How many i/o iops can flash ssd or hdd do with vmware?

Updated 2/10/2018
A common question I run across is how many I/O iopsS can flash SSD or HDD storage device or system do or give.
The answer is or should be it depends.
This is the first of a two-part series looking at storage performance, and in context specifically around drive or device (e.g. mediums) characteristics across HDD, HHDD and SSD that can be found in cloud, virtual, and legacy environments. In this first part the focus is around putting some context around drive or device performance with the second part looking at some workload characteristics (e.g. benchmarks).
What about cloud, tape summit resources, storage systems or appliance?
Lets leave those for a different discussion at another time.
Getting started
Part of my interest in tools, metrics that matter, measurements, analyst, forecasting ties back to having been a server, storage and IO performance and capacity planning analyst when I worked in IT. Another aspect ties back to also having been a sys admin as well as business applications developer when on the IT customer side of things. This was followed by switching over to the vendor world involved with among other things competitive positioning, customer design configuration, validation, simulation and benchmarking HDD and SSD based solutions (e.g. life before becoming an analyst and advisory consultant).
Btw, if you happen to be interested in learn more about server, storage and IO performance and capacity planning, check out my first book Resilient Storage Networks (Elsevier) that has a bit of information on it. There is also coverage of metrics and planning in my two other books The Green and Virtual Data Center (CRC Press) and Cloud and Virtual Data Storage Networking (CRC Press). I have some copies of Resilient Storage Networks available at a special reader or viewer rate (essentially shipping and handling). If interested drop me a note and can fill you in on the details.
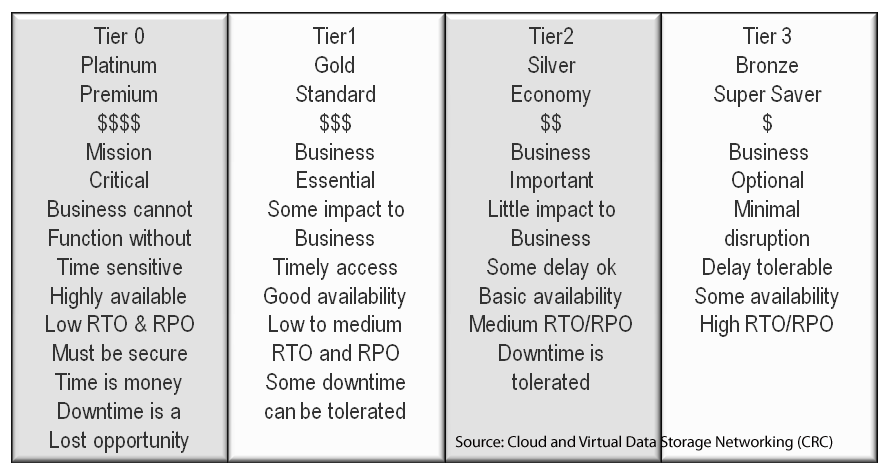
There are many rules of thumb (RUT) when it comes to metrics that matter such as IOPS, some that are older while others may be guess or measured in different ways. However the answer is that it depends on many things ranging from if a standalone hard disk drive (HDD), Hybrid HDD (HHDD), Solid State Device (SSD) or if attached to a storage system, appliance, or RAID adapter card among others.
Taking a step back, the big picture

Various HDD, HHDD and SSD’s
Server, storage and I/O performance and benchmark fundamentals
Even if just looking at a HDD, there are many variables ranging from the rotational speed or Revolutions Per Minute (RPM), interface including 1.5Gb, 3.0Gb, 6Gb or 12Gb SAS or SATA or 4Gb Fibre Channel. If simply using a RUT or number based on RPM can cause issues particular with 2.5 vs. 3.5 or enterprise and desktop. For example, some current generation 10K 2.5 HDD can deliver the same or better performance than an older generation 3.5 15K. Other drive factors (see this link for HDD fundamentals) including physical size such as 3.5 inch or 2.5 inch small form factor (SFF), enterprise or desktop or consumer, amount of drive level cache (DRAM). Space capacity of a drive can also have an impact such as if all or just a portion of a large or small capacity devices is used. Not to mention what the drive is attached to ranging from in internal SAS or SATA drive bay, USB port, or a HBA or RAID adapter card or in a storage system.

HDD fundamentals
How about benchmark and performance for marketing or comparison tricks including delayed, deferred or asynchronous writes vs. synchronous or actually committed data to devices? Lets not forget about short stroking (only using a portion of a drive for better IOP’s) or even long stroking (to get better bandwidth leveraging spiral transfers) among others.
Almost forgot, there are also thick, standard, thin and ultra thin drives in 2.5 and 3.5 inch form factors. What’s the difference? The number of platters and read write heads. Look at the following image showing various thickness 2.5 inch drives that have various numbers of platters to increase space capacity in a given density. Want to take a wild guess as to which one has the most space capacity in a given footprint? Also want to guess which type I use for removable disk based archives along with for onsite disk based backup targets (compliments my offsite cloud backups)?

Thick, thin and ultra thin devices
Beyond physical and configuration items, then there are logical configuration including the type of workload, large or small IOPS, random, sequential, reads, writes or mixed (various random, sequential, read, write, large and small IO). Other considerations include file system or raw device, number of workers or concurrent IO threads, size of the target storage space area to decide impact of any locality of reference or buffering. Some other items include how long the test or workload simulation ran for, was the device new or worn in before use among other items.
Tools and the performance toolbox
Then there are the various tools for generating IO’s or workloads along with recording metrics such as reads, writes, response time and other information. Some examples (mix of free or for fee) include Bonnie, Iometer, Iorate, IOzone, Vdbench, TPC, SPC, Microsoft ESRP, SPEC and netmist, Swifttest, Vmark, DVDstore and PCmark 7 among many others. Some are focused just on the storage system and IO path while others are application specific thus exercising servers, storage and IO paths.

Server, storage and IO performance toolbox
Having used Iometer since the late 90s, it has its place and is popular given its ease of use. Iometer is also long in the tooth and has its limits including not much if any new development, never the less, I have it in the toolbox. I also have Futremark PCmark 7 (full version) which turns out has some interesting abilities to do more than exercise an entire Windows PC. For example PCmark can use a secondary drive for doing IO to.
PCmark can be handy for spinning up with VMware (or other tools) lots of virtual Windows systems pointing to a NAS or other shared storage device doing real world type activity. Something that could be handy for testing or stressing virtual desktop infrastructures (VDI) along with other storage systems, servers and solutions. I also have Vdbench among others tools in the toolbox including Iorate which was used to drive the workloads shown below.
What I look for in a tool are how extensible are the scripting capabilities to define various workloads along with capabilities of the test engine. A nice GUI is handy which makes Iometer popular and yes there are script capabilities with Iometer. That is also where Iometer is long in the tooth compared to some of the newer generation of tools that have more emphasis on extensibility vs. ease of use interfaces. This also assumes knowing what workloads to generate vs. simply kicking off some IOPs using default settings to see what happens.
Another handy tool is for recording what’s going on with a running system including IO’s, reads, writes, bandwidth or transfers, random and sequential among other things. This is where when needed I turn to something like HiMon from HyperIO, if you have not tried it, get in touch with Tom West over at HyperIO and tell him StorageIO sent you to get a demo or trial. HiMon is what I used for doing start, stop and boot among other testing being able to see IO’s at the Windows file system level (or below) including very early in the boot or shutdown phase.
Here is a link to some other things I did awhile back with HiMon to profile some Windows and VDI activity test profiling.
What’s the best tool or benchmark or workload generator?
The one that meets your needs, usually your applications or something as close as possible to it.

Various 2.5 and 3.5 inch HDD, HHDD, SSD with different performance
Where To Learn More
View additional NAS, NVMe, SSD, NVM, SCM, Data Infrastructure and HDD related topics via the following links.
- Can we get a side of context with them IOPS and other storage metrics?
- WHEN AND WHERE TO USE NAND FLASH SSD FOR VIRTUAL SERVERS
- Revisiting RAID storage remains relevant and resources
- NVMe overview and primer – Part I
- Part 1 of HDD for content servers series Trends and Content Application Servers
- Part 2 of HDD for content servers series Content application server decisions and testing plans
- Part 3 of HDD for content servers series Test hardware and software configuration
- Part 4 of HDD for content servers series Large file I/O processing
- Part 5 of HDD for content servers series Small file I/O processing
- Part 6 of HDD for content servers series General I/O processing
- Part 7 of HDD for content servers series How HDD continue to evolve over different generations and wrap up
- As the platters spin, HDD’s for cloud, virtual and traditional storage environments
- How many IOPS can a HDD, HHDD or SSD do?
- Hard Disk Drives (HDD) for Virtual Environments
- Server and Storage I/O performance and benchmarking tools
- Server storage I/O performance benchmark workload scripts Part I and Part II
- How to test your HDD, SSD or all flash array (AFA) storage fundamentals
- What is the best server storage I/O workload benchmark? It depends
- I/O, I/O how well do you know about good or bad server and storage I/Os?
- Big Files Lots of Little File Processing Benchmarking with Vdbench
- Part II – NVMe overview and primer (Different Configurations)
- Part III – NVMe overview and primer (Need for Performance Speed)
- Part IV – NVMe overview and primer (Where and How to use NVMe)
- Part V – NVMe overview and primer (Where to learn more, what this all means)
- PCIe Server I/O Fundamentals
- If NVMe is the answer, what are the questions?
- NVMe Wont Replace Flash By Itself
- Via Computerweekly – NVMe discussion: PCIe card vs U.2 and M.2
- Intel and Micron unveil new 3D XPoint Non Volatie Memory (NVM) for servers and storage
- Part II – Intel and Micron new 3D XPoint server and storage NVM
- Part III – 3D XPoint new server storage memory from Intel and Micron
- Server storage I/O benchmark tools, workload scripts and examples (Part I) and (Part II)
- Data Infrastructure Overview, Its Whats Inside of Data Centers
- All You Need To Know about Remote Office/Branch Office Data Protection Backup (free webinar with registration)
- Software Defined, Converged Infrastructure (CI), Hyper-Converged Infrastructure (HCI) resources
- The SSD Place (SSD, NVM, PM, SCM, Flash, NVMe, 3D XPoint, MRAM and related topics)
- The NVMe Place (NVMe related topics, trends, tools, technologies, tip resources)
- Data Protection Diaries (Archive, Backup/Restore, BC, BR, DR, HA, RAID/EC/LRC, Replication, Security)
- Software Defined Data Infrastructure Essentials (CRC Press 2017) including SDDC, Cloud, Container and more
- Various Data Infrastructure related events, webinars and other activities
- www.objectstoragecenter.com and Software Defined, Cloud, Bulk and Object Storage Fundamentals
- Server Storage I/O Network PCIe Fundamentals
Additional learning experiences along with common questions (and answers), as well as tips can be found in Software Defined Data Infrastructure Essentials book.

What This All Means
That depends, however continue reading part II of this series to see some results for various types of drives and workloads.
Ok, nuff said, for now.
Gs
Greg Schulz – Microsoft MVP Cloud and Data Center Management, VMware vExpert 2010-2017 (vSAN and vCloud). Author of Software Defined Data Infrastructure Essentials (CRC Press), as well as Cloud and Virtual Data Storage Networking (CRC Press), The Green and Virtual Data Center (CRC Press), Resilient Storage Networks (Elsevier) and twitter @storageio. Courteous comments are welcome for consideration. First published on https://storageioblog.com any reproduction in whole, in part, with changes to content, without source attribution under title or without permission is forbidden.
All Comments, (C) and (TM) belong to their owners/posters, Other content (C) Copyright 2006-2026 Server StorageIO and UnlimitedIO. All Rights Reserved. StorageIO is a registered Trade Mark (TM) of Server StorageIO.