With RTO context matters similar to many things in and around Information Technology (IT) among other industries. Various three (or more) letter acronyms (TLAs) have different meanings based on their context. An example of a TLA is RTO which has different meanings. For instance, RTO can mean:
Return To Office
Recovery Time Objective
Ready To Operate
Return To Operations
Among others…
From the data protection and cyber resilience context, RTO has traditionally been thought of as a Recovery Time Objective or the amount of time that something should be able to be restored, recovered, rebuilt, reset, or returned to service, aka being usable. Another way of looking at Recovery Time Objective is the goal or requirement that something is ready to operate, enabling an organization and its IT services apps, data, and information to return to operations.
Figure 1 Data Infrastructures and Recovery Time Objectives (RTO)
RTO Recovery Time Object Context
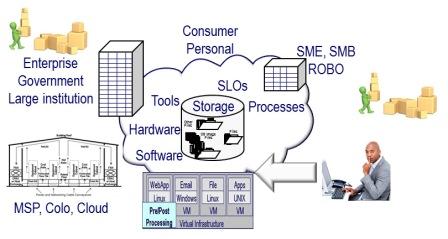
Where context is needed is not just simply what RTO is being discussed, e.g., recovery time objective; also, what is the scope of the recovery time objective? Is it all-inclusive for a specific component, layer, or focus point? A holistic RTO is when everything in the stack, vertical up and down all layers of hardware, software, services, and, if applicable, also horizontal across different systems, platforms, and locations, is usable. For example, when a user can access an app from various places, and everything is functioning, perhaps not at full or regular speed, it is functioning.
Figure 2 Various Threats and Data Infrastructure Layers
Recovery Time Objective Focus
On the other hand, component RTO refers to a specific focus area, point, or location in the stack (figure 2). For example, a lower-level server, network, storage device, physical or virtual machine, container, file system, database repository, or application is restored or returned to readiness and operation. The individual components may be restored to operating; however, what about the sum of all the parts that make up the holistic solution or service the user sees and expects to be in working condition?
Additional Resources Where to learn more
The following links are additional resources to learn more about Recovery Time Objectives (RTO) and related data infrastructures, tradecraft, and metrics that matter topics.
RTO context matters, not only for which RTO but also if it refers to a holistic compound aggregate scope or that of a component. While component RTOs are essential, so is the holistic focus of when things are usable.
All Comments, (C) and (TM) belong to their owners/posters, Other content (C) Copyright 2006-2026 Server StorageIO and UnlimitedIO. All Rights Reserved. StorageIO is a registered Trade Mark (TM) of UnlimitedIO LLC.
Cloud Conversations AWS Azure Service Maps via Microsoft
Updated 1/21/2018
Microsoft has created an Amazon Web Service AWSAzureService Map. The AWS Azure Service Map is a list created by Microsoft looks at corresponding services of both cloud providers.
Note that this is an evolving work in progress from Microsoft and use it as a tool to help position the different services from Azure and AWS.
Also note that not all features or services may not be available in different regions, visit Azure and AWS sites to see current availability.
As with any comparison they are often dated the day they are posted hence this is a work in progress. If you are looking for another Microsoft created why Azure vs. AWS then check out this here. If you are looking for an AWS vs. Azure, do a simple Google (or Bing) search and watch all the various items appear, some sponsored, some not so sponsored among others.
Whats In the Service Map
The following AWS and Azure services are mapped:
Marketplace (e.g. where you select service offerings)
On one hand this can and will likely be used as a comparison however use caution as both Azure and AWS services are rapidly evolving, adding new features, extending others. Likewise the service regions and site of data centers also continue to evolve thus use the above as a general guide or tool to help map what service offerings are similar between AWS and Azure.
By the way, if you have not heard, its Blogtober, check out some of the other blogs and posts occurring during October here.
All Comments, (C) and (TM) belong to their owners/posters, Other content (C) Copyright 2006-2026 Server StorageIO and UnlimitedIO. All Rights Reserved. StorageIO is a registered Trade Mark (TM) of Server StorageIO.
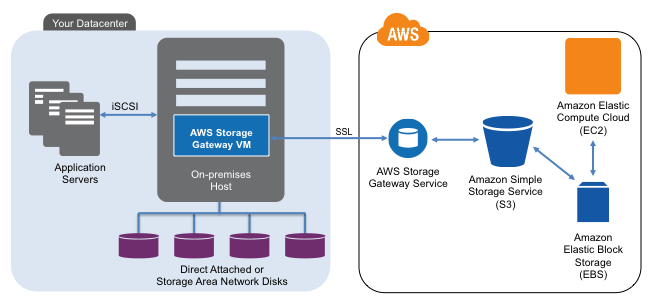
In 2012 AWS released their Storage Gateway that you can use and try for free here using either an EC2 Amazon Machine Instance (AMI), or deployed locally on a hypervisor such as VMware vSphere/ESXi. About a year ago I did a storage gateway post (First, second and third impressions) when it was first released. I will do a new post soon following up with my later impressions and experiences of having used it recently. For now, my quick (fourth impressions can be found here in this AWS Marketplace review). In general, the gateway is an AWS alternative to using third product gateway, appliances of software tools for accessing AWS storage.
When deployed locally on a VM, the storage gateway communicates using the AWS API’s back to the S3 and EBS (depending on how configured) storage services. Locally, the storage gateway presents an iSCSI block access method for Windows or other servers to use.
There are two modes with one being Gateway-Stored and the other Gateway-Cached. Gateway-Stored uses your primary storage mapped to the storage gateway as primary storage and asynchronous (time delayed) snapshots (user defined) to S3 via EBS volumes. This is a handy way to have local storage for low latency access, yet use AWS for HA, BC and DR, along with a means for doing migration into or out of AWS. Gateway-cache mode places primary storage in AWS S3 with a local cached copy to reduce network overhead.
When I tried the gateway a month or so ago, using both modes, I was not able to view any of my data using standard S3 tools. For example if I looked in my S3 buckets the objects do not appear, something that AWS said had to do with where and how those buckets and objects are managed. Otoh, I was able to see EBS snapshots for the gateway-stored mode including using that as a means of moving data between local and AWS EC2 instances. Note that regardless of the AWS storage gateway mode, some local cache storage is needed, and likewise some EBS volumes will be needed depending on what mode is used.
When I used the gateway, a Windows Server mounted the iSCSI volume presented by the storage gateway and in turn served that to other systems as a shared folder. Thus while having block such as iSCSI is nice, a NAS (NFS or CIFS) presentation and access mode would also be useful. However more on the storage gateway in a future post. Also note that beyond the free trial period (you may have to pay for storage being used) for using the gateway, there are also fees for S3 and EBS storage volumes use.
What about Glacier?
Shortly after its release last year, I did this piece about Glacier and have since been doing some testing proof of concepts with it.
I like Glacier and its prospects for doing some various things, particular for inactive data including deep archives that will seldom if every be accessed, yet need to be retained. The business value proposition of Glacier is that it has a very high durability and low-cost assuming that you do not need to frequently access your data, and when you do, that you can wait 3 to 5 hours before retrieving it from your S3 buckets.
Access to Glacier is via API or AWS console so getting things into and out of it can be a challenge. For example I wanted to see if I could use AWS storage gateway to more easily bulk move things into Glacier via S3, however no luck, or at least today. Speaking of S3, by setting your policies you determine when objects get moved into Glacier as well as how long they will stay there, you can read more about Glacier here and via AWS here.
Note that there is a myth that cloud vendors have hidden fees which may be the case for some, however so far I have not seen that to be the case with AWS. However, as a consumer, designer or architect, doing your homework and looking at the above links among others you can be ready and understand the various fees and options. Hence like procuring traditional hardware, software or services, do your due diligence and be an informed shopper.
Some more service cost notes include:
Note that with S3 Standard and RRS objects there is not a charge for deletion of objects, however there is a pro-rated charge per GByte of Glacier objects removed prior to 90 days. Glacier also allows up to 5% of your average monthly storage usage (pro-rated daily) to be restored with no charge, other fees apply for restoring larger amounts in a given period. Thus if you are planning on accessing and using data, analyze what your activity and usage will be as part of calculating your costs with Glacier. Read more about Glacier here.
Standard EBS volumes are changed by the amount of storage space capacity you provision in GB until released. For EBS snapshot copies there are fees for transferring data across regions, once moved, the rates of the new region apply for the snapshot.
As with Standard volumes, volume storage for Provisioned IOPS volumes is charged by the amount you provision in GB per month. With Provisioned IOPS volumes, you are also charged by the amount you provision in IOPS pro-rated as a percentage of days you have it in use for the month.
Thus important for cloud storage planning to know not only your space requirements, also IOP’s, bandwidth, and level of availability as well as durability. so for Standard volumes, you will likely see a lower number of I/O requests on your bill than is seen by your application unless you sync all of your I/Os to disk. Thus pay attention to what your needs are in terms of availability (accessibility), durability (resiliency or survivability), space capacity, and performance.
Leverage AWS CloudWatch tools and API’s to monitoring that matter for timely insight and situational awareness into how EBS, EC2, S3, Glacier, Storage Gateway and other services are being used (or costing you). Also visit the AWS service health status dashboard to gain insight into how things are running to help gain confidence with cloud services and solutions.
Hopefully this helps to fill in some gaps giving more information addressing questions, along with generating new ones to prepare for your journey with clouds. After all, don’t be scared of clouds. Be prepared, do your homework, identify your concerns and then address those to gain cloud confidence.
All Comments, (C) and (TM) belong to their owners/posters, Other content (C) Copyright 2006-2026 Server StorageIO and UnlimitedIO LLC All Rights Reserved
For those not familiar, Simple Storage Services (S3), Glacier and Elastic Block Storage (EBS) are part of the AWS cloud storage portfolio of services. With S3, you specify a region where a bucket is created that will contain objects that can be written, read, listed and deleted. You can create multiple buckets in a region with unlimited number of objects ranging from 1 byte to 5 Tbytes in size per bucket. Each object has a unique, user or developer assigned access key. In addition to indicating which AWS region, S3 buckets and objects are provisioned using different levels of availability, durability, SLA’s and costs (view S3 SLA’s here).
Cost will vary depending on the AWS region being used, along if Standard or Reduced Redundancy Storage (RSS) selected. Standard S3 storage is designed with 99.999999999% durability (how many copies exists) and 99.99% availability (how often can it be accessed) on an annual basis capable of two data centers becoming un-available.
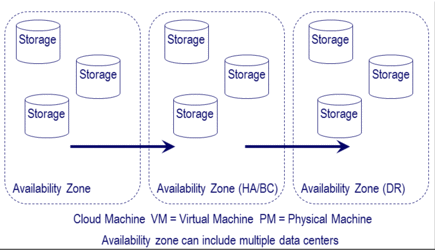
As its name implies, for a lower fee and level of durability, S3 RRS has an annual durability of 99.999% and availability of 99.99% capable of a single data center loss. In the following figure durability is how many copies of data exist spread across different servers and storage systems in various data centers and availability zones.
What would you put in RRS vs. Standard S3 storage?
Items that need some level of persistence that can be refreshed, recreated or restored from some other place or pool of storage such as thumbnails or static content or read caches. Other items would be those that you could tolerant some downtime while waiting for data to be restored, recovered or rebuilt from elsewhere in exchange for a lower cost.
Different AWS regions can be chosen for regulatory compliance requirements, performance, SLA’s, cost and redundancy with authentication mechanisms including encryption (SSL and HTTPS) to make sure data is kept secure. Various rights and access can be assigned to objects including making them public or private. In addition to logical data protection (security, identity and access management (IAM), encryption, access control) policies also apply to determine level of durability and availability or accessibility of buckets and objects. Other attributes of buckets and objects include life-cycle management polices and logging of activity to the items. Also part of the objects are meta data containing information about the data being stored shown in a generic example below.
Access to objects is via standard REST and SOAP interfaces with an Application Programming Interface (API). For example default access is via HTTP along with a Bit Torrent interface with optional support via various gateways, appliances and software tools.
Example cloud and object storage access
The above figure via Cloud and Virtual Data Storage Networking (CRC Press) shows a generic example applicable to AWS services including S3 being accessed in different ways. For example I access my S3 buckets and objects via Jungle Disk (one of the tools I use for data protection) that can also access my Rackspace Cloudfiles data. In the following figure there are examples of some of my S3 buckets and objects used by different applications and tools that I have in various AWS regions.
AWS S3 buckets and objects in different regions
Note that I sometimes use other AWS regions outside the US for testing purposes, for compliance purpose my production, business or personal data is only in the US regions.
The following figure is a generic example of how cloud and object storage are accessed using different tools, hardware, software and API’s along with gateways. AWS is an example of what is shown in the following figure as a Cloud Service and S3, EBS or Glacier as cloud storage. Common example API commands are also shown which will vary by different vendors, products or solution definitions or implementations. While Amazon S3 API which is REST HTTP based has become an industry de facto standard, there are other API’s including CDMI (Cloud Data Management Interface) developed by SNIA which has gained ISO accreditation.
In addition to using Jungle Disk which manages my AWS keys and objects that it creates, I can also access my S3 objects via the AWS management console and web tools, also via third-party tools including Cyberduck.
All Comments, (C) and (TM) belong to their owners/posters, Other content (C) Copyright 2006-2026 Server StorageIO and UnlimitedIO LLC All Rights Reserved
For those not familiar, Simple Storage Services (S3), Glacier and Elastic Block Storage (EBS) are part of the AWS cloud storage portfolio of services. There are several other storage and data related service for little data database (SQL and NoSql based) other offerings include compute, data management, application and networking for different needs shown in the following image.
S3 is well suited for both big and little data repositories of objects ranging from backup to archive to active video images and much more. In fact if you are using some of the different AaaS or SaaS services including backup or file and video sharing, those may be using S3 as its back-end storage repository. For example NetFlix leverages various AWS capabilities as part of its data and applications infrastructure (read more here).
AWS basics
AWS consists of multiple regions that contain multiple availability zones where data and applications are supported from.
Note that objects stored in a region never leave that region, such as data stored in the EU west never leave Ireland, or data in the US East never leaves Virginia.
AWS does support the ability for user controlled movement of data between regions for business continuance (BC), high availability (HA) and disaster recovery (DR). Read more here at the AWS Security and Compliance site and in this AWS white paper.
What about EBS?
That brings us to Elastic Block Storage (EBS) that is used by EC2 (read more about EC2 and instances here) as storage for cloud and virtual machines or compute instances. In addition to using S3 as a persistent backing store or target for holding snapshots EBS can be thought of as primary storage. You can provision and allocate EBS volumes in the different data centers of the various AWS availability zones. As part of allocating your EBS volume you indicate the type (standard) or provisioned IOP’s or the new EBS Optimized volumes. EBS Optimized volumes enables instances that support the feature to have better IO performance to storage.
The following image shows an EC2 instance with EBS volumes (standard and provisioned IOPS’s) along with S3 volumes and snapshots. In the following example the instance and volumes are being served via the AWS US East region (Northern Virginia) using availability zone US East 1a. In addition, EBS optimized volumes are shown being used in the example to increase bandwidth or throughput performance between storage and the compute instance.
Using the above as a basis, you can build on that to leverage multiple availability zones or regions for HA, BC and DR combined with application, network load balancing and other capabilities. Note that EBS volumes are protected for durability by being spread across different servers and storage in an availability zone. Additional protection is provided by using snapshots combined with S3. Additional BC and DR or HA protection can be accomplished by replicating data across availability zones.
The above is an example of tying various components and services together. For example using different AWS availability zones, instances, EBS, S3 and other tools including those from third parties. Here is a link to a free chapter download from Cloud and Virtual Data Storage Networking (CRC Press) pertaining to data protection, BC and DR (available at Amazon here and Kindle here). In addition here is an AWS white paper on using their services for BC, HA and DR.
EBS volumes are created ranging in size from 1GByte to 1Tbyte in space capacity with multiple volumes being mapped or attached to an EC2 instances. EBS volumes appear as a virtual disk drive for block storage. From the EC2 instance and guest operating system you can mount, format and use the EBS volumes as any other block disk drive with your favorite tools and file systems. In addition to space capacity, EBS volumes are also provisioned with standard IO (e.g. disk based) performance or high performance Provisioned IOPS (e.g. SSD) for thousands of IOPS per instance. AWS states that a standard EBS volume should support about 100 IOP’s on average, with about 2,000 IOPS for a provisioned IOP volume. Need more than 2,000 IOPS, then the AWS recommendation is to use multiple IOP provisioned volumes with data spread across those. Following is an example of AWS EBS volumes seen via the EC2 management interface.
AWS EC2 and EBS configuration status
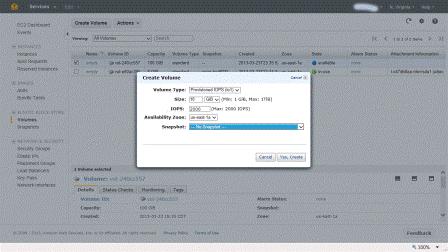
Note that there is a 10 to 1 ratio of space capacity to IOP’s being provisioned. If you try to play a game of 1,000 IOPS provisioned on a 10GByte EBS volume to keep your costs down you are out of luck. Thus to get 1,000 IOPS’s you would need to allocate at least a 100GByte EBS volume of which you will be billed for the actual space used on a monthly pro-rated basis. The following is an example of provisioning an AWS EBS volume using provisioned IOPS in the US East region in the 1a availability zone.
Provisioning IOPS with EBS volume
Standard and Provisioned IOPS EBS volumes
Standard EBS volumes are good for boot images or other application usage that are not IO performance intensive. For database or other active applications where more performance is needed, then EBS Provisioned IOPS volumes are your option. Note that the provisioned IOP rate is persistent for the specific volume during its life. Thus if you set it and forget it including not using it without turning it off, you will be billed for provisioning it.
All Comments, (C) and (TM) belong to their owners/posters, Other content (C) Copyright 2006-2026 Server StorageIO and UnlimitedIO LLC All Rights Reserved
The four EBS optimized instance types are m3.xlarge, m3.2xlarge, m2.2xlarge and c1.xlarge for dedicated bandwidth or throughput between the EC2 instances and EBS volumes. The performance or bandwidth ranges from 500 Mbits (500 / 8 = 62.5 MBytes) per second, to 1,000 Mbits (1,000 / 8 = 125MBytes) per second depending on the type of instance. As a refresher, EC2 instances (why by time you read this could change) vary in size and functionality with different amounts of EC2 Unit of Compute (ECU), number of virtual cores, amount of storage space included, 32 or 64 bit, storage and networking IO performance, and EBS Optimized or not. In addition to instances, different operating system images can be installed using those licensed from AWS such as various Windows and Unix or supply your own.
There are also different generations of instances such as M1 (first generation where one ECU = 1.0 to 1.2 Ghz of a 2007 era Opteron or Xeon processor), M3 (second generation with faster processors) along with Micro low-cost options. There are also other optimized instances including high or large amounts of memory, high CPU or compute processing, clustered compute, high memory clustered, clustered GPU (e.g. using Nivida Tesla GPUs), high IO and high storage space capacity needs.
Here is the announcement from AWS:
Dear Amazon Web Services Customer,
We are delighted to announce the global availability of EBS-optimized support for four additional instance types: m3.xlarge, m3.2xlarge, m2.2xlarge, and c1.xlarge. EBS-optimized instances deliver dedicated throughput between Amazon EC2 and Amazon EBS, with options between 500 Megabits per second and 1,000 Megabits per second depending on the instance type used. The dedicated throughput minimizes contention between EBS I/O and other traffic from your Amazon EC2 instance, providing the best performance for your EBS volumes.
EBS-optimized instances are designed for use with both Standard and Provisioned IOPS EBS volumes. Standard volumes deliver 100 IOPS on average with a best effort ability to burst to hundreds of IOPS, making them well-suited for workloads with moderate and bursty I/O needs. When attached to an EBS-optimized instance, Provisioned IOPS volumes are designed to consistently deliver up to 2000 IOPS from a single volume, making them ideal for I/O intensive workloads such as databases. You can attach multiple Amazon EBS volumes to a single instance and stripe your data across them for increased I/O and throughput performance.
Amazon EBS-optimized support is now available for m3.xlarge, m3.2xlarge, m2.2xlarge, m2.4xlarge, m1.large, m1.xlarge, and c1.xlarge instance types, and is currently supported in the US-East (N. Virginia), US-West (N. California), US-West (Oregon), EU-West (Ireland), Asia Pacific (Singapore), Asia Pacific (Japan), Asia Pacific (Sydney), and South America (São Paulo) Regions.
What this means is that AWS is enabling customers to size their compute instances and storage volumes with more flexibility to meet different needs. For example, EC2 instances with various compute processing capabilities, amount of memory, network and storage I/O performance to volumes. In addition, storage volumes based on different space capacity size, standard or provisioned IOP’s, bandwidth or throughput performance between the instance and volume, along with data protection such as snapshots.
This means that the cost per space capacity of an EBS volume varies based on which AWS availability zone it is in, standard (lower IOP performance) or provisioned IOP’s (faster), along with instance type. In other words, cloud storage is not just about the cost per GByte, it’s also about the cost for IOPS, bandwidth to use it, where it is located (e.g. with AWS which Availability Zone), type of service, level of availability and durability among other attributes.
Additional reading and related items:
Cloud conversations: AWS EBS, Glacier and S3 overview (Part I)
Cloud conversations: AWS EBS, Glacier and S3 overview (Part II)
Cloud conversations: AWS EBS, Glacier and S3 overview (Part III)
All Comments, (C) and (TM) belong to their owners/posters, Other content (C) Copyright 2006-2026 Server StorageIO and UnlimitedIO LLC All Rights Reserved
If your organization like StorageIO is a member of the Open Data Center Alliance (ODCA) you may be aware of the resources they make available about cloud, virtualization, security and more. Unlike so many other industry associates or trade groups dominated by vendors, the ODCA has an IT or customer focus including member developed best practices, strategies and templates.
A good example is the recently released ODCA member BMW group private cloud strategy document.
This 24 page document covers BMW groups private cloud strategy that sets stage for phased future hybrid. By being a phased approach, it seems that BMW is leveraging and transitioning for the future while maintaining support for their current environment (including Windows-based) as part of a paradigm shift. This is refreshing and good to see how organizations are looking to use cloud as part of a paradigm or IT service deliver model and not just as a new technology or platform focus.
Topics covered include IaaS along with PaaS for DB, Web, SAP and CSaaS or Corporate Software as a Service based on the NIST cloud model. Also included are roles and integration of CMDB, ITSM, ITIL, orchestration in a business vs. technology driven model. Being business driven, that means there is a mission statement for the BMW cloud strategy, with objectives aligned to support organization enablement vs. using different tools, technologies or trends along with design criteria.
What I like about the BMW strategy is that it is aligned to support the business as opposed to finding ways to use technology to support the business, or justify why a cloud is needed. In other words, something different from those needing for a technology, tool, product, standard or service to be adopted.
Thus while having been a vendor, the ODCA customer focused angle appeals to me from when I was on that side of the table working in IT organizations. Otoh, for some of you reading through the BMW document might result in DejaVu from experiences of web-based, client-server, information utilities and other IT service delivery models or paradigms.
Learn more at the ODCA newsroom
If you have not done, check out and join the ODCA.
All Comments, (C) and (TM) belong to their owners/posters, Other content (C) Copyright 2006-2026 Server StorageIO and UnlimitedIO LLC All Rights Reserved
Common community cloud conversation questions include among others:
Who defines the standards for community clouds? The members or participants, or whoever they hire or get to volunteer to do it.
Who pays for the community cloud? The members or participants do, think about a co-op or other resource sharing consortium with multi-tenant (shared) capabilities to isolate and keep members along with what they are doing separate.
Who are community clouds for, when to use them? If you cannot justify a private cloud for yourself, or, if you need more resiliency than what can be provided by your site and you know of a peer, partner, member or other with common needs, those could be a fit. Another variation is you are in an industry or agency or district where pooling of resources, yet operating separate has advantages or already being done. These range from medical and healthcare to education along with various small medium businesses (SMBs) that do not want to or cannot use a public facility for various reasons.
What technology is needed for building a community cloud? Similar to deploying a public or private cloud, you will need various hard products including servers, storage, networking, management software tools for provisioning, orchestration, show back or charge back, multi-tenancy, security and authentication, data protection (backup, bc, dr, ha) along with various middleware and applications.
What are community clouds used for? Almost anything, granted there are limits and boundaries based tools, technologies, security and access controls among other constraints. Applications can range from big-data to little-data on all if not most points in between. On the other hand, if they are not safe or secure enough for your needs, then use a private cloud or whatever it is that you are currently using.
What about community cloud security, privacy and compliance regulations? Those are topics and reasons why like-minded or affected groups might be able to leverage a community cloud. By being like-minded or affected groups, labs, schools, business, entities, agencies, districts, or other organizations that are under common mandates for security, compliance, privacy or other regulations can work together, yet keep their interests separate. What tools or techniques for achieving those goals and objectives would be dependent on those who offer services to those entities now?
Where can you get a community cloud? Look around using Google or your favorite search tool; also watch the comments section to see how long it takes someone to jump in to say how he or she can help. Also talk with solution providers, business partners and VARs. Note that they may not know the term or phrases per say, so here is what to tell them. Tell them that you would like to deploy a private cloud at some place that will then be used in a multi-tenant way to safely and securely support different members of your consortium.
For those who have been around long enough, you can also just tell them that you want to do something like the co-op or consortium time-sharing type systems from past generations and they may know what you are looking for. If although they look at you with a blank deer in the head-light stare eyes glazed over, just tell them it’s a new lead-edge, software defined new and revolutionary (add some superlatives if you feel inclined) and then they might get excited. If they still don’t know what to do or help you with, have them get in touch with me and I will explain it to them, or, I’ll put you in touch with those can help.
Where do you put a community cloud? You could deploy them in your own facility, other member’s locations or both for resiliency. You could also use a safe secure co-lo facility already being used for other purposes.
Do community clouds have organizers? Perhaps, however they are probably more along the lines of a coordinator, administrator, manager, controller as opposed to a community organizer per say. In other words, do not confuse a community cloud with a cloud community organized, aligned and activated for some particular cause. On the other hand, maybe there is value prop for some cloud activist to be organized and take up the cause for community clouds in your area of interest ;).
Are community clouds more of a concept vs. a product? If you have figured out that a community or peer cloud is nothing more than a different way of deploying, using and managing a combination of private, public and hybrid and putting a marketing name on them, congratulations, you are now thinking outside of the box, or outside of the usual cloud conversations.
What about public cloud services for selected audiences such as Amazons GovCloud? On one hand, I guess you could call or think of that as a semi-private public cloud, or a semi-public private cloud, or if you like superlatives an uber gallistic hybrid community cloud.
How you go about building, deploying and managing your community, coop, consortium, and agency, district or peer cloud will be how you leverage various hard and software products. The results of which will be your return on innovation (the new ROI) to address various needs and concerns or also known as valueware. Those results should be able to address or help close gaps and leverage clouds in general as a resource vs. simply as a tool, technology or technique.
All Comments, (C) and (TM) belong to their owners/posters, Other content (C) Copyright 2006-2026 Server StorageIO and UnlimitedIO LLC All Rights Reserved
Cloud computing including cloud storage and services as products, solutions and services offer different functionality and enable benefits for various types of organizations, entities or individuals.
Public clouds, private clouds and hybrids leveraging public and private continue to evolve in technology, reliability, security and functionality along with the awareness around them.
IT professionals tell me they are interested in clouds however they have concerns.
Cloud concerns range from security, compliance, industry or government regulations, privacy and budgets among others with private, public or hybrid clouds. Peer, cooperative (co-op), consortium or community clouds can be a solution for those that traditional public, private, hybrid, AaaS, SaaS, PaaS or IaaS do not meet their needs.
From a technology standpoint, there should have to be much if any difference between a community cloud and a public, private or hybrid. Instead, they community clouds are more about thinking outside of the box, or outside of common cloud thinking per say. This means thinking beyond what others are talking about or doing and looking at how cloud products, services and practices can be used in different ways to meet your concerns or requirements.
What’s your take on clouds, click here to cast your vote and see results
All Comments, (C) and (TM) belong to their owners/posters, Other content (C) Copyright 2006-2026 Server StorageIO and UnlimitedIO LLC All Rights Reserved
This is the second in a two-part industry trends and perspective looking at learning from cloud incidents, view part I here.
There is good information, insight and lessons to be learned from cloud outages and other incidents.
Sorry cynics no that does not mean an end to clouds, as they are here to stay. However when and where to use them, along with what best practices, how to be ready and configure for use are part of the discussion. This means that clouds may not be for everybody or all applications, or at least today. For those who are into clouds for the long haul (either all in or partially) including current skeptics, there are many lessons to be learned and leveraged.
In order to gain confidence in clouds, some questions that I routinely am asked include are clouds more or less reliable than what you are doing? Depends on what you are doing, and how you will be using the cloud services. If you are applying HA and other BC or resiliency best practices, you may be able to configure and isolate from the more common situations. On the other hand, if you are simply using the cloud services as a low-cost alternative selecting the lowest price and service class (SLAs and SLOs), you might get what you paid for. Thus, clouds are a shared responsibility, the service provider has things they need to do, and the user or person designing how the service will be used have some decisions making responsibilities.
Keep in mind that high availability (HA), resiliency, business continuance (BC) along with disaster recovery (DR) are the sum of several pieces. This includes people, best practices, processes including change management, good design eliminating points of failure and isolating or containing faults, along with how the components or technology used (e.g. hardware, software, networks, services, tools). Good technology used in goods ways can be part of a highly resilient flexible and scalable data infrastructure. Good technology used in the wrong ways may not leverage the solutions to their full potential.
While it is easy to focus on the physical technologies (servers, storage, networks, software, facilities), many of the cloud services incidents or outages have involved people, process and best practices so those need to be considered.
These incidents or outages bring awareness, a level set, that this is still early in the cloud evolution lifecycle and to move beyond seeing clouds as just a way to cut cost, and seeing the importance and value HA, resiliency, BC and DR. This means learning from mistakes, taking action to correct or fix errors, find and cut points of failure are part of a technology maturing or the use of it. These all tie into having services with service level agreements (SLAs) with service level objectives (SLOs) for availability, reliability, durability, accessibility, performance and security among others to protect against mayhem or other things that can and do happen.
The reason I mentioned earlier that AWS had another incident is that like their peers or competitors who have incidents in the past, AWS appears to be going through some growing, maturing, evolution related activities. During summer 2012 there was an AWS incident that affected Netflix (read more here: AWS and the Netflix Fix?). It should also be noted that there were earlier AWS outages where Netflix (read about Netflix architecture here) leveraged resiliency designs to try and prevent mayhem when others were impacted.
Is AWS a lightning rod for things to happen, a point of attraction for Mayhem and others?
Granted given their size, scope of services and how being used on a global basis AWS is blazing new territory and experiences, similar to what other information services delivery platforms did in the past. What I mean is that while taken for granted today, open systems Unix, Linux, Windows-based along with client-server, midrange or distributed systems, not to mention mainframe hardware, software, networks, processes, procedures, best practices all went through growing pains.
There are a couple of interesting threads going on over in various LinkedIn Groups based on some reporters stories including on speculation of what happened, followed with some good discussions of what actually happened and how to prevent recurrence of them in the future.
Over in the Cloud Computing, SaaS & Virtualization group forum, this thread is based on a Forbes article (Amazon AWS Takes Down Netflix on Christmas Eve) and involves conversations about SLAs, best practices, HA and related themes. Have a look at the story the thread is based on and some of the assertions being made, and ensuing discussions.
Also over at LinkedIn, in the Cloud Hosting & Service Providers group forum, this thread is based on a story titled Why Netflix’ Christmas Eve Crash Was Its Own Fault with a good discussion on clouds, HA, BC, DR, resiliency and related themes.
Over at the Virtualization Practice, there is a piece titled Is Amazon Ruining Public Cloud Computing? with comments from me and Adrian Cockcroft (@Adrianco) a Netflix Architect (you can read his blog here). You can also view some presentations about the Netflix architecture here.
What this all means
Saying you get what you pay for would be too easy and perhaps not applicable.
There are good services free, or low-cost, just like good free content and other things, however vice versa, just because something costs more, does not make it better.
Otoh, there are services that charge a premium however may have no better if not worse reliability, same with content for fee or perceived value that is no better than what you get free.
Clouds are real and can be used safely; however, they are a shared responsibility.
Only you can prevent cloud data loss, which means do your homework, be ready.
If something can go wrong, it probably will, particularly if humans are involved.
Prepare for the unexpected and clarify assumptions vs. realities of service capabilities.
Leverage fault isolation and containment to prevent rolling or spreading disasters.
Look at cloud services beyond lowest cost or for cost avoidance.
What is your organizations culture for learning from mistakes vs. fixing blame?
Ask yourself if you, your applications and organization are ready for clouds.
Ask your cloud providers if they are ready for you and your applications.
Identify what your cloud concerns are to decide what can be done about them.
Do a proof of concept to decide what types of clouds and services are best for you.
Do not be scared of clouds, however be ready, do your homework, learn from the mistakes, misfortune and errors of others. Establish and leverage known best practices while creating new ones. Look at the past for guidance to the future, however avoid clinging to, and bringing the baggage of the past to the future. Use new technologies, tools and techniques in new ways vs. using them in old ways.
All Comments, (C) and (TM) belong to their owners/posters, Other content (C) Copyright 2006-2026 Server StorageIO and UnlimitedIO LLC All Rights Reserved
This is the first of a two-part industry trends and perspectives series looking at how to learn from cloud outages (read part II here).
In case you missed it, there were some public cloud outages during the recent Christmas 2012-holiday season. One incident involved Microsoft Xbox (view the Microsoft Azure status dashboard here) users were impacted, and the other was another Amazon Web Services (AWS) incident. Microsoft and AWS are not alone, most if not all cloud services have had some type of incident and have gone on to improve from those outages. Google has had issues with different applications and services including some in December 2012 along with a Gmail incident that received covered back in 2011.
For those interested, here is a link to the AWS status dashboard and a link to the AWS December 24 2012 incident postmortem. In the case of the recent AWS incident which affected users such as Netflix, the incident (read the AWS postmortem and Netflix postmortem) was tied to a human error. This is not to say AWS has more outages or incidents vs. others including Microsoft, it just seems that we hear more about AWS when things happen compared to others. That could be due to AWS size and arguably market leading status, diversity of services and scale at which some of their clients are using them.
Btw, if you were not aware, Microsoft Azure is more than just about supporting SQLserver, Exchange, SharePoint or Office, it is also an IaaS layer for running virtual machines such as Hyper-V, as well as a storage target for storing data. You can use Microsoft Azure storage services as a target for backing up or archiving or as general storage, similar to using AWS S3 or Rackspace Cloud files or other services. Some backup and archiving AaaS and SaaS providers including Evault partner with Microsoft Azure as a storage repository target.
When reading some of the coverage of these recent cloud incidents, I am not sure if I am more amazed by some of the marketing cloud washing, or the cloud bashing and uniformed reporting or lack of research and insight. Then again, if someone repeats a myth often enough for others to hear and repeat, as it gets amplified, the myth may assume status of reality. After all, you may know the expression that if it is on the internet then it must be true?
From CRN, here are some cloud service availability status via Nasuni
The above are a small sampling of different stories, articles, columns, blogs, perspectives about cloud services outages or other incidents. Assuming the services are available, you can Google or Bing many others along with reading postmortems to gain insight into what happened, the cause, effect and how to prevent in the future.
Do these recent incidents show a trend of increased cloud outages? Alternatively, do they say that the cloud services are being used more and on a larger basis, thus the impacts become more known?
Perhaps it is a mix of the above, and like when a magnetic storage tape gets lost or stolen, it makes for good news or copy, something to write about. Granted there are fewer tapes actually lost than in the past, and far fewer vs. lost or stolen laptops and other devices with data on them. There are probably other reasons such as the lightning rod effect given how much industry hype around clouds that when something does happen, the cynics or foes come out in force, sometimes with FUD.
Similar to traditional hardware or software based product vendors, some service providers have even tried to convince me that they have never had an incident, lost or corrupted or compromised any data, yeah, right. Candidly, I put more credibility and confidence in a vendor or solution provider who tells me that they have had incidents and taken steps to prevent them from recurring. Granted those steps might be made public while others might be under NDA, at least they are learning and implementing improvements.
As part of gaining insights, here are some links to AWS, Google, Microsoft Azure and other service status dashboards where you can view current and past situations.
Disclosure: I am a customer of AWS for EC2, EBS, S3 and Glacier as well as a customer of Bluehost for hosting and Rackspace for backups. Other than Amazon being a seller of my books (and my blog via Kindle) along with running ads on my sites and being an Amazon Associates member (Google also has ads), none of those mentioned are or have been StorageIO clients.
All Comments, (C) and (TM) belong to their owners/posters, Other content (C) Copyright 2006-2026 Server StorageIO and UnlimitedIO LLC All Rights Reserved
The Open Data Center Alliance (ODCA) has announced and published more documents for data center customers of cloud usage. These new cloud usage models for to address customer demands for interoperability of various clouds and services before for Infrastructure as a Service (IaaS) among other topics which are now joined by the new Software as a Service (SaaS), Platform as a Service (PaaS) and foundational document for cloud interoperability.
Unlike most industry trade groups or alliances that are vendor driven or centric, ODCA is consortium of global IT leaders (e.g. customers) that is vendor independent and comprises as 12 member steering committee from member companies (e.g. customers), learn more about ODCA here.
Disclosure note, StorageIO is an ODCA member, visit here to become an ODCA member.
From the ODCA announcement of the new documents:
The documents detail expectations for market delivery to the organizations mission of open, industry standard cloud solution adoption, and discussions have already begun with providers to help accelerate delivery of solutions based on these new requirements. This suite of requirements was joined by a Best Practices document from National Australia Bank (NAB) outlining carbon footprint reductions in cloud computing. NAB’s paper illustrates their leadership in innovative methods to report carbon emissions in the cloud and aligns their best practices to underlying Alliance requirements. All of these documents are available in the ODCA Documents Library.
The PaaS interoperability usage model outlines requirements for rapid application deployment, application scalability, application migration and business continuity. The SaaS interoperability usage model makes applications available on demand, and encourages consistent mechanisms, enabling cloud subscribers to efficiently consume SaaS via standard interactions. In concert with these usage models, the Alliance published the ODCA Guide to Interoperability, which describes proposed requirements for interoperability, portability and interconnectivity. The documents are designed to ensure that companies are able to move workloads across clouds.
It is great to see IT customer driven or centric groups step and actually deliver content and material to help their peers, or in some cases competitors that compliments information provided by vendors and vendor driven trade groups.
As with technologies, tools and services that often are seen as competitive, a mistake would be viewing ODCA as or in competition with other industry trade groups and organizations or vise versa. Rather, IT organizations and vendors can and should leverage the different content from the various sources. This is an opportunity for example vendors to learn more about what the customers are thinking or concerned about as opposed to telling IT organizations what to be looking at and vise versa.
Granted some marketing organizations or even trade groups may not like that and view groups such as ODCA as giving away control of who decides what is best for them. Smart vendors, vars, business partners, consultants and advisors are and will leverage material and resources such as ODCA, and likewise, groups like ODCA are open to including a diverse membership unlike some pay to play industry vendor centric trade groups. If you are a vendor, var or business partner, don’t look at ODCA as a threat, instead, explore how your customers or prospects may be involved with, or using ODCA material and leverage that as a differentiator between you and your competitor.
Likewise don’t be scared of vendor centric industry trade groups, alliances or consortiums, even the pay to play ones can have some value, although some have more value than others. For example from a storage and storage networking perspective, there are the Storage Networking Industry Association (SNIA) along with their various groups focused on Green and Energy along with Cloud Data Management Initiative (CDMI) related topics among others. There is also the SCSI Trade Association (STA) along with the Open Virtualization Alliance (OVA) not to mention the Open Fabric Alliance (OVA),Open Networking Foundation(ONF) and Computer Measurement Group (CMG) among many others that do good work and offer value with diverse content and offerings, some of which are free including to non members.
Learn more about the ODCA here, along with access various documents including usage models in the ODCA document library here.
While you are at, why not join StorageIO and other members by signing up to become a part of the ODCA here.
I recently came across a piece by Carl Brooks over at IT Tech News Daily that caught my eye, title was Cloud Storage Often Results in Data Loss. The piece has an effective title (good for search engine: SEO optimization) as it stood out from many others I saw on that particular day.
What caught my eye on Carls piece is that it reads as if the facts based on a quick survey point to clouds resulting in data loss, as opposed to being an opinion that some cloud usage can result in data loss.
My opinion is that if not used properly including ignoring best practices, any form of data storage medium or media could result or be blamed for data loss. For some people they have lost data as a result of using cloud storage services just as other people have lost data or access to information on other storage mediums and solutions. For example, data has been lost on tape, Hard Disk Drives (HDDs), Solid State Devices (SSD), Hybrid HDDs (HHDD), RAID and non RAID, local and remote and even optical based storage systems large and small. In some cases, there have been errors or problems with the medium or media, in other cases storage systems have lost access to, or lost data due to hardware, firmware, software, or configuration including due to human error among other issues.
Technology failure: Not if, rather when and how to decrease impact Any technology regardless of what it is or who it is from along with its architecture design and implementation can fail. It is not if, rather when and how gracefully along with what safeguards to decrease the impact, in addition to containing or isolating faults differentiates various products or solutions. How they automatically repair and self heal to keep running or support accessibility and maintain data integrity are important as is how those options are used. Granted a failure may not be technology related per say, rather something associated with human intervention, configuration, change management (or lack thereof) along with accidental or intentional activities.
I follow my advice and best practices when selecting cloud providers looking for good value, service level agreements (SLAs) and service level objectives (SLOs) over low cost or for free services.
In the several years of using cloud based storage and services there has been some loss of access, however no loss of data. Those service disruptions or loss of access to data and services ranged from a few minutes to a little over an hour. In those scenarios, if I could not have waited for cloud storage to become accessible, I could have accessed a local copy if it were available.
Had a major disruption occurred where it would have been several days before I could gain access to that information, or if it were actually lost, I have a data insurance policy. That data insurance policy is part of my business continuance (BC) and disaster recovery (DR) strategy. My BC and DR strategy is a multi layered approach combining local, offline and offsite as along with online cloud data protection and archiving.
Assuming my cloud storage service could get data back to a given point (RPO) in a given amount of time (RTO), I have some options. One option is to wait for the service or information to become available again assuming a local copy is no longer valid or available. Another option is to start restoration from a master gold copy and then roll forward changes from the cloud services as that information becomes available. In other words, I am using cloud storage as another resource that is for both protecting what is local, as well as complimenting how I locally protect things.
Minimize or cut data loss or loss of access Anything important should be protected locally and remotely meaning leveraging cloud and a master or gold backup copy.
To cut the cost of protecting information, I also leverage archives, which mean not all data gets protected the same. Important data is protected more often reducing RPO exposure and speed up RTO during restoration. Other data that is not as important is protected, however on a different frequency with other retention cycles, in other words, tiered data protection. By implementing tiered data protection, best practices, and various technologies including data footprint reduction (DFR) such as archive, compression, dedupe in addition to local disk to disk (D2D), disk to disk to cloud (D2D2C), along with routine copies to offline media (removable HDDs or RHDDs) that go offsite, Im able to stretch my data protection budget further. Not only is my data protection budget stretched further, I have more options to speed up RTO and better detail for recovery and enhanced RPOs.
If you are looking to avoid losing data, or loss of access, it is a simple equation in no particular order:
Strategy and design
Best practices and processes
Various technologies
Quality products
Robust service delivery
Configuration and implementation
SLO and SLA management metrics
People skill set and knowledge
Usage guidelines or terms of service (ToS)
Unfortunately, clouds like other technologies or solutions get a bad reputation or blamed when something goes wrong. Sometimes it is the technology or service that fails, other times it is a combination of errors that resulted in loss of access or lost data. With clouds as has been the case with other storage mediums and systems in the past, when something goes wrong and if it has been hyped, chances are it will become a target for blame or finger pointing vs. determining what went wrong so that it does not occur again. For example cloud storage has been hyped as easy to use, don’t worry, just put your data there, you can get out of the business of managing storage as the cloud will do that magically for you behind the scenes.
The reality is that while cloud storage solutions can offload functions, someone is still responsible for making decisions on its usage and configuration that impact availability. What separates various providers is their ability to design in best practices, isolate and contain faults quickly, have resiliency integrated as part of a solution along with various SLAs aligned to what the service level you are expecting in an easy to use manner.
Does that mean the more you pay the more reliable and resilient a solution should be? No, not necessarily, as there can still be risks including how the solution is used.
Does that mean low cost or for free solutions have the most risk? No, not necessarily as it comes down to how you use or design around those options. In other words, while cloud storage services remove or mask complexity, it still comes down to how you are going to use a given service.
Shared responsibility for cloud (and non cloud) storage data protection Anything important enough that you cannot afford to lose, or have quick access to should be protected in different locations and on various mediums. In other words, balance your risk. Cloud storage service provider toned to take responsibility to meet service expectations for a given SLA and SLOs that you agree to pay for (unless free).
As the customer you have the responsibility of following best practices supplied by the service provider including reading the ToS. Part of the responsibility as a customer or consumer is to understand what are the ToS, SLA and SLOs for a given level of service that you are using. As a customer or consumer, this means doing your homework to be ready as a smart educated buyer or consumer of cloud storage services.
If you are a vendor or value added reseller (VAR), your opportunity is to help customers with the acquisition process to make informed decision. For VARs and solution providers, this can mean up selling customers to a higher level of service by making them aware of the risk and reward benefits as opposed to focus on cost. After all, if a order taker at McDonalds can ask Would you like to super size your order, why cant you as a vendor or solution provider also have a value oriented up sell message.
Additional related links to read more and sources of information:
Poll: Who is responsible for cloud storage data loss?
Taking action, what you should (or not) do Dont be scared of clouds, however do your homework, be ready, look before you leap and follow best practices. Look into the service level agreements (SLAs) associated with a given cloud storage product or service. Follow best practices about how you or someone else will protect what data is put into the cloud.
For critical data or information, consider having a copy of that data in the cloud as well as at or in another place, which could be in a different cloud or local or offsite and offline. Keep in mind the theme for critical information and data is not if, rather when so what can be done to decrease the risk or impact of something happening, in other words, be ready.
Data put into the cloud can be lost, or, loss of access to it can occur for some amount of time just as happens with using non cloud storage such as tape, disk or ssd. What impacts or minimizes your risk of using traditional local or remote as well as cloud storage are the best practices, how configured, protected, secured and managed. Another consideration is the type and quality of the storage product or cloud service can have a big impact. Sure, a quality product or service can fail; however, you can also design and configure to decrease those impacts.
Wrap up Bottom line, do not be scared of cloud storage, however be ready, do your homework, review best practices, understand benefits and caveats, risk and reward. For those who want to learn more about cloud storage (public, private and hybrid) along with data protection, data management, data footprint reduction among other related topics and best practices, I happen to know of some good resources. Those resources in addition to the links provided above are titled Cloud and Virtual Data Storage Networking (CRC Press) that you can learn more about here as well as find at Amazon among other venues. Also, check out Enterprise Systems Backup and Recovery: A Corporate Insurance Policy by Preston De Guise (aka twitter @backupbear ) which is a great resource for protecting data.
What do VARs and Clouds as well as MSPs have in common?
Several things it turns out:
Some Value Added Resellers (VARS) (links to VAR related content and comments here, here and here) sell cloud services or solutions
Some VARs are also cloud or managed solutions providers (MSPs) themselves, thus some cloud or MSPs are VARs
Some VARs, cloud and MSPs compete on lowest or cheapest price
Some VARs, cloud and MSPs have diverse product offering portfolios
Some VARs, cloud and MSPs compete on value (e.g. not price)
Some VARs, cloud and MSPs value is in the trust, security and peace of mind that they provide to their client
For some, the value of a given VAR, cloud or MSP is the ability to shop around for a resource to get the lowest price.
For others, the value of a given VAR, cloud or MSP is the ability to get the best value which may not be the lowest price rather the most effective overall cost per services with trust, security, experience and peace of mind provided.
Value to often is confused with being cheap or lowest cost.
Value can also mean a higher price that includes more thus providing a better effective option (e.g. super size it).
On the other hand, higher priced should not be confused with always being a better product, service or solution.
You may find that the initial low cost requires other add on fees or activation charges, surcharges for use or activity along with optional services to make the solution useful all resulting in an overall higher amount to be paid.
Lowest cost may result in a bargain now and then if that fits your needs.
Value can also mean a better option providing an improved return on investment if a solution or service meets and exceeds your needs and expectations.
As an example, I recently switched from a cloud backup MSP (Mozy) not due to cost (costs would have gone down with their recent service plan announcement) rather I needed more value and functionality. With my new cloud backup MSP I get more functionality and capability that I can continue to grow into even though the price per GByte is higher than with my previous provider. What made the change of positive is what I get in the higher fee per GByte that in the end, actually makes it more affordable, not cheaper, just better value and return on investment.
For some low cost is value while for others, value is more than lowest cost including what you get for a given fee including trust, security, service and experience among other items. Different people will have different requirements or needs for what is or is not value.
If you do not like the term value, then try price performer.
Bottom line for now, with VARs, MSPs and Cloud (Public or private) dont be scared, however look before you leap!
All Comments, (C) and (TM) belong to their owners/posters, Other content (C) Copyright 2006-2026 Server StorageIO and UnlimitedIO LLC All Rights Reserved































{kind=link}