
What is Azure Elastic SAN
Azure Elastic SAN (AES) is a new (now GA) Azure Cloud native storage service that provides scalable, resilient, easy management with rapid provisioning, high performance, and cost-effective storage. AES (figure 1) supports many workloads and computing resources. Workloads that benefit from AES include tier 1 and tier 2, such as Mission Critical, Database, and VDI, among others traditionally relying upon consolidated Storage Area Network (SAN) shared storage.
Compute resources that can use AES, including bare metal (BM) physical machines (PM), virtual machines (VM), and containers, among others, using iSCSI for access. AES is accessible by computing resources and services within the Azure Cloud in various regions (check Azure Website for specific region availability) and from on-prem core and edge locations using iSCSI. The AES management experience and value proposition are similar to traditional hardware or software-defined shared SAN storage combined with Azure cloud-based management capabilities.

Figure 1 General Concept and Use of Azure Elastic SAN (AES)
While Microsoft Azure describes AES as a cloud-native storage solution, that does not mean that AES is only for containers and other cloud-native apps or DevOPS. Rather, AES has been built for and is native to the cloud (e.g., software-defined) that can be accessed by various compute and other resources (e.g., VMs, Containers, AKS, etc) using iSCSI.
How Azure Elastic SAN differs from other Azure Storage
AES differs from traditional Azure block storage (e.g., Azure Disks) in that the storage is independent of the host compute server (e.g., BM, PM, VM, containers). With AES, similar to a conventional software-defined or hardware-based shared SAN solution, storage is disaggregated from host servers for sharing and management using iSCSI for connectivity. By comparison, AES differs from traditional Azure VM-based storage typically associated with a given virtual machine in a DAS (Direct Attached Storage) type configuration. Likewise, similar to conventional on-prem environments, there is a mix of DAS and SAN, including some host servers that leverage both.
AES supports Azure VM, Azure Kubernetes Service (AKS), cloud-native, edge, and on-prem computing (BM, VM, etc.) via iSCSI. Support for Azure VMware Solution (AVS) is in preview; check the Microsoft Azure website for updates and new feature functionality enhancements.
Does this mean everything is moving to AES? Similar to traditional SANs, there are roles and needs for various storage options, including DAS, shared block, file, and object, among storage offerings. Likewise, Microsoft and Azure have expanded their storage offerings to include AES, DAS (azure disks, including Ultra, premium, and standard, among other options), append, block, and page blobs (objects), and files, including Azure file sync, tables, and Data Box, among other storage services.
Azure Elastic Storage Feature Highlights
AES feature highlights include, among others:
- Management via Azure Portal and associated tools
- Azure cloud-based shared scalable bock storage
- Scalable capacity, low latency, and high performance (IOPs and throughput)
- Space capacity-optimized without the need for data reduction
- Accessible from within Azure cloud and from on-prem using iSCSI
- Supports Azure compute (VMs, Containers/AKS, Azure VMware Solution)
- On-prem access via iSCSI from PM/BM, VM, and containers
- Variable number of volumes and volume size per volume group
- Flexible easy to use Azure cloud-based management
- Encryption and network private endpoint security
- Local (LRS) and Zone (ZRS) with replication resiliency
- Volume snapshots and cluster support
Who is Azure Elastic SAN for
AES is for those who need cost-effective, shared, resilient, high capacity, high performance (IOPS, Bandwidth), and low latency block storage within Azure and from on-prem access. Others who can benefit from AES include those who need shared block storage for clustering app workloads, server and storage consolidation, and hybrid and migration. Another consideration is for those familiar with traditional hardware and software-defined SANs to facilitate hybrid and migration strategies.
How Azure Elastic SAN works
Azure Elastic SAN is a software-defined (cloud native if you prefer) block storage offering that presents a virtual SAN accessible within Azure Cloud and to on-prem core and edge locations currently via iSCSI. Using iSCSI, Azure VMs, Clusters, Containers, Azure VMware Solution among other compute and services, and on-prem BM/PM, VM, and containers, among others, can access AES storage volumes.
From the Azure Portal or associated tools (Azure CLI or PowerShell), create an AES SAN, giving it a 3 to 24-character name and specify storage capacity (base units with performance and any additional space capacity). Next, create a Volume Group, assigning it to a specific subscription and resource group (new or existing), then specify which Azure Region to use, type of redundancy (LRS or GRS), and Zone to use. LRS provides local redundancy, while ZRS provides enhanced zone resiliency, with highspeed synchronous resiliency without setting up multiple SAN systems and their associated replication configurations along with networking considerations (e.g., Azure takes care of that for you within their service).
The next step is to create volumes by specifying the volume name, volume group to use, volume size in GB, maximum IOPs, and bandwidth. Once you have made your AES volume group and volumes, you can create private endpoints, change security and access controls, and access the volumes from Azure or on-prem resources using iSCSI. Note that AES currently needs to be LRS (not ZRS) for clustered shared storage and that Key management includes using your keys with Azure key vault.
Using Azure Elastic SAN
Using AES is straightforward, and there are good easy to follow guides from Microsoft Azure, including the following:
The following images show what AES looks like from the Azure Portal, as well as from an Azure Windows Server VM and an onprem physical machine (e.g., Windows 10 laptop).
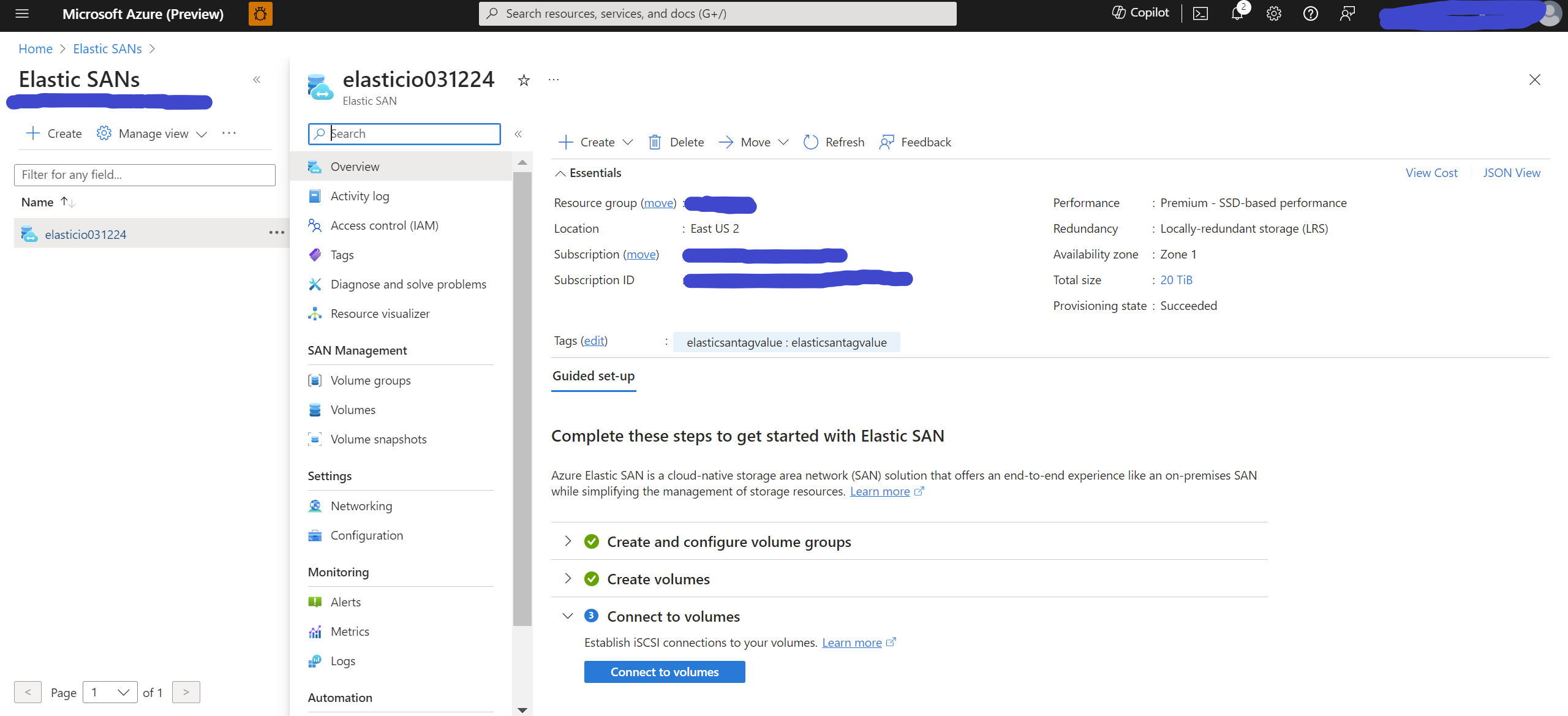
Figure 2 AES Azure Portal Big Picture
Figure 3 AES Volume Groups Portal View
Figure 4 AES Volumes Portal View
Figure 5 AES Volume Snapshot Views
Figure 6 AES Connected Volume Portal View
Figure 7 AES Volume iSCSI view from on-prem Windows Laptop
Figure 8 AES iSCSI Volume attached to Azure VM
Azure Elastic SAN Cost Pricing
The cost of AES is elastic, depending on whether you scale capacity with performance (e.g., base unit) or add more space capacity. If you need more performance, add base unit capacity, increasing IOPS, bandwidth, and space. In other words, base capacity includes storage space and performance, which you can grow in various increments. Remember that AES storage resources get shared across volumes within a volume group.
Azure Elastic SAN is billed hourly based on a monthly per-capacity base unit rate, with a minimum of 1TB provisioned capacity with minimum performance (e.g., 5,000 IOPs, 200MBps bandwidth). The base unit rate varies by region and type of redundancy, aka resiliency. For example, at the time of this writing, looking at US East, the Local Redundant Storage (LRS) base unit rate is 1TB with 5,000 IOPs and 200MBps bandwidth, costing $81.92 per unit per month.
The above example breaks down to a rate of $0.08 per GB per month, or $0.000110 per GB per hour (assumes 730 hours per month). An example of simply adding storage capacity without increasing base unit (e.g., performance) for US East is $61.44 per month. That works out to $0.06 per GB per month (no additional provisioned IOPs or Bandwidth) or $0.000083 per GB per hour.
Note that there are extra fees for Zone Redundant Storage (ZRS). Learn more about Azure Elastic SAN pricing here, as well as via a cost calculator here.
Azure Elastic SAN Performance
Performance for Azure Elastic SAN includes IOPs, Bandwidth, and Latency. AES IOPs get increased in increments of 5,000 per base TB. Thus, an AES with a base of 10TB would have 50,000 IOPs distributed (shared) across all of its volumes (e.g., volumes are not restricted). For example, if the base TB is increased from 10TB to 20TB, then the IOPs would increase from 50,000 to 100,000 IOPs.
On the other hand, if the base capacity (10TB) is not increased, only the storage capacity would increase from 10TB to 20TB, and the AES would have more capacity but still only have the 50,000 IOPs. AES bandwidth throughput increased by 200MBps per TB. For example, a 5TB AES would have 5 x 200MBps (1,000 MBps) throughput bandwidth shared across the volume groups volumes.
Note that while the performance gets shared across volumes, individual volume performance is determined by its capacity with a maximum of 80,000 IOPs and up to 1,024 MBps. Thus, to reach 80,000 IOPS and 1,024 MBps, an AES volume would have to be at least 107GB in space capacity. Also, note that the aggregate performance of all volumes cannot exceed the total of the AES. If you need more performance, then create another AES.
Will all VMs or compute resources see performance improvements with AES? Traditional Azure Disks associated with VMs have per-disk performance resource limits, including IOPs and Bandwidth. Likewise, VMs have storage limits based on their instance type and size, including the number of disks (HDD or SSD), performance (IOPS and bandwidth), and the number of CPUs and memory.
What this means is that an AES volume could have more performance than what a given VM is limited to. Refer to your VM instance sizing and configuration to determine its IOP and bandwidth limits; if needed, explore changing the size of your VM instance to leverage the performance of Azure Elastic SAN storage.
Additional Resources Where to learn more
The following links are additional resources to learn about Microsoft Azure Elastic SAN and related data infrastructures and tradecraft topics.
Azure AKS Storage Concepts
Azure Elastic SAN (AES) Documentation and Deployment Guides
Azure Elastic SAN Microsoft Blog
Azure Elastic SAN Overview
Azure Elastic SAN Performance topics
Azure Elastic SAN Pricing calculator
Azure Products by Region (see where AES is currently available)
Azure Storage Offerings
Azure Virtual Machine (VM) sizes
Azure Virtual Machine (VM) types
Azure Elastic SAN General Pricing
Azure Storage redundancy
Azure Service Level Agreements (SLA)
StorageIOBlog.com Data Box Family
StorageIOBlog.com Data Box Review
StorageIOBlog.com Data Box Test Drive
StorageIOblog.com Microsoft Hyper-V Alive Enhanced with Win Server 2025
StorageIOblog.com If NVMe is the answer, what are the questions?
StorageIOblog.com NVMe Primer (or refresh)
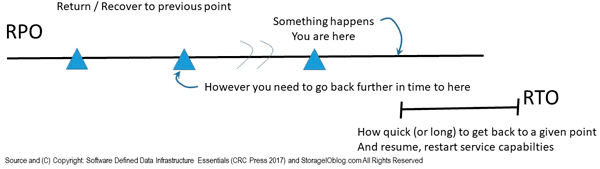
RTO Context Matters (Blog Post)
Additional learning experiences along with common questions (and answers), are found in my Software Defined Data Infrastructure Essentials book.

What this all means
Azure Elastic SAN (AES) is a new and now generally available shared block storage offering that is accessible using iSCSI from within Azure Cloud and on-prem environments. Even with iSCSI, AES is relatively easy to set up and use for shared storage, mainly if you are used to or currently working with hardware or software-defined SAN storage solutions.
With NVMe over TCP fabrics gaining industry and customer traction, I’m hoping for Microsoft to adding that in the future. Currently, AES supports LRS and ZRS for redundancy, and an excellent future enhancement would be to add Geo Redundant Storage (GRS) capabilities for those who need it.
I like the option of elastic shared storage regarding performance, availability, capacity, and economic costs (PACE). Suppose you understand the value proposition of evolving from dedicated DAS to shared SAN (independent of the underlying fabric network); or are currently using some form of on-prem shared block storage. In that case, you will find AES familiar and easy to use. Granted, AES is not a solution for everything as there are roles for other block storage, including DAS such as Azure disks and VMs within Azure, along with on-prem DAS, as well as file, object, and blobs, tables, among others.
Wrap up
The notion that all cloud storage must be objects or blobs is tied those who only need, provide, or prefer those solutions. The reality is that everything is not the same. Thus, there is a need for various storage mediums, devices, tiers, access, and types of services. Microsoft and Azure have done an excellent job of providing. I like what Microsoft Azure is doing with Azure Elastic SAN.
Ok, nuff said, for now.
Cheers Gs
Greg Schulz – Nine time Microsoft MVP Cloud and Data Center Management, VMware vExpert 2010-2018. Author of Software Defined Data Infrastructure Essentials (CRC Press), as well as Cloud and Virtual Data Storage Networking (CRC Press), The Green and Virtual Data Center (CRC Press), Resilient Storage Networks (Elsevier) and twitter @storageio. Courteous comments are welcome for consideration. First published on https://storageioblog.com any reproduction in whole, in part, with changes to content, without source attribution under title or without permission is forbidden.
All Comments, (C) and (TM) belong to their owners/posters, Other content (C) Copyright 2006-2026 Server StorageIO and UnlimitedIO. All Rights Reserved. StorageIO is a registered Trade Mark (TM) of UnlimitedIO LLC.























{kind=link}