Amazon Web Services (AWS) today announced the beta of their new storage gateway functionality that enables access of Amazon S3 (Simple Storage Services) from your different applications using an appliance installed in your data center site. With this beta launch, Amazon joins other startup vendors who are providing standalone gateway appliance products (e.g. Nasuni etc) along with those who have disappeared from the market (e.g. Cirtas). In addition to gateway vendors, there are also those with cloud access added to their software tools such as (e.g. Jungle Disk that access both Rack space and Amazon S3 along with Commvault Simpana Cloud connector among others). There are also vendors that have joined cloud access gateways as part of their storage systems such as TwinStrata among others. Even EMC (and here) has gotten into the game adding qualified cloud access support to some of their products.
What is a cloud storage gateway?
Before going further, lets take a step back and address what for some may be a fundemental quesiton of what is a cloud storage gateway?
Cloud services such as storage are accessed via some type of network, either the public Internet or a private connection. The type of cloud service being accessed (figure 1) will decide what is needed. For example, some services can be accessed using a standard Web browser, while others must plug-in or add-on modules. Some cloud services may need downloading an application, agent, or other tool for accessing the cloud service or resources, while others give an on-site or on-premisess appliance or gateway.

Figure 1: Accessing and using clouds (From Cloud and Virtual Data Storage Networking (CRC Press))
Cloud access software and gateways or appliances are used for making cloud storage accessible to local applications. The gateways, as well as enabling cloud access, provide replication, snapshots, and other storage services functionality. Cloud access gateways or server-based software include tools from BAE, Citrix, Gladinet, Mezeo, Nasuni, Openstack, Twinstrata among others. In addition to cloud gateway appliances or cloud points of presence (cpops), access to public services is also supported via various software tools. Many data protection tools including backup/restore, archiving, replication, and other applications have added (or are planning to add) support for access to various public services such as Amazon, Goggle, Iron Mountain, Microsoft, Nirvanix, or Rack space among several others.
Some of the tools have added native support for one or more of the cloud services leveraging various applicaiotn programming interfaces (APIs), while other tools or applications rely on third-party access gateway appliances or a combination of native and appliances. Another option for accessing cloud resources is to use tools (Figure 2) supplied by the service provider, which may be their own, from a third-party partner, or open source, as well as using their APIs to customize your own tools.

Figure 2: Cloud access tools (From Cloud and Virtual Data Storage Networking (CRC Press))
For example, I can use my Amazon S3 or Rackspace storage accounts using their web and other provided tools for basic functionality. However, for doing backups and restores, I use the tools provided by the service provider, which then deal with two different cloud storage services. The tool presents an interface for defining what to back up, protect, and restore, as well as enabling shared (public or private) storage devices and network drives. In addition to providing an interface (Figure 2), the tool also speaks specific API and protocols of the different services, including PUT (create or update a container), POST (update header or Meta data), LIST (retrieve information), HEAD (metadata information access), GET (retrieve data from a container), and DELETE (remove container) functions. Note that the real behavior and API functionality will vary by service provider. The importance of mentioning the above example is that when you look at some cloud storage services providers, you will see mention of PUT, POST, LIST, HEAD, GET, and DELETE operations as well as services such as capacity and availability. Some services will include an unlimited number of operations, while others will have fees for doing updates, listing, or retrieving your data in addition to basic storage fees. By being aware of cloud primitive functions such as PUT or POST and GET or LIST, you can have a better idea of what they are used for as well as how they play into evaluating different services, pricing, and services plans.
Depending on the type of cloud service, various protocols or interfaces may be used, including iSCSI, NAS NFS, HTTP or HTTPs, FTP, REST, SOAP, and Bit Torrent, and APIs and PaaS mechanisms including .NET or SQL database commands, in addition to XM, JSON, or other formatted data. VMs can be moved to a cloud service using file transfer tools or upload capabilities of the provider. For example, a VM such as a VMDK or VHD is prepared locally in your environment and then uploaded to a cloud provider for execution. Cloud services may give an access program or utility that allows you to configure when, where, and how data will be protected, similar to other backup or archive tools.
Some traditional backup or archive tools have added direct or via third party support for accessing IaaS cloud storage services such as Amazon, Rack space, and others. Third-party access appliance or gateways enable existing tools to read and write data to a cloud environment by presenting a standard interface such as NAS (NFS and/or CIFS) or iSCSI (Block) that gets mapped to the back-end cloud service format. For example, if you subscribe to Amazon S3, storage is allocated as objects and various tools are used to use or utilize. The cloud access software or appliance understands how to communicate with the IaaS storage APIs and abstracts those from how they are used. Access software tools or gateways, in addition to translating or mapping between cloud APIs, formats your applications including security with encryption, bandwidth optimization, and data footprint reduction such as compression and de-duplication. Other functionality include reporting, management tools that support various interfaces, protocols and standards including SNMP or SNIA, Storage Management Initiative Specification (SMIS), and Cloud Data Management Initiative (CDMI).
First impression: Interesting, good move Amazon, I was ready to install and start testing it today
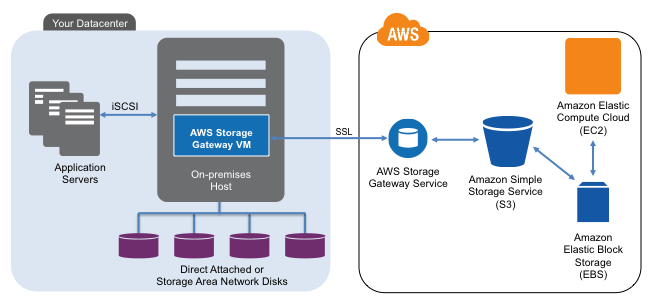
The good news here is that Amazon is taking steps to make it easier for your existing applications and IT environments to use and leverage clouds for private and hybrid adoption models with both an Amazon branded and managed services, technology and associated tools.
This means leveraging your existing Amazon accounts to simplify procurement, management, ongoing billing as well as leveraging their infrastructure. As a standalone gateway appliance (e.g. it does not have to be bundled as part of a specific backup, archive, replication or other data management tool), the idea is that you can insert the technology into your existing data center between your servers and storage to begin sending a copy of data off to Amazon S3. In addition to sending data to S3, the integrated functionality with other AWS services should make it easier to integrated with Elastic Cloud Compute (EC2) and Elastic Block storage (EBS) capabilities including snapshots for data protection.
Thus my first impression of AWS storage gateway at a high level view is good and interesting resulting in looking a bit deeper resulting in a second impression.
Second impression: Hmm, what does it really do and require, time to slow down and do more home work
Digging deeper and going through the various publicly available material (note can only comment or discuss on what is announced or publicly available) results in a second impression of wanting and needing to dig deeper based on some of caveats. Now granted and in fairness to Amazon, this is of course a beta release and hence while on first impression it can be easy to miss the notice that it is in fact a beta so keep in mind things can and hopefully will change.
Pricing aside, which means as with any cloud or managed storage service, you will want to do a cost analysis model just as you would for procuring physical storage, look into the cost of monthly gateway fee along with its associated physical service running VMware ESXi configuration that you will need to supply. Chances are that if you are an average sized SMB, you have a physical machine (PM) laying around that you can throw a copy of ESXi on to if you dont already have room for some more VMs on an existing one.
You will also need to assess the costs for using the S3 storage including space capacity charges, access and other fees as well as charges for doing snapshots or using other functionality. Again these are not unique to Amazon or their cloud gateway and should be best practices for any service or solution that you are considering. Amazon makes it easy by the way to see their base pricing for different tiers of availability, geographic locations and optional fees.
Speaking of accessing the cloud, and cloud conversations, you will also want to keep in mind what your networking bandwidth service requirements will be to move data to Amazon that might not already be doing so.
Another thing to consider with the AWS storage gateway is that it does not replace your local storage (that is unless you move your applications to Amazon EC2 and EBS), rather makes a copy of what every you save locally to a remote Amazon S3 storage pool. This can be good for high availability (HA), business continuance (BC), disaster recovery (DR) and compliance among other data management needs. However in your cost model you also need to keep in mind that you are not replacing your local storage, you are adding to it via the cloud which should be seen as complimenting and enhancing your private now to be hybrid environment.
Walking the cloud data protection talk
FWIW, I leverage a similar model where I use a service (Jungle Disk) where critical copies of my data get sent to that service which in turn places copies at Rack space (Jungledisks parent) and Amazon S3. What data goes to where depends on different policies that I have established. I also have local backup copies as well as master gold disaster copy stored in a secure offsite location. The idea is that when needed, I can get a good copy restored from my cloud providers quickly regardless of where I am if the local copy is not good. On the other hand, experience has already demonstrated that without sufficient network bandwidth services, if I need to bring back 100s of GBytes or TBytes of data quickly, Im going to be better off bring back onsite my master gold copy, then applying fewer, smaller updates from the cloud service. In other words, the technologies compliment each other.
By the way, a lesson learned here is that once my first copy is made which have data footprint reduction (DFR) techniques applied (e.g. compress, de dupe, optimized, etc), later copies occur very fast. However subsequent restores of those large files or volumes also takes longer to retrieve from the cloud vs. sending up changed versions. Thus be aware of backup vs. restore times, something of which will apply to any cloud provider and can be mitigated by appliances that do local caching. However also keep in mind that if a disaster occurs, will your local appliance be affected and its cache rendered useless.
Getting back to AWS storage gateway and my second impression is that at first it sounded great.
However then I realized it only supports iSCSI and FWIW, nothing wrong with iSCSI, I like it and recommend using it where applicable, even though Im not using it. I would like to have seen a NAS (either NFS and/or CIFS) support for a gateway making it easier for in my scenario different applications, servers and systems to use and leverage the AWS services, something that I can do with my other gateways provided via different software tools. Granted for those environments that already are using iSCSI for your servers that will be using AWS storage gateway, then this is a non issue while for others it is a consideration including cost (time) to factor in to prepare your environment for using the ability.
Depending on the amount of storage you have in your environment, the next item that caught my eye may or may not be an issue that the iSCSI gateway supports up to 1TB volumes and up to 12 of them hence a largest capacity of 12TB under management. This can be gotten around by using multiple gateways however the increased complexity balanced to the benefit the functionality is something to consider.
Third impression: Dig deeper, learn more, address various questions
This leads up to my third impression the need to dig deeper into what AWS storage gateway can and cannot do for various environments. I can see where it can be a fit for some environments while for others at least in its beta version will be a non starter. In the meantime, do your homework, look around at other options which ironically by having Amazon launching a gateway service may reinvigorate the market place of some of the standalone or embedded cloud gateway solution providers.
What is needed for using AWS storage gateway
In addition to having an S3 account, you will need to acquire for a monthly fee the storage gateway appliance which is software installed into a VMware ESXi hypervisor virtual machine (VM). The requirements are VMware ESXi hypervisor (v4.1) on a physical machine (PM) with at least 7.5GB of RAM and four (4) virtual processors assigned to the appliance VM along with 75GB of disk space for the Open Virtual Alliance (OVA) image installation and data. You will also need to have an proper sized network connection to Amazon. You will also need iSCSI initiators on either Windows server 2008, Windows 7 or Red Hat Enterprise Linux.
Note that the AWS storage gateway beta is optimized for block write sizes greater than 4Kbytes and warns that smaller IO sizes can cause overhead resulting in lost storage space. This is a consideration for systems that have not yet changed your file systems and volumes to use the larger allocation sizes.
Some closing thoughts, tips and comments:
- Congratulations to Amazon for introducing and launching an AWS branded storage gateway.
- Amazon brings trust the value of trust to a cloud relationship.
- Initially I was excited about the idea of using a gateway that any of may systems could use my S3 storage pools with vs. using gateway access functions that are part of different tools such as my backup software or via Amazon web tools. Likewise I was excited by the idea of having an easy to install and use gateway that would allow me to grow in a cost effective way.
- Keep in mind that this solution or at least in its beta version DOES NOT replace your existing iSCSI based storage needs, instead it compliments what you already have.
- I hope Amazon listens carefully to what they customers and prospects want vs. need to evolve the functionality.
- This announcement should reinvigorate some of the cloud appliance vendors as well as those who have embedded functionality to Amazon and other providers.
- Keep bandwidth services and optimization in mind both for sending data as well as for when retrieving during a disaster or small file restore.
- In concept, the AWS storage gateway is not all that different than appliances that do snapshots and other local and remote data protection such as those from Actifio, EMC (Recoverpoint), Falconstor or dedicated gateways such as those from Nasuni among others.
- Here is a link to added AWS storage gateways frequently asked questions (FAQs).
- If the AWS were available with a NAS interface, I would probably be activating it this afternoon even with some of their other requirements and cost aside.
- Im still formulating my fourth impression which is going to take some time, perhaps if I can get Amazon to help sell more of my books so that I can get some money to afford to test the entire solution leveraging my existing S3, EC2 and EBS accounts I might do so in the future, otherwise for now, will continue to research.
- Learn more about the AWS storage gateway beta, check out this free Amazon web cast on February 23, 2012.
Learn more abut cloud based data protection, data footprint reduction, cloud gateways, access and management, check out my book Cloud and Virtual Data Storage Networking (CRC Press) which is of course available on Amazon Kindle as well as via hard cover print copy also available at Amazon.com.
Ok, nuff said for now, I need to get back to some other things while thinking about this all some more.
Cheers gs
Greg Schulz – Author Cloud and Virtual Data Storage Networking (CRC Press, 2011), The Green and Virtual Data Center (CRC Press, 2009), and Resilient Storage Networks (Elsevier, 2004)
twitter @storageio
All Comments, (C) and (TM) belong to their owners/posters, Other content (C) Copyright 2006-2012 StorageIO and UnlimitedIO All Rights Reserved






























{kind=link}