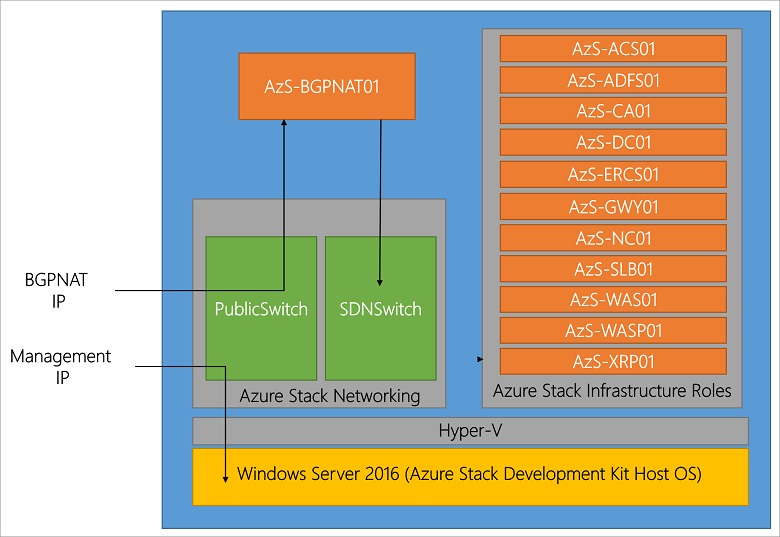
Part II Revisiting AWS S3 Storage Gateway (Test Drive Deployment)
This Amazon Web Service (AWS) Storage Gateway Revisited posts is a follow-up to the AWS Storage Gateway test drive and review I did a few years ago (thus why it’s called revisited). As part of a two-part series, the first post looks at what AWS Storage Gateway is, how it has improved since my last review of AWS Storage Gateway along with deployment options. The second post in the series looks at a sample test drive deployment and use.
What About Storage Gateway Costs?
Costs vary by region, type of storage being used (files stored in S3, Volume Storage, EBS Snapshots, Virtual Tape storage, Virtual Tape storage archive), as well as type of gateway host, along with how access and used. Request pricing varies including data written to AWS storage by gateway (up to maximum of $125.00 per month), snapshot/volume delete, virtual tape delete, (prorate fee for deletes within 90 days of being archived), virtual tape archival, virtual tape retrieval. Note that there are also various data transfer fees that also vary by region and gateway host. Learn more about pricing here.
What Are Some Storage Gateway Alternatives
AWS and S3 storage gateway access alternatives include those from various third-party (including that are in the AWS marketplace), as well as via data protection tools (e.g. backup/restore, archive, snapshot, replication) and more commonly storage systems. Some tools include Cloudberry, S3FS, S3 motion, S3 Browser among many others.
Tip is when a vendor says they support S3, ask them if that is for their back-end (e.g. they can access and store data in S3), or front-end (e.g. they can be accessed by applications that speak S3 API). Also explore what format the application, tool or storage system stores data in AWS storage, for example, are files mapped one to one to S3 objects along with corresponding directory hierarchy, or are they stored in a save set or other entity.
AWS Storage Gateway Deployment and Management Tips
Once you have created your AWS account (if you did not already have one) and logging into the AWS console (note the link defaults to US East 1 Region), go to the AWS Services Dashboard and select Storage Gateway (or click here which goes to US East 1). You will be presented with three options (File, Volume or VTL) modes.
What Does Storage Gateway and Install Look Like
The following is what installing a AWS Storage Gateway for file and then volume looks like. First, access the AWS Storage Gateway main landing page (it might change by time you read this) to get started. Scroll down and click on the Get Started with AWS Storage Gateway button or click here.

Select type of gateway to create, in the following example File is chosen.

Next select the type of file gateway host (EC2 cloud hosted, or on-premises VMware). If you choose VMware, an OVA will be downloaded (follow the onscreen instructions) that you deploy on your ESXi system or with vCenter. Note that there is a different VMware VM gateway OAV for File Gateway and another for Volume Gateway. In the following example VMware ESXi OVA is selected and downloaded, then accessed via VMware tools such as vSphere Web Client for deployment.

Once your VMware OVA file is downloaded from AWS, install using your preferred VMware tool, in this case I used the vSphere Web Client.

Once you have deployed the VMware VM for File Storage Gateway, it is time to connect to the gateway using the IP address assigned (static or DHCP) for the VM. Note that you may need to allocate some extra VMware storage to the VM if prompted (this mainly applies to Volume Gateway). Also follow directions about setting NTP time, using paravirtual adapters, thick vs. thin provisioning along with IP settings. Also double-check to make sure your VM and host are set for high-performance power setting. Note that the default username is sguser and password is sgpassword for the gateway.
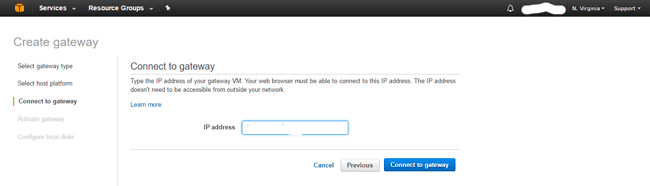
Once you successfully connect to the gateway, next step will be to configure file share settings.

Configure file share by selecting which gateway to use (in case you have more than one), name of an S3 bucket name to create, type of storage (S3 Standard or IA), along with Access Management security controls.

Next step is to complete file share creation, not the commands provided for Linux and Windows for accessing the file share.

Review file share settings

Now lets use the file share by accessing and mounting to a Windows system, then copy some files to the file share.
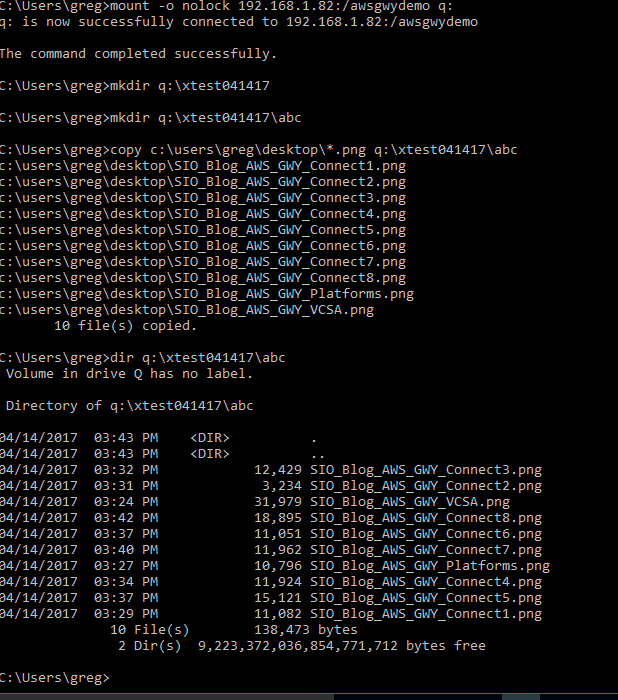
Now let’s go to the AWS console (or in our example use S3 Browser or your favorite tool) and look at the S3 bucket for the file share and see what is there. Note that each file is an object, and the objects simply appear as a file. If there were sub-directory those would also exist. Note that there are other buckets that I have masked out as we are only interested in the one named awsgwydemo that is configured using S3 Standard storage.

Now lets look at using the S3 Storage Gateway for Volumes. Similar to deploying for File Gateway, start out at the AWS Storage Gateway page and select Volume Gateway, then select what type of host (EC2 cloud, VMware or Hyper-V (2008 R2 or 2012) for on-premises deployment). Lets use the VMware Gateway, however as mentioned above, this is a different OVA/OVF than the File Gateway.

Download the VMware OVA/OVF from AWS, and then install using your preferred VMware tools making sure to configure the gateway per instructions. Note that the Volume Gateway needs a couple of storage devices allocated to it. This means you will need to make sure that a SCSI adapter exists (or add one) to the VM, along with the disks (HDD or SSD) for local storage. Refer to AWS documentation about how to size, for my deployment I added a couple of small 80GB drives (you can choose to put on HDD or SSD including NVMe). Note that when connecting to the gateway if you get an error similar to below, make sure that you are in fact using the Volume Gateway and not mistakenly using the File Gateway OVA (VM). Note that the default username is sguser and password is sgpassword for the gateway.

Now connect to the local Volume Storage Gateway and notice the two local disks allocated to it.

Next its time to create the Gateway which are deploying a Volume Cached below.

Next up is creating a volume, along with its security and access information.

Volume configuration continued.

And now some additional configuration of the volume including iSCSI CHAP security.
Which leads us up to some Windows related volume access and configuration.

Now lets use the new iSCSI based AWS Storage Gateway Volume. On the left you can see various WIndows command line activity, along with corresponding configuration information on the right.
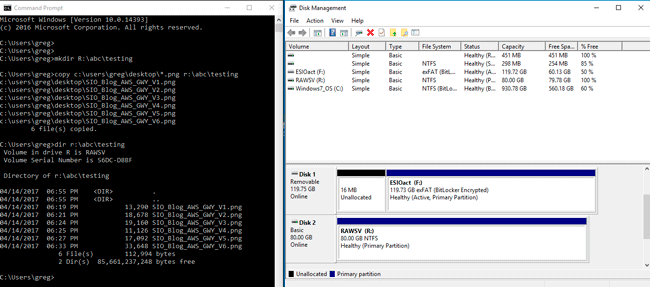
And there you have it, a quick tour of AWS Storage Gateway, granted there are more options that you can try yourself.
![]()
Where To Learn More
- AWS S3 Storage Gateway Revisited (Part I)
- Part II Revisiting AWS S3 Storage Gateway (Test Drive Deployment)
- AWS Storage Gateway site
- AWS Storage Gateway resource limits and specifications and Pricing
- AWS Storage Gateway Concepts, Getting Started, Managing Volumes, Troubleshooting and Local Console
- Cross-Region Replication for Amazon S3
- AWS (Amazon) storage gateway, first, second and third impressions
- Cloud conversations: If focused on cost you might miss other cloud storage benefits
- Data Protection Diaries
- Cloud Conversations: AWS overview and primer
- Eight Ways to Avoid Cloud Storage Pricing Surprises
- Cloud and Object Storage Center
- Are more than five nines of availability really possible?
- How do primary storage clouds and cloud for backup differ?
- What’s most important to know about my cloud privacy policy?
- Cloud Conversations: AWS S3 Cross Region Replication storage enhancements
- S3motion Buckets Containers Objects AWS S3 Cloud and EMCcode
- AWS EFS Elastic File System (Cloud NAS) First Preview Look
What This All Means
Overall I like the improvements that AWS has made to the Storage Gateway along with the different options it provides. Something to keep in mind is that if you are planning to use the AWS Storage Gateway File serving sharing mode that there are caveats to multiple concurrent writers to the same bucket. I would not be surprised if some other gateway or software based tool vendors tried to throw some fud towards the Storage Gateway, however ask them then how they coordinate multiple concurrent updates to a bucket while preserving data integrity.
Which Storage Gateway variant from AWS to use (e.g. File, Volume, VTL) depends on what your needs are, same with where the gateway is placed (Cloud hosted or on-premises with VMware or Hyper-V). Keep an eye on your costs, and more than just the storage space capacity. This means pay attention to your access and requests fees, as well as different service levels, along with data transfer fees.
You might wonder what about EFS and why you would want to use AWS Storage Gateway? Good question, at the time of this post EFS has evolved from being internal (e.g. within AWS and across regions) to having an external facing end-point however there is a catch. That catch which might have changed by time you read this is that the end-point can only be accessed from AWS Direct Connect locations.
This means that if your servers are not in a AWS Direct Connect location, without some creative configuration, EFS is not an option. Thus Storage Gateway File mode might be an option in place of EFS as well as using AWS storage access tools from others. For example I have some of my S3 buckets mounted on Linux systems using S3FS for doing rsync or other operations from local to cloud. In addition to S3FS, I also have various backup tools that place data into S3 buckets for backup, BC and DR as well as archiving.
Check out AWS Storage Gateway yourself and see what it can do or if it is a fit for your environment.
Ok, nuff said (for now…).
Cheers
Gs
Greg Schulz – Multi-year Microsoft MVP Cloud and Data Center Management, VMware vExpert (and vSAN). Author Cloud and Virtual Data Storage Networking (CRC Press), The Green and Virtual Data Center (CRC Press), Resilient Storage Networks (Elsevier) and twitter @storageio. Watch for the spring 2017 release of his new book "Software-Defined Data Infrastructure Essentials" (CRC Press).
Courteous comments are welcome for consideration. First published on https://storageioblog.com any reproduction in whole, in part, with changes to content, without source attribution under title or without permission is forbidden.
All Comments, (C) and (TM) belong to their owners/posters, Other content (C) Copyright 2006-2023 Server StorageIO(R) and UnlimitedIO. All Rights Reserved.