
RTO Context Matters
With RTO context matters similar to many things in and around Information Technology (IT) among other industries. Various three (or more) letter acronyms (TLAs) have different meanings based on their context. An example of a TLA is RTO which has different meanings. For instance, RTO can mean:
- Return To Office
- Recovery Time Objective
- Ready To Operate
- Return To Operations
- Among others…
From the data protection and cyber resilience context, RTO has traditionally been thought of as a Recovery Time Objective or the amount of time that something should be able to be restored, recovered, rebuilt, reset, or returned to service, aka being usable. Another way of looking at Recovery Time Objective is the goal or requirement that something is ready to operate, enabling an organization and its IT services apps, data, and information to return to operations.

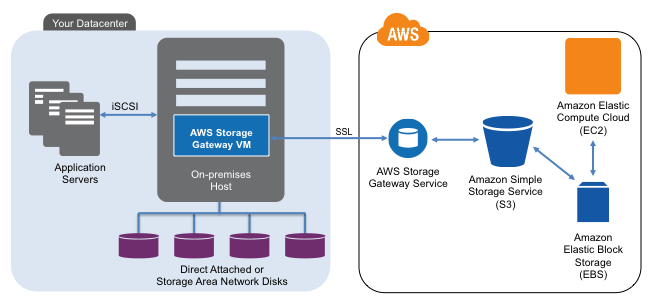
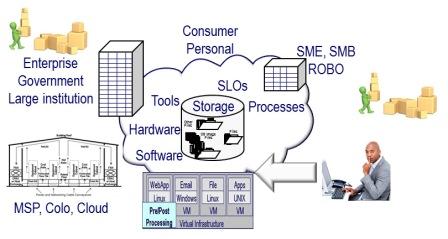
Figure 1 Data Infrastructures and Recovery Time Objectives (RTO)
RTO Recovery Time Object Context
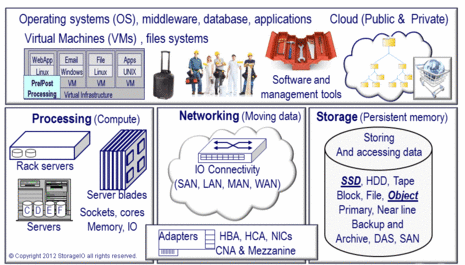
Where context is needed is not just simply what RTO is being discussed, e.g., recovery time objective; also, what is the scope of the recovery time objective? Is it all-inclusive for a specific component, layer, or focus point? A holistic RTO is when everything in the stack, vertical up and down all layers of hardware, software, services, and, if applicable, also horizontal across different systems, platforms, and locations, is usable. For example, when a user can access an app from various places, and everything is functioning, perhaps not at full or regular speed, it is functioning.

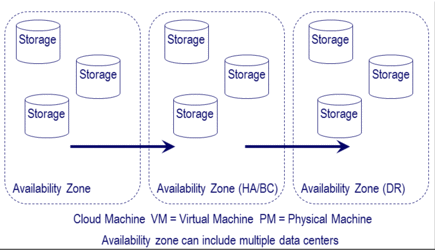
Figure 2 Various Threats and Data Infrastructure Layers
Recovery Time Objective Focus
On the other hand, component RTO refers to a specific focus area, point, or location in the stack (figure 2). For example, a lower-level server, network, storage device, physical or virtual machine, container, file system, database repository, or application is restored or returned to readiness and operation. The individual components may be restored to operating; however, what about the sum of all the parts that make up the holistic solution or service the user sees and expects to be in working condition?
Additional Resources Where to learn more
The following links are additional resources to learn more about Recovery Time Objectives (RTO) and related data infrastructures, tradecraft, and metrics that matter topics.
Various excerpts from Chapter 9 Software Defined Data Infrastructure book
Modernizing Data Protection (Blog Post)
Data Protection Diaries (Blog Post)
Azure Cloud Storage Options (Blog Post)
Availability and Accessibility (Article)
Additional learning experiences along with common questions (and answers), are found in my Software Defined Data Infrastructure Essentials book.

What this all means
RTO context matters, not only for which RTO but also if it refers to a holistic compound aggregate scope or that of a component. While component RTOs are essential, so is the holistic focus of when things are usable.
Ok, nuff said.
Cheers Gs
Greg Schulz – Nine time Microsoft MVP Cloud and Data Center Management and Azure Storage, along with previous ten-time VMware vExpert. Author of Software Defined Data Infrastructure Essentials (CRC Press), as well as Cloud and Virtual Data Storage Networking (CRC Press), The Green and Virtual Data Center (CRC Press), Resilient Storage Networks (Elsevier) and twitter @storageio. Courteous comments are welcome for consideration. First published on https://storageioblog.com any reproduction in whole, in part, with changes to content, without source attribution under title or without permission is forbidden.
All Comments, (C) and (TM) belong to their owners/posters, Other content (C) Copyright 2006-2026 Server StorageIO and UnlimitedIO. All Rights Reserved. StorageIO is a registered Trade Mark (TM) of UnlimitedIO LLC.

























{kind=link}