ToE NVMeoF TCP Performance Line Boost Performance Reduce Costs.
Yes, you read that correct; leverage TCP offload Engines (TOE) to boost the performance of TCP-based NVMeoF (e.g., NVMe over Fabrics) while reducing costs. Keep in mind that there is a difference between cutting costs (something that causes or moves problems and complexities elsewhere) and reducing and removing costs (e.g., finding, fixing, removing complexities).
Reducing or cutting costs can be easy by simply removing items for lower-priced items and introducing performance bottlenecks or some other compromise. Likewise, boosting performance can be addressed by throwing (deploying) more hardware (and or software) at the problem resulting in higher costs or some other compromise.
On the other hand, as mentioned above, finding, fixing, removing the complexity and overhead results in cost savings while doing the same work or enabling more work done via the same costs, maximizing hardware, software, and network costs. In other words, a better return on investment (ROI) and a lower total cost of ownership (TCO).
Software Defined Storage and Networks Need Hardware
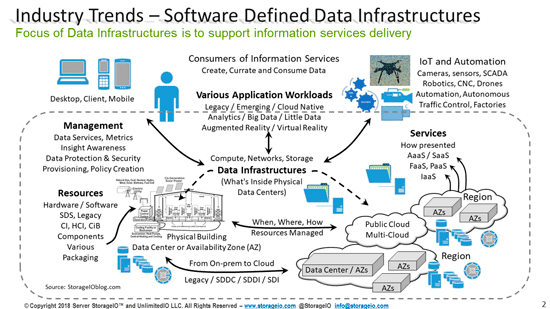
With the continued shift towards software-defined data centers, software-defined data infrastructures, software-defined storage, software-defined networking, and software-defined everything, those all need something in common, and that is hardware-based compute processing.
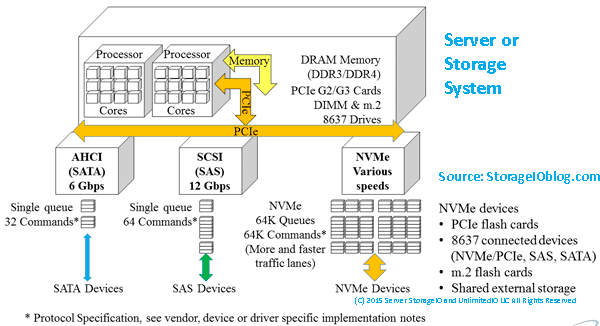
In the case of software-defined storage, including standalone, shared fabric or networked-based, converged infrastructure (CI) or hyper-converged infrastructure (HCI) deployment models, there is the need for CPU compute, memory, and I/O, in addition to storage devices. This means that the software to create, manage, and perform storage tasks needs to run on a server’s CPU, along with I/O networking software stacks.
However, it should be evident that sometimes the obvious needs to be restarted, which is that software-defined anything requires hardware somewhere in the solution stack. Likewise, depending on how the software is implemented, it may require more hardware resources, including server compute, memory, I/O, and network and storage capabilities.
Keep in mind that networking stacks, including upper and lower-level protocols and interfaces, leverage software to implement their functionality. Therefore, the value proposition of using standard networks such as Ethernet and TCP is the ability to leverage lower-cost network interface cards (or chips), also known as NICs combined with server-based software stacks.
On the one hand, costs can be reduced by using less expensive NICs and using the generally available server CPU compute capabilities to run the TCP and other networking stack software. On systems with a lower application or other software performance demands, this can work out ok. However, for workloads and systems using software-defined storage and other applications that compete for server resources (CPU, memory, I/O), this can result in performance bottlenecks and problems.
Many Server Storage I/O Networking Bottlenecks Are CPU Problems
There is a classic saying that the best I/O is the one that you do not have to do. Likewise, the second-best I/O is the one with the most negligible overhead (and cost) as well as best performance. Another saying is that many application, database, server, and storage I/O problems are actually due to CPU bottlenecks. Fast storage devices need fast applications on fast servers with fast networks. This means finding and removing blockages, including offloading server CPU from performing network I/O processing using TOEs.
Wait a minute, isn’t the value proposition of using software-defined storage or networking to use low-cost general-purpose servers instead of more expensive hardware devices? With some caveats, Yup understands how much server CPU us being used to run the software-defined storage and software stacks and handle upper-level functionality. To support higher performance or larger workloads can be putting in more extensive (scale-up) and more (scale-out) servers and their increased connectivity and management overhead.
This is where the TOEs come into play by leveraging the best of both worlds to run software-defined storage (and networking) stacks, and other software and applications on general-purpose compute servers. The benefit is the TCP network I/O processing gets offloaded from the server CPU to the TOE, thereby freeing up the server CPU to do more work or enabling a smaller, lower-cost CPU to be used.
After all, many servers, storage, and I/O networking problems are often server CPU problems. An example of this is running the TCP networking software stack using CPU cycles on a host server that competes with the other software and applications. In addition, as an application does more I/O, for example, issuing reads and write requests to network and fabric-based storage, the server’s CPUs are also becoming busier with more overhead of running the lower-layer TCP and networking stack.
The result is server resources (CPU, memory) are running at higher utilization; however, there is more overhead. Higher resource utilization with low or no overhead, low latency, and high productivity are good things resulting in lower cost per work done. On the other hand, high CPU utilization, server operating system or kernel mode overhead, poor latency, and low productivity are not good things resulting in host per work done.
This means there is a loss of productivity as more time is spent waiting, and the cost to do a unit of work, for example, an I/O or transaction, increases (there is more overhead). Thus, offload engines (chips, cards, adapters) come into play to shift some software processing from the server CPU to a specialized processor. The result is lower server CPU overhead leaving more server resources for the main application or software-defined storage (and networking) while boosting performance and lowering overall costs.
Graphics, Compute, Network, TCP Offload Engines
Offload engines are not new, they have been around for a while, and in some cases, more common than some realize going by different names. For example, graphical Processing Units (GPUs) are used for offloading graphic and compute-intensive tasks to special chips and adapter cards. Other examples of offload processors include networks such as TCP Offload Engine (TOE), compression, and storage processing, among others.
The basic premise of offload engines is to move or shift processing of specific functions from having their software running on a general-purpose server CPU to a specialized processor (ASIC, FPGA, adapter, or mezzanine card). By moving the processing of functions to the offload or unique processing device, performance can be boosted while freeing up a server’s primary processor (CPU) to do other useful (and productive) work.
There is a cost associated with leveraging offloads and specialized processors; however, the business benefit should be offset by reducing primary server compute expenses or doing more work with available resources and driving network bandwidth line rates performance. The above should result in a net TCO reduction and boost your ROI for a given system or bill of material, including hardware, software, networking, and management.
Fast Storage Needs Fast Servers and I/O Networks
Ethernet network TOEs became popular in the industry back in the early 2000s, focusing on networked storage and storage networks that relied on TCP (e.g., iSCSI).
Fast forward to today, and there is continued use of networked (ok, fabric) storage over various interfaces, including Ethernet supporting different protocols. One of those protocols is NVMe in NVMe over Fabrics (NVMeoF) using TCP and underlying Ethernet-based networks for accessing fast Solid State Devices (SSDs).
Chelsio Communications T6 TOE for NVMeoF
An example of server storage I/O network TOEs, including those to support NVMeoF, are those from Chelsio Communications, such as the T6 25/100Gb devices. Chelsio announced today server storage I/O benchmark proof points for TCP based NVMe over Fabric (NVMeoF) TOE accelerated performance. StorageIO had the opportunity to look at the performance-boosting ability and CPU savings benefit of the Chelsio T6 prior to todays announcement.
After reviewing and validating the Chelsio proof points, test methodology, and results, it is clear that the T6 TOE enabled solution boosts server storage I/O performance while reducing host server CPU usage. The Chelsio T6 solution combined with Storage Performance Development Kit (SPDK) software, provides local-like performance of network fabric distributed NVMe (using TCP based NVMeoF) attached SSD storage while reducing host server CPU consumption.
“Boosting application performance, efficiency, and effectiveness of server CPUs are key priorities for legacy and software defined datacenter environments,” said Greg Schulz, Sr. Analyst Server Storage. “The Chelsio NVMe over Fabrics 100GbE NVMe/TCP (TOE) demonstration provides solid proof of how high-performance NVMe SSDs can help datacenters boost performance and productivity, while getting the best return on investment of datacenter infrastructure assets, not to mention optimize cost-of-ownership at the same time. It’s like getting a three for one bonus value from your server CPUs, your network, and your application perform better, now that’s a trifecta!”
You can read more about the technical and business benefits of the Chelsio T6 TOE enabled solution along with associated proof points (benchmarks) in the PDF white paper found here and their Press Release here. Note that the best measure, benchmark, proof point, or test is your application and workload, so contact Chelsio to arrange an evaluation of the T6 using your workload, software, and platform.
Where to learn more
Learn more about TOE, server, compute, GPU, ASIC, FPGA, storage, I/O networking, TCP, data infrastructure and software defined and related topics, trends, techniques, tools via the following links:
Chelsio Communications T6 Performance Press Release (PDF)
Chelsio Communications T6 TOE White Paper (PDF)
NVMe Linux Driver and related info
Announcing Native NVMe in Windows Server 2025 (Microsoft Post)
Introducing the Windows NVMe-oF Initiator Preview in Windows Server Insiders Builds (Microsoft Post)
Its Time for NVMeoF to let iSCSI begin its slow retirement journey (blog post)
Application Data Value Characteristics Everything Is Not the Same
PACE your Infrastructure decision-making, it’s about application requirements
Data Infrastructure Server Storage I/O Tradecraft Trends
Data Infrastructure Overview, Its What’s Inside of Data Centers
Data Infrastructure Management (Insight and Strategies)
Hyper-V and Windows Server 2025 Enhancements
Additional learning experiences along with common questions (and answers), as well as tips can be found in Software Defined Data Infrastructure Essentials book.

What this all means
The large superscalar web services and other large environments leverage offload engines and specialized processing technologies (chips, ASICs, FPGAs, GPUs, adapters) to boost performance while reducing server compute costs or getting more value out of a given server platform. If it works for the large superscalars, it can also work for your environment or your software-defined platform.
The benefits are reducing the number and cost of your software-defined platform bill of materials (BoM). Another benefit is to free up server CPU cycles to run your storage or network or other software to get more performance and work done. Yet another benefit is the ability to further stretch your software license investments, getting more work done per software license unit.
Have a look at the Chelsio Communications T6 line of TOE for NVMeoF and other workloads to boost performance, reduce CPU usage and lower costs. See for yourself The TOE NVMeoF TCP Performance Line Boost Performance Reduce Costs benefit.
Ok, nuff said, for now.
Cheers GS
Greg Schulz – Microsoft MVP Cloud and Data Center Management, previous 10 time VMware vExpert. Author of Software Defined Data Infrastructure Essentials (CRC Press), Data Infrastructure Management (CRC Press), as well as Cloud and Virtual Data Storage Networking (CRC Press), The Green and Virtual Data Center (CRC Press), Resilient Storage Networks (Elsevier) and twitter @storageio. Courteous comments are welcome for consideration. First published on https://storageioblog.com any reproduction in whole, in part, with changes to content, without source attribution under title or without permission is forbidden.
All Comments, (C) and (TM) belong to their owners/posters, Other content (C) Copyright 2006-2026 Server StorageIO and UnlimitedIO. All Rights Reserved. StorageIO is a registered Trade Mark (TM) of Server StorageIO.