
Application Data Access Life cycle Patterns Everything Is Not The Same(Part V)

Application Data Access Life cycle Patterns Everything Is Not The Same
This is part five of a five-part mini-series looking at Application Data Value Characteristics everything is not the same as a companion excerpt from chapter 2 of my new book Software Defined Data Infrastructure Essentials – Cloud, Converged and Virtual Fundamental Server Storage I/O Tradecraft (CRC Press 2017). available at Amazon.com and other global venues. In this post, we look at various application and data lifecycle patterns as well as wrap up this series.

Active (Hot), Static (Warm and WORM), or Dormant (Cold) Data and Lifecycles
When it comes to Application Data Value, a common question I hear is why not keep all data?
If the data has value, and you have a large enough budget, why not? On the other hand, most organizations have a budget and other constraints that determine how much and what data to retain.
Another common question I get asked (or told) it isn’t the objective to keep less data to cut costs?
If the data has no value, then get rid of it. On the other hand, if data has value or unknown value, then find ways to remove the cost of keeping more data for longer periods of time so its value can be realized.
In general, the data life cycle (called by some cradle to grave, birth or creation to disposition) is created, save and store, perhaps update and read with changing access patterns over time, along with value. During that time, the data (which includes applications and their settings) will be protected with copies or some other technique, and eventually disposed of.
Between the time when data is created and when it is disposed of, there are many variations of what gets done and needs to be done. Considering static data for a moment, some applications and their data, or data and their applications, create data which is for a short period, then goes dormant, then is active again briefly before going cold (see the left side of the following figure). This is a classic application, data, and information life-cycle model (ILM), and tiering or data movement and migration that still applies for some scenarios.
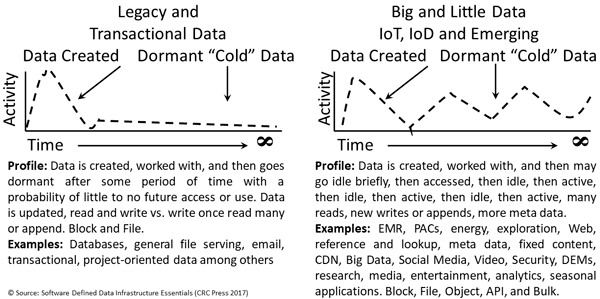
Changing data access patterns for different applications
However, a newer scenario over the past several years that continues to increase is shown on the right side of the above figure. In this scenario, data is initially active for updates, then goes cold or WORM (Write Once/Read Many); however, it warms back up as a static reference, on the web, as big data, and for other uses where it is used to create new data and information.
Data, in addition to its other attributes already mentioned, can be active (hot), residing in a memory cache, buffers inside a server, or on a fast storage appliance or caching appliance. Hot data means that it is actively being used for reads or writes (this is what the term Heat map pertains to in the context of the server, storage data, and applications. The heat map shows where the hot or active data is along with its other characteristics.
Context is important here, as there are also IT facilities heat maps, which refer to physical facilities including what servers are consuming power and generating heat. Note that some current and emerging data center infrastructure management (DCIM) tools can correlate the physical facilities power, cooling, and heat to actual work being done from an applications perspective. This correlated or converged management view enables more granular analysis and effective decision-making on how to best utilize data infrastructure resources.
In addition to being hot or active, data can be warm (not as heavily accessed) or cold (rarely if ever accessed), as well as online, near-line, or off-line. As their names imply, warm data may occasionally be used, either updated and written, or static and just being read. Some data also gets protected as WORM data using hardware or software technologies. WORM (immutable) data, not to be confused with warm data, is fixed or immutable (cannot be changed).
When looking at data (or storage), it is important to see when the data was created as well as when it was modified. However, you should avoid the mistake of looking only at when it was created or modified: Instead, also look to see when it was the last read, as well as how often it is read. You might find that some data has not been updated for several years, but it is still accessed several times an hour or minute. Also, keep in mind that the metadata about the actual data may be being updated, even while the data itself is static.
Also, look at your applications characteristics as well as how data gets used, to see if it is conducive to caching or automated tiering based on activity, events, or time. For example, there is a large amount of data for an energy or oil exploration project that normally sits on slower lower-cost storage, but that now and then some analysis needs to run on.
Using data and storage management tools, given notice or based on activity, which large or big data could be promoted to faster storage, or applications migrated to be closer to the data to speed up processing. Another example is weekly, monthly, quarterly, or year-end processing of financial, accounting, payroll, inventory, or enterprise resource planning (ERP) schedules. Knowing how and when the applications use the data, which is also understanding the data, automated tools, and policies, can be used to tier or cache data to speed up processing and thereby boost productivity.
All applications have performance, availability, capacity, economic (PACE) attributes, however:
- PACE attributes vary by Application Data Value and usage
- Some applications and their data are more active than others
- PACE characteristics may vary within different parts of an application
- PACE application and data characteristics along with value change over time
Read more about Application Data Value, PACE and application characteristics in Software Defined Data Infrastructure Essentials (CRC Press 2017).
Where to learn more
Learn more about Application Data Value, application characteristics, PACE along with data protection, software defined data center (SDDC), software defined data infrastructures (SDDI) and related topics via the following links:
- Part 1 – Application Data Value Characteristics Everything Is Not The Same
- Part 2 – 4 3 2 1 Data Protection Application Data Availability
- Part 3 – Application Data Characteristics Types Everything Is Not The Same
- Part 4 – Application Data Volume Velocity Variety Everything Is Not The Same
- Part 5 – Application Data Access Lifecycle Patterns Everything Not The Same
- Data Infrastructure server storage I/O network Recommended Reading
- World Backup Day 2018 Data Protection Readiness Reminder
- Data Infrastructure Server Storage I/O related Tradecraft Overview
- Data Infrastructure Overview, Its What’s Inside of Data Centers
- 4 3 2 1 and 3 2 1 data protection best practices
- Garbage data in, garbage information out, big data or big garbage?
- GDPR (General Data Protection Regulation) Resources Are You Ready?
- Which Enterprise HDD to use for a Content Server Platform
- The SSD Place (SSD, NVM, PM, SCM, Flash, NVMe, 3D XPoint, MRAM and related topics)
- The NVMe Place (NVMe related topics, trends, tools, technologies, tip resources)
- Data Protection Diaries (Archive, Backup/Restore, BC, BR, DR, HA,Replication, Security)

Additional learning experiences along with common questions (and answers), as well as tips can be found in Software Defined Data Infrastructure Essentials book.
What this all means and wrap-up
Keep in mind that Application Data Value everything is not the same across various organizations, data centers, data infrastructures, data and the applications that use them.
Also keep in mind that there is more data being created, the size of those data items, files, objects, entities, records are also increasing, as well as the speed at which they get created and accessed. The challenge is not just that there is more data, or data is bigger, or accessed faster, it’s all of those along with changing value as well as diverse applications to keep in perspective. With new Global Data Protection Regulations (GDPR) going into effect May 25, 2018, now is a good time to assess and gain insight into what data you have, its value, retention as well as disposition policies.
Remember, there are different data types, value, life-cycle, volume and velocity that change over time, and with Application Data Value Everything Is Not The Same, so why treat and manage everything the same?
Ok, nuff said, for now.
Gs
Greg Schulz – Microsoft MVP Cloud and Data Center Management, VMware vExpert 2010-2017 (vSAN and vCloud). Author of Software Defined Data Infrastructure Essentials (CRC Press), as well as Cloud and Virtual Data Storage Networking (CRC Press), The Green and Virtual Data Center (CRC Press), Resilient Storage Networks (Elsevier) and twitter @storageio. Courteous comments are welcome for consideration. First published on https://storageioblog.com any reproduction in whole, in part, with changes to content, without source attribution under title or without permission is forbidden.
All Comments, (C) and (TM) belong to their owners/posters, Other content (C) Copyright 2006-2026 Server StorageIO and UnlimitedIO. All Rights Reserved. StorageIO is a registered Trade Mark (TM) of Server StorageIO.




{kind=link}