
Data Protection Diaries Fundamental Point In Time Granularity
Companion to Software Defined Data Infrastructure Essentials – Cloud, Converged, Virtual Fundamental Server Storage I/O Tradecraft ( CRC Press 2017)

By Greg Schulz – www.storageioblog.com November 26, 2017
This is Part 5 of a multi-part series on Data Protection fundamental tools topics techniques terms technologies trends tradecraft tips as a follow-up to my Data Protection Diaries series, as well as a companion to my new book Software Defined Data Infrastructure Essentials – Cloud, Converged, Virtual Server Storage I/O Fundamental tradecraft (CRC Press 2017).

Click here to view the previous post Part 4 Data Protection Recovery Points (Archive, Backup, Snapshots, Versions), and click here to view the next post Part 6 Data Protection Security Logical Physical Software Defined.
Post in the series includes excerpts from Software Defined Data Infrastructure (SDDI) pertaining to data protection for legacy along with software defined data centers ( SDDC), data infrastructures in general along with related topics. In addition to excerpts, the posts also contain links to articles, tips, posts, videos, webinars, events and other companion material. Note that figure numbers in this series are those from the SDDI book and not in the order that they appear in the posts.
In this post the focus is around Data Protection points of granularity, addressing different layers and stack altitude (higher application and lower system level) Chapter 10 . among others.
Point-in-Time Protection Granularity Points of Interest

Figure 10.1 Recovery and consistency points
Figure 10.1 above is a refresh from previous posts about the role and importance of having various recovery points at different time intervals to enable data protection (and restoration). Building upon figure 10.1, figure 10.5 looks at different granularity of where and how data should be protected. Keep in mind that everything is not the same, so why treat everything the same with the same type of protection?
Figure 10.5 shows backup and Data Protection focus, granularity, and coverage. For example, at the top left is less frequent protection of the operating system, hypervisors, and BIOS, UEFI settings. At the middle left is volume, or device level protection (full, incremental, differential), along with various views on the right ranging from protecting everything, to different granularity such as file system, database, database logs and journals, and operating system (OS) and application software, along with settings.
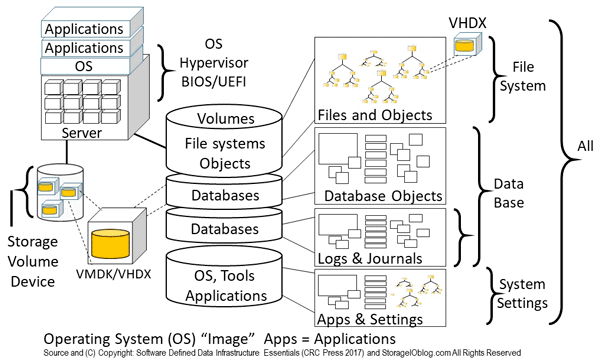
Figure 10.5 Backup and data protection focus, granularity, and coverage
In Figure 10.5, note that the different recovery point focus and granularity also take into consideration application and data consistency (as well as checkpoints), along with different frequencies and coverage (e.g. full, partial, incremental, incremental forever, differential) as well as retention.
Tip – Some context is needed about object backup and backing up objects, which can mean different things. As mentioned elsewhere, objects refer to many different things, including cloud and object storage buckets, containers, blobs, and objects accessed via S3 or Swift, among other APIs. There are also database objects and entities, which are different from cloud or object storage objects.
Another context factor is that an object backup can refer to protecting different systems, servers, storage devices, volumes, and entities that collectively comprise an application such as accounting, payroll, or engineering, vs. focusing on the individual components. An object backup may, in fact, be a collection of individual backups, PIT copies, and snapshots that combined represent what’s needed to restore an application or system.
On the other hand, the content of a cloud or object storage repository ( buckets, containers, blobs, objects, and metadata) can be backed up, as well as serve as a destination target for protection.
Backups can be cold and off-line like archives, as well as on-line and accessible. However, the difference between the two, besides intended use and scope, is granularity. Archives are intended to be coarser and less frequently accessed, while backups can be more frequently and granular accessed. Can you use a backup for an archive and vice versa? A qualified yes, as an archive could be a master gold copy such as an annual protection copy, in addition to functioning in its role as a compliance and retention copy. Likewise, a full backup set to long-term retention can provide and enable some archive functions.
Where To Learn More
Continue reading additional posts in this series of Data Infrastructure Data Protection fundamentals and companion to Software Defined Data Infrastructure Essentials (CRC Press 2017) book, as well as the following links covering technology, trends, tools, techniques, tradecraft and tips.
- Part 1 – Data Infrastructure Data Protection Fundamentals
- Part 2 – Reliability, Availability, Serviceability ( RAS) Data Protection Fundamentals
- Part 3 – Data Protection Access Availability RAID Erasure Codes ( EC) including LRC
- Part 4 – Data Protection Recovery Points (Archive, Backup, Snapshots, Versions)
- Part 5 – Point In Time Data Protection Granularity Points of Interest
- Part 6 – Data Protection Security Logical Physical Software Defined
- Part 7 – Data Protection Tools, Technologies, Toolbox, Buzzword Bingo Trends
- Part 8 – Data Protection Diaries Walking Data Protection Talk
- Part 9 – who’s Doing What ( Toolbox Technology Tools)
- Part 10 – Data Protection Resources Where to Learn More
- Data Protection Diaries series
- Data Infrastructure server storage I/O network Recommended Reading List Book Shelf
- Software Defined Data Infrastructure Essentials (CRC 2017) Book
Additional learning experiences along with common questions (and answers), as well as tips can be found in Software Defined Data Infrastructure Essentials book.
What This All Means
A common theme in this series as well as in my books, webinars, seminars and general approach to data infrastructures, data centers and IT in general is that everything is not the same, why treat it all the same? What this means is that there are differences across various environments, data centers, data infrastructures, applications, workloads and data. There are also different threat risks scenarios (e.g. threat vectors and attack surface if you like vendor industry talk) to protect against.
Rethinking and modernizing data protection means using new (and old) tools in new ways, stepping back and rethinking what to protect, when, where, why, how, with what. This also means protecting in different ways at various granularity, time intervals, as well as multiple layers or altitude (higher up the application stack, or lower level).
Get your copy of Software Defined Data Infrastructure Essentials here at Amazon.com, at CRC Press among other locations and learn more here. Meanwhile, continue reading with the next post in this series, Part 6 Data Protection Security Logical Physical Software Defined.
Ok, nuff said, for now.
Gs
Greg Schulz – Microsoft MVP Cloud and Data Center Management, VMware vExpert 2010-2017 (vSAN and vCloud). Author of Software Defined Data Infrastructure Essentials (CRC Press), as well as Cloud and Virtual Data Storage Networking (CRC Press), The Green and Virtual Data Center (CRC Press), Resilient Storage Networks (Elsevier) and twitter @storageio. Courteous comments are welcome for consideration. First published on https://storageioblog.com any reproduction in whole, in part, with changes to content, without source attribution under title or without permission is forbidden.
All Comments, (C) and (TM) belong to their owners/posters, Other content (C) Copyright 2006-2026 Server StorageIO and UnlimitedIO. All Rights Reserved. StorageIO is a registered Trade Mark (TM) of Server StorageIO.


















{kind=link}