens is crucial; crucial to building a more flexible and resilient IT infrastructure that can withstand any kind of disruption resulting in negative impact on business performance. World Backup Day reminds us of the importance of both having a backup plan in place and as well as conducting regular reviews of current and new technology to do everything possible to keep business running without interruption. Organizations today are highly aware that they are heavily dependent on data and critical applications, and that losing even just an hour of data can greatly harm revenues and brand reputation, sometimes beyond repair. Savvy businesses are taking an all-inclusive approach to this problem that incorporates cloud-based technologies into their disaster recovery plans. And with consistent testing and automation, they are ensuring that those plans are extremely simple to execute against in even the most challenging of situations, a key element of successfully avoiding damaging downtime.” Rob Strechay, VP Product, Zerto
“Data is one of the most valuable business assets and when it comes to data protection chief among its IT challenges is the ever-growing rate of data and the associated vulnerability. Backup needs to be reliable, fast and cost efficient. Organizations are on the defensive after a disaster and being able to recover critical data within minutes is crucial. Breakthroughs in disk technologies and pricing have led to very dense arrays that are power, cost and performance efficient. Backup has been revolutionized and organizations need to ensure they are safeguarding their most valuable commodity – not just now but for the long term. Secure archive platforms are complementary and create a complete recovery strategy.” – Geoff Barrall, COO, Nexsan
Consider the DR Options that Object Storage Adds
“Data backup and disaster recovery used to be treated as separate processes, which added complexity. But with object storage as a backup target you now have multiple options to bring backup and DR together in a single flow. You can configure a hybrid cloud and tier a portion of your data to the public cloud, or you can locate object storage nodes at different locations and use replication to provide geographic separation. So, this World Backup Day, consider how object storage has increased your options for meeting this critical need.” – Jon Toor, Cloudian CMO
Whats In Your Data Protection Toolbox
What tools, technologies do you have in your data protection toolbox? Do you only have a hammer and thus answer to every situation is that it looks like a nail? Or, do you have multiple tools, technologies combined with your various tradecraft experiences to applice different techniques?

Where To Learn More
Following these links to additional related material about backup, restore, availability, data protection, BC, BR, DR along with associated topics, trends, tools, technologies as well as techniques.
Time to restore from backup: Do you know where your data is?
February 2017 Server StorageIO Update Newsletter
Data Infrastructure Server Storage I/O Tradecraft Trends
Data Infrastructure Server Storage I/O related Tradecraft Overview
Data Infrastructure Primer and Overview (Its Whats Inside The Data Center)
What’s a data infrastructure?
Ensure your data infrastructure remains available and resilient
Part III Until the focus expands to data protection – Taking action
Welcome to the Data Protection Diaries
Backup, Big data, Big Data Protection, CMG & More with Tom Becchetti Podcast
Six plus data center software defined management dashboards
Cloud Storage Concerns, Considerations and Trends
Software Defined, Cloud, Bulk and Object Storage Fundamentals (www.objectstoragecenter.com)
Data Infrastructure Overview, Its Whats Inside of Data Centers
All You Need To Know about Remote Office/Branch Office Data Protection Backup (free webinar with registration)
Software Defined, Converged Infrastructure (CI), Hyper-Converged Infrastructure (HCI) resources
The SSD Place (SSD, NVM, PM, SCM, Flash, NVMe, 3D XPoint, MRAM and related topics)
The NVMe Place (NVMe related topics, trends, tools, technologies, tip resources)
Data Protection Diaries (Archive, Backup/Restore, BC, BR, DR, HA, RAID/EC/LRC, Replication, Security)
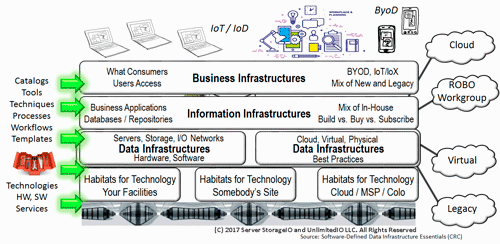
Software Defined Data Infrastructure Essentials (CRC Press 2017) including SDDC, Cloud, Container and more
Various Data Infrastructure related events, webinars and other activities
Additional learning experiences along with common questions (and answers), as well as tips can be found in Software Defined Data Infrastructure Essentials book.

What This All Means
Backup of data is important, so to is recovery which also means testing. Testing means more than just if you can read the tape, disk, SSD, USB, cloud or other medium (or location). Go a step further and verify that not only you can read the data from the medium, also if your applications or software are able to use it. Have you protected your applications (e.g. not just the data), security keys, encryption, access, dedupe and other certificates along with metadata as well as other settings? Do you have a backup or protection copy of your protection including recovery tools? What granularity of protection and recovery do you have in place, when did you test or try it recently? In other words, what this all means is be prepared, find and fix issues, as well as in the course of testing, don’t cause a disaster.
Ok, nuff said, for now.
Gs
Greg Schulz – Microsoft MVP Cloud and Data Center Management, VMware vExpert 2010-2017 (vSAN and vCloud). Author of Software Defined Data Infrastructure Essentials (CRC Press), as well as Cloud and Virtual Data Storage Networking (CRC Press), The Green and Virtual Data Center (CRC Press), Resilient Storage Networks (Elsevier) and twitter @storageio. Courteous comments are welcome for consideration. First published on https://storageioblog.com any reproduction in whole, in part, with changes to content, without source attribution under title or without permission is forbidden.
All Comments, (C) and (TM) belong to their owners/posters, Other content (C) Copyright 2006-2026 Server StorageIO and UnlimitedIO. All Rights Reserved. StorageIO is a registered Trade Mark (TM) of Server StorageIO.























{kind=link}