
How many IOPS can a HDD HHDD SSD do with VMware?

Updated 2/10/2018
This is the second post of a two-part series looking at storage performance, specifically in the context of drive or device (e.g. mediums) characteristics of How many IOPS can a HDD HHDD SSD do with VMware. In the first post the focus was around putting some context around drive or device performance with the second part looking at some workload characteristics (e.g. benchmarks).
A common question is how many IOPS (IO Operations Per Second) can a storage device or system do?
The answer is or should be it depends.
Here are some examples to give you some more insight.
For example, the following shows how IOPS vary by changing the percent of reads, writes, random and sequential for a 4K (4,096 bytes or 4 KBytes) IO size with each test step (4 minutes each).
IO Size for test | Workload Pattern of test | Avg. Resp (R+W) ms | Avg. IOP Sec (R+W) | Bandwidth KB Sec (R+W) |
4KB | 100% Seq 100% Read | 0.0 | 29,736 | 118,944 |
4KB | 60% Seq 100% Read | 4.2 | 236 | 947 |
4KB | 30% Seq 100% Read | 7.1 | 140 | 563 |
4KB | 0% Seq 100% Read | 10.0 | 100 | 400 |
4KB | 100% Seq 60% Read | 3.4 | 293 | 1,174 |
4KB | 60% Seq 60% Read | 7.2 | 138 | 554 |
4KB | 30% Seq 60% Read | 9.1 | 109 | 439 |
4KB | 0% Seq 60% Read | 10.9 | 91 | 366 |
4KB | 100% Seq 30% Read | 5.9 | 168 | 675 |
4KB | 60% Seq 30% Read | 9.1 | 109 | 439 |
4KB | 30% Seq 30% Read | 10.7 | 93 | 373 |
4KB | 0% Seq 30% Read | 11.5 | 86 | 346 |
4KB | 100% Seq 0% Read | 8.4 | 118 | 474 |
4KB | 60% Seq 0% Read | 13.0 | 76 | 307 |
4KB | 30% Seq 0% Read | 11.6 | 86 | 344 |
4KB | 0% Seq 0% Read | 12.1 | 82 | 330 |
Dell/Western Digital (WD) 1TB 7200 RPM SATA HDD (Raw IO) thread count 1 4K IO size
In the above example the drive is a 1TB 7200 RPM 3.5 inch Dell (Western Digital) 3Gb SATA device doing raw (non file system) IO. Note the high IOP rate with 100 percent sequential reads and a small IO size which might be a result of locality of reference due to drive level cache or buffering.
Some drives have larger buffers than others from a couple to 16MB (or more) of DRAM that can be used for read ahead caching. Note that this level of cache is independent of a storage system, RAID adapter or controller or other forms and levels of buffering.
Does this mean you can expect or plan on getting those levels of performance?
I would not make that assumption, and thus this serves as an example of using metrics like these in the proper context.
Building off of the previous example, the following is using the same drive however with a 16K IO size.
IO Size for test | Workload Pattern of test | Avg. Resp (R+W) ms | Avg. IOP Sec (R+W) | Bandwidth KB Sec (R+W) |
16KB | 100% Seq 100% Read | 0.1 | 7,658 | 122,537 |
16KB | 60% Seq 100% Read | 4.7 | 210 | 3,370 |
16KB | 30% Seq 100% Read | 7.7 | 130 | 2,080 |
16KB | 0% Seq 100% Read | 10.1 | 98 | 1,580 |
16KB | 100% Seq 60% Read | 3.5 | 282 | 4,522 |
16KB | 60% Seq 60% Read | 7.7 | 130 | 2,090 |
16KB | 30% Seq 60% Read | 9.3 | 107 | 1,715 |
16KB | 0% Seq 60% Read | 11.1 | 90 | 1,443 |
16KB | 100% Seq 30% Read | 6.0 | 165 | 2,644 |
16KB | 60% Seq 30% Read | 9.2 | 109 | 1,745 |
16KB | 30% Seq 30% Read | 11.0 | 90 | 1,450 |
16KB | 0% Seq 30% Read | 11.7 | 85 | 1,364 |
16KB | 100% Seq 0% Read | 8.5 | 117 | 1,874 |
16KB | 60% Seq 0% Read | 10.9 | 92 | 1,472 |
16KB | 30% Seq 0% Read | 11.8 | 84 | 1,353 |
16KB | 0% Seq 0% Read | 12.2 | 81 | 1,310 |
Dell/Western Digital (WD) 1TB 7200 RPM SATA HDD (Raw IO) thread count 1 16K IO size
The previous two examples are excerpts of a series of workload simulation tests (ok, you can call them benchmarks) that I have done to collect information, as well as try some different things out.
The following is an example of the summary for each test output that includes the IO size, workload pattern (reads, writes, random, sequential), duration for each workload step, totals for reads and writes, along with averages including IOP’s, bandwidth and latency or response time.

Want to see more numbers, speeds and feeds, check out the following table which will be updated with extra results as they become available.
Device | Vendor | Make | Model | Form Factor | Capacity | Interface | RPM Speed | Raw Test Result |
HDD | HGST | Desktop | HK250-160 | 2.5 | 160GB | SATA | 5.4K | |
HDD | Seagate | Mobile | ST2000LM003 | 2.5 | 2TB | SATA | 5.4K | |
HDD | Fujitsu | Desktop | MHWZ160BH | 2.5 | 160GB | SATA | 7.2K | |
HDD | Seagate | Momentus | ST9160823AS | 2.5 | 160GB | SATA | 7.2K | |
HDD | Seagate | MomentusXT | ST95005620AS | 2.5 | 500GB | SATA | 7.2K(1) | |
HDD | Seagate | Barracuda | ST3500320AS | 3.5 | 500GB | SATA | 7.2K | |
HDD | WD/Dell | Enterprise | WD1003FBYX | 3.5 | 1TB | SATA | 7.2K | |
HDD | Seagate | Barracuda | ST3000DM01 | 3.5 | 3TB | SATA | 7.2K | |
HDD | Seagate | Desktop | ST4000DM000 | 3.5 | 4TB | SATA | HDD | |
HDD | Seagate | Capacity | ST6000NM00 | 3.5 | 6TB | SATA | HDD | |
HDD | Seagate | Capacity | ST6000NM00 | 3.5 | 6TB | 12GSAS | HDD | |
HDD | Seagate | Savio 10K.3 | ST9300603SS | 2.5 | 300GB | SAS | 10K | |
HDD | Seagate | Cheetah | ST3146855SS | 3.5 | 146GB | SAS | 15K | |
HDD | Seagate | Savio 15K.2 | ST9146852SS | 2.5 | 146GB | SAS | 15K | |
HDD | Seagate | Ent. 15K | ST600MP0003 | 2.5 | 600GB | SAS | 15K | |
SSHD | Seagate | Ent. Turbo | ST600MX0004 | 2.5 | 600GB | SAS | SSHD | |
SSD | Samsung | 840 PRo | MZ-7PD256 | 2.5 | 256GB | SATA | SSD | |
HDD | Seagate | 600 SSD | ST480HM000 | 2.5 | 480GB | SATA | SSD | |
SSD | Seagate | 1200 SSD | ST400FM0073 | 2.5 | 400GB | 12GSAS | SSD | |
Performance characteristics 1 worker (thread count) for RAW IO (non-file system)
Note: (1) Seagate Momentus XT is a Hybrid Hard Disk Drive (HHDD) based on a 7.2K 2.5 HDD with SLC nand flash integrated for read buffer in addition to normal DRAM buffer. This model is a XT I (4GB SLC nand flash), may add an XT II (8GB SLC nand flash) at some future time.
As a starting point, these results are raw IO with file system based information to be added soon along with more devices. These results are for tests with one worker or thread count, other results will be added with such as 16 workers or thread counts to show how those differ.
The above results include all reads, all writes, mix of reads and writes, along with all random, sequential and mixed for each IO size. IO sizes include 4K, 8K, 16K, 32K, 64K, 128K, 256K, 512K, 1024K and 2048K. As with any workload simulation, benchmark or comparison test, take these results with a grain of salt as your mileage can and will vary. For example you will see some what I consider very high IO rates with sequential reads even without file system buffering. These results might be due to locality of reference of IO’s being resolved out of the drives DRAM cache (read ahead) which vary in size for different devices. Use the vendor model numbers in the table above to check the manufactures specs on drive DRAM and other attributes.
If you are used to seeing 4K or 8K and wonder why anybody would be interested in some of the larger sizes take a look at big fast data or cloud and object storage. For some of those applications 2048K may not seem all that big. Likewise if you are used to the larger sizes, there are still applications doing smaller sizes. Sorry for those who like 512 byte or smaller IO’s as they are not included. Note that for all of these unless indicated a 512 byte standard sector or drive format is used as opposed to emerging Advanced Format (AF) 4KB sector or block size. Watch for some more drive and device types to be added to the above, along with results for more workers or thread counts, along with file system and other scenarios.
Using VMware as part of a Server, Storage and IO (aka StorageIO) test platform
![]()
The above performance results were generated on Ubuntu 12.04 (since upgraded to 14.04 which was hosted on a VMware vSphere 5.1 (upgraded to 5.5U2) purchased version (you can get the ESXi free version here) with vCenter enabled system. I also have VMware workstation installed on some of my Windows-based laptops for doing preliminary testing of scripts and other activity prior to running them on the larger server-based VMware environment. Other VMware tools include vCenter Converter, vSphere Client and CLI. Note that other guest virtual machines (VMs) were idle during the tests (e.g. other guest VMs were quiet). You may experience different results if you ran Ubuntu native on a physical machine or with different adapters, processors and device configurations among many other variables (that was a disclaimer btw ;) ).
All of the devices (HDD, HHDD, SSD’s including those not shown or published yet) were Raw Device Mapped (RDM) to the Ubuntu VM bypassing VMware file system.
| Example of creating an RDM for local SAS or SATA direct attached device. vmkfstools -z /vmfs/devices/disks/naa.600605b0005f125018e923064cc17e7c /vmfs/volumes/dat1/RDM_ST1500Z110S6M5.vmdk The above uses the drives address (find by doing a ls -l /dev/disks via VMware shell command line) to then create a vmdk container stored in a dat. Note that the RDM being created does not actually store data in the .vmdk, it’s there for VMware management operations. |
If you are not familiar with how to create a RDM of a local SAS or SATA device, check out this post to learn how.This is important to note in that while VMware was used as a platform to support the guest operating systems (e.g. Ubuntu or Windows), the real devices are not being mapped through or via VMware virtual drives.
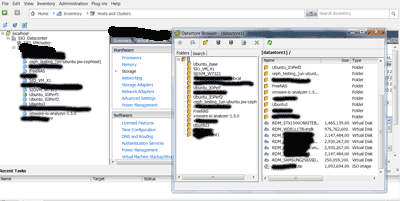
The above shows examples of RDM SAS and SATA devices along with other VMware devices and dats. In the next figure is an example of a workload being run in the test environment.

One of the advantages of using VMware (or other hypervisor) with RDM’s is that I can quickly define via software commands where a device gets attached to different operating systems (e.g. the other aspect of software defined storage). This means that after a test run, I can quickly simply shutdown Ubuntu, remove the RDM device from that guests settings, move the device just tested to a Windows guest if needed and restart those VMs. All of that from where ever I happen to be working from without physically changing things or dealing with multi-boot or cabling issues.
Where To Learn More
View additional NAS, NVMe, SSD, NVM, SCM, Data Infrastructure and HDD related topics via the following links.
- Can we get a side of context with them IOPS and other storage metrics?
- WHEN AND WHERE TO USE NAND FLASH SSD FOR VIRTUAL SERVERS
- Revisiting RAID storage remains relevant and resources
- NVMe overview and primer – Part I
- Part 1 of HDD for content servers series Trends and Content Application Servers
- Part 2 of HDD for content servers series Content application server decisions and testing plans
- Part 3 of HDD for content servers series Test hardware and software configuration
- Part 4 of HDD for content servers series Large file I/O processing
- Part 5 of HDD for content servers series Small file I/O processing
- Part 6 of HDD for content servers series General I/O processing
- Part 7 of HDD for content servers series How HDD continue to evolve over different generations and wrap up
- As the platters spin, HDD’s for cloud, virtual and traditional storage environments
- How many IOPS can a HDD, HHDD or SSD do?
- Hard Disk Drives (HDD) for Virtual Environments
- Server and Storage I/O performance and benchmarking tools
- Server storage I/O performance benchmark workload scripts Part I and Part II
- How to test your HDD, SSD or all flash array (AFA) storage fundamentals
- What is the best server storage I/O workload benchmark? It depends
- I/O, I/O how well do you know about good or bad server and storage I/Os?
- Big Files Lots of Little File Processing Benchmarking with Vdbench
- Part II – NVMe overview and primer (Different Configurations)
- Part III – NVMe overview and primer (Need for Performance Speed)
- Part IV – NVMe overview and primer (Where and How to use NVMe)
- Part V – NVMe overview and primer (Where to learn more, what this all means)
- PCIe Server I/O Fundamentals
- If NVMe is the answer, what are the questions?
- NVMe Wont Replace Flash By Itself
- Via Computerweekly – NVMe discussion: PCIe card vs U.2 and M.2
- Intel and Micron unveil new 3D XPoint Non Volatie Memory (NVM) for servers and storage
- Part II – Intel and Micron new 3D XPoint server and storage NVM
- Part III – 3D XPoint new server storage memory from Intel and Micron
- Server storage I/O benchmark tools, workload scripts and examples (Part I) and (Part II)
- Data Infrastructure Overview, Its Whats Inside of Data Centers
- All You Need To Know about Remote Office/Branch Office Data Protection Backup (free webinar with registration)
- Software Defined, Converged Infrastructure (CI), Hyper-Converged Infrastructure (HCI) resources
- The SSD Place (SSD, NVM, PM, SCM, Flash, NVMe, 3D XPoint, MRAM and related topics)
- The NVMe Place (NVMe related topics, trends, tools, technologies, tip resources)
- Data Protection Diaries (Archive, Backup/Restore, BC, BR, DR, HA, RAID/EC/LRC, Replication, Security)
- Software Defined Data Infrastructure Essentials (CRC Press 2017) including SDDC, Cloud, Container and more
- Various Data Infrastructure related events, webinars and other activities
- www.objectstoragecenter.com and Software Defined, Cloud, Bulk and Object Storage Fundamentals
- Server Storage I/O Network PCIe Fundamentals
Additional learning experiences along with common questions (and answers), as well as tips can be found in Software Defined Data Infrastructure Essentials book.

What This All Means
So how many IOPs can a device do?
That depends, however have a look at the above information and results.
Check back from time to time here to see what is new or has been added including more drives, devices and other related themes.
Ok, nuff said, for now.
Gs
Greg Schulz – Microsoft MVP Cloud and Data Center Management, VMware vExpert 2010-2017 (vSAN and vCloud). Author of Software Defined Data Infrastructure Essentials (CRC Press), as well as Cloud and Virtual Data Storage Networking (CRC Press), The Green and Virtual Data Center (CRC Press), Resilient Storage Networks (Elsevier) and twitter @storageio. Courteous comments are welcome for consideration. First published on https://storageioblog.com any reproduction in whole, in part, with changes to content, without source attribution under title or without permission is forbidden.
All Comments, (C) and (TM) belong to their owners/posters, Other content (C) Copyright 2006-2026 Server StorageIO and UnlimitedIO. All Rights Reserved. StorageIO is a registered Trade Mark (TM) of Server StorageIO.



















{kind=link}