
World Backup Day 2018 Data Protection Readiness Reminder

It’s that time of year again, World Backup Day 2018 Data Protection Readiness Reminder.
In case you have forgotten, or were not aware, this coming Saturday March 31 is World Backup (and recovery day). The annual day is a to remember to make sure you are protecting your applications, data, information, configuration settings as well as data infrastructures. While the emphasis is on Backup, that also means recovery as well as testing to make sure everything is working properly.

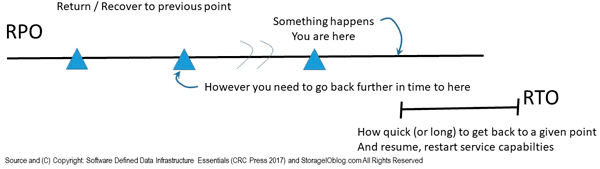
Its time that the focus of world backup day should expand from just a focus on backup to also broader data protection and things that start with R. Some data protection (and backup) related things, tools, tradecraft techniques, technologies and trends that start with R include readiness, recovery, reconstruct, restore, restart, resume, replication, rollback, roll forward, RAID and erasure codes, resiliency, recovery time objective (RTO), recovery point objective (RPO), replication among others.
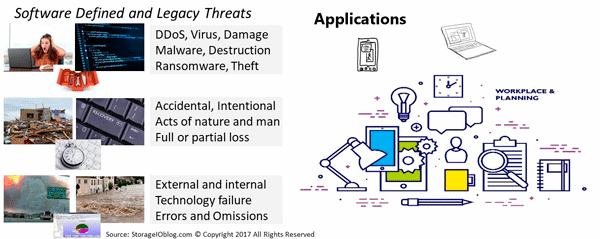
Keep in mind that Data Protection is a broader focus than just backup and recovery. Data protection includes disaster recovery DR, business continuance BC, business resiliency BR, security (logical and physical), standard and high availability HA, as well as durability, archiving, data footprint reduction, copy data management CDM along with various technologies, tradecraft techniques, tools.
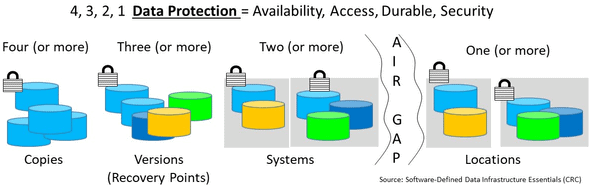
Quick Data Protection, Backup and Recovery Checklist
- Keep the 4 3 2 1 or shorter older 3 2 1 data protection rules in mind
- Do you know what data, applications, configuration settings, meta data, keys, certificates are being protected?
- Do you know how many versions, copies, where stored and what is on or off-site, on or off-line?
- Implement data protection at different intervals and coverage of various layers (application, transaction, database, file system, operating system, hypervisors, device or volume among others)
- Have you protected your data protection environment including software, configuration, catalogs, indexes, databases along with management tools?
- Verify that data protection point in time copies (backups, snapshots, consistency points, checkpoints, version, replicas) are working as intended
- Make sure that not only are the point in time protection copies running when scheduled, also that they are protected what’s intended
- Test to see if the protection copies can actually be used, this means restoring as well as accessing the data via applications
- Watch out to prevent a disaster in the course of testing, plan, prepare, practice, learn, refine, improve
- In addition to verifying your data protection (backup, bc, dr) for work, also take time to see how your home or personal data is protected
- View additional tips, techniques, checklist items in this Data Protection fundamentals series of posts here.



Where To Learn More
View additional Data Infrastructure Data Protection and related tools, trends, technology and tradecraft skills topics via the following links.
- Data Protection Diaries series
- Part 1 – Data Infrastructure Data Protection Fundamentals
- Part 2 – Reliability, Availability, Serviceability ( RAS) Data Protection Fundamentals
- Part 3 – Data Protection Fundamental Access Availability RAID Erasure Codes ( EC) including LRC
- Part 4 – Data Protection Recovery Points (Archive, Backup, Snapshots, Versions)
- Part 5 – Point In Time Data Protection Granularity Points of Interest
- Part 6 – Data Protection Security Logical Physical Software Defined
- Part 7 – Data Protection Tools, Technologies, Toolbox, Buzzword Bingo Trends
- Part 8 – Data Protection Diaries Walking Data Protection Talk
- Part 9 – who’s Doing What ( Toolbox Technology Tools)
- Part 10 – Data Protection Resources Where to Learn More
- Revisiting RAID storage remains relevant and resources
- Time to restore from backup: Do you know where your data is?
- February 2017 Server StorageIO Update Newsletter
- AWS Announces New S3 Cloud Storage Security Encryption Features
- Data Infrastructure Server Storage I/O Tradecraft Trends
- Data Infrastructure Server Storage I/O related Tradecraft Overview
- What’s a data infrastructure?
- Data Infrastructure Overview, Its Whats Inside of Data Centers
- Ensure your data infrastructure remains available and resilient
- GDPR (General Data Protection Regulation) Resources Are You Ready?
- GDPR goes into effect May 25 2018 Are You Ready?
- Until the focus expands to data protection – Taking action
- Backup, Big data, Big Data Protection, CMG & More with Tom Becchetti Podcast
- Six plus data center software defined management dashboards
- Cloud Storage Concerns, Considerations and Trends
- Zombie Technology Life after Death Tape Is Still Alive
- Data Infrastructure server storage I/O network Recommended Reading List Book Shelf
- Software Defined Data Infrastructure Essentials (CRC 2017) Book
- All You Need To Know about Remote Office/Branch Office Data Protection Backup (free webinar with registration)
- Software Defined, Converged Infrastructure (CI), Hyper-Converged Infrastructure (HCI) resources
- The SSD Place (SSD, NVM, PM, SCM, Flash, NVMe, 3D XPoint, MRAM and related topics)
- The NVMe Place (NVMe related topics, trends, tools, technologies, tip resources)
- Various Data Infrastructure related events, webinars and other activities
- www.objectstoragecenter.com and Software Defined, Cloud, Bulk and Object Storage Fundamentals
Additional learning experiences along with common questions (and answers), as well as tips can be found in Software Defined Data Infrastructure Essentials book.

What This All Means
You can not go forward if you can not go back to a particular point in time (e.g. recovery point objective or RPO). Likewise, if you can not go back to a given RPO, how can you go forward with your business as well as meet your recovery time objective (RTO)?

Backup is as important as restore, without a good backup or data protection point in time copy, how can you restore? Some will say backup is more important than recovery, however its the enablement that matters, in other words being able to provide data protection and recover, restart, resume or other things that start with R. World backup day should be a reminder to think about broader data protection which also means recovery, restore and realizing if your copies and versions are good. Keep the above in mind and this is your World Backup Day 2018 Data Protection Readiness Reminder.
Ok, nuff said, for now.
Gs
Greg Schulz – Microsoft MVP Cloud and Data Center Management, VMware vExpert 2010-2017 (vSAN and vCloud). Author of Software Defined Data Infrastructure Essentials (CRC Press), as well as Cloud and Virtual Data Storage Networking (CRC Press), The Green and Virtual Data Center (CRC Press), Resilient Storage Networks (Elsevier) and twitter @storageio. Courteous comments are welcome for consideration. First published on https://storageioblog.com any reproduction in whole, in part, with changes to content, without source attribution under title or without permission is forbidden.
All Comments, (C) and (TM) belong to their owners/posters, Other content (C) Copyright 2006-2026 Server StorageIO and UnlimitedIO. All Rights Reserved. StorageIO is a registered Trade Mark (TM) of Server StorageIO.








{kind=link}