In a flurry of announcements that coincide with EMCworld occurring in Boston this week of May 10 2010 EMC officially unveiled the Virtual Storage vision initiative (aka twitter hash tag of #emcvs) and initial VPLEX product. The Virtual Storage initiative was virtually previewed back in March (See my previous post here along with one from Stu Miniman (twitter @stu) of EMC here or here) and according to EMC the VPLEX product was made generally available (GA) back in April.
The Virtual Storage vision and associated announcements consisted of:
- Virtual Storage vision – Big picture initiative view of what and how to enable private clouds
- VPLEX architecture – Big picture view of federated data storage management and access
- First VPLEX based product – Local and campus (Metro to about 100km) solutions
- Glimpses of how the architecture will evolve with future products and enhancements


Figure 1: EMC Virtual Storage and Virtual Server Vision and Big Pictures
The Big Picture
The EMC Virtual Storage vision (Figure 1) is the foundation of a private IT cloud which should enable characteristics including transparency, agility, flexibility, efficient, always on, resiliency, security, on demand and scalable. Think of it this way, EMC wants to enable and facilitate for storage what is being done by server virtualization hypervisor vendors including VMware (which happens to be owned by EMC), Microsoft HyperV and Citrix/Xen among others. That is, break down the physical barriers or constraints around storage similar to how virtual servers release applications and their operating systems from being tied to a physical server.
While the current focus of desktop, server and storage virtualization has been focused on consolidation and cost avoidance, the next big wave or phase is life beyond consolidation where the emphasis expands to agility, flexibility, ease of use, transparency, and portability (Figure 2). In the next phase which puts an emphasis around enablement and doing more with what you have while enhancing business agility focus extends from how much can be consolidated or the number of virtual machines per physical machine to that of using virtualization for flexibility, transparency (read more here and here or watch here).

Figure 2: Virtual Storage Big Picture
That same trend will be happening with storage where the emphasis also expands from how much data can be squeezed or consolidated onto a given device to that of enabling flexibility and agility for load balancing, BC/DR, technology upgrades, maintenance and other routine Infrastructure Resource Management (IRM) tasks.
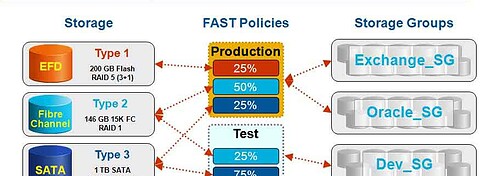
For EMC, achieving this vision (both directly for storage, and indirectly for servers via their VMware subsidiary) is via local and distributed (metro and wide area) federation management of physical resources to support virtual data center operations. EMC building blocks for delivering this vision including VPLEX, data and storage management federation across EMC and third party products, FAST (fully automated storage tiering), SSD, data protection and data footprint reduction and data protection management products among others.
Buzzword bingo aside (e.g. LAN, SAN, MAN, WAN, Pots and Pans) along with Automation, DWDM, Asynchronous, BC, BE or Back End, Cache coherency, Cache consistency, Chargeback, Cluster, db loss, DCB, Director, Distributed, DLM or Distributed Lock Management, DR, Foe or Fibre Channel over Ethernet, FE or Front End, Federated, FAST, Fibre Channel, Grid, HyperV, Hypervisor, IRM or Infrastructure Resource Management, I/O redirection, I/O shipping, Latency, Look aside, Metadata, Metrics, Public/Private Cloud, Read ahead, Replication, SAS, Shipping off to Boston, SRA, SRM, SSD, Stale Reads, Storage virtualization, Synchronization, Synchronous, Tiering, Virtual storage, VMware and Write through among many other possible candidates the big picture here is about enabling flexibility, agility, ease of deployment and management along with boosting resource usage effectiveness and presumably productivity on a local, metro and future global basis.


Figure 3: EMC Storage Federation and Enabling Technology Big Picture
The VPLEX Big Picture
Some of the tenants of the VPLEX architecture (Figure 3) include a scale out cluster or grid design for local and distributed (metro and wide area) access where you can start small and evolve as needed in a predictable and deterministic manner.


Figure 4: Generic Virtual Storage (Local SAN and MAN/WAN) and where VPLEX fits
The VPLEX architecture is targeted towards enabling next generation data centers including private clouds where ease and transparency of data movement, access and agility are essential. VPLEX sits atop existing EMC and third party storage as a virtualization layer between physical or virtual servers and in theory, other storage systems that rely on underlying block storage. For example in theory a NAS (NFS, CIFS, and AFS) gateway, CAS content archiving or Object based storage system or purpose specific database machine could sit between actual application servers and VPLEX enabling multiple layers of flexibility and agility for larger environments.
At the heart of the architecture is an engine running a highly distributed data caching algorithm that uses an approach where a minimal amount of data is sent to other nodes or members in the VPLEX environment to reduce overhead and latency (in theory boosting performance). For data consistency and integrity, a distributed cache coherency model is employed to protect against stale reads and writes along with load balancing, resource sharing and failover for high availability. A VPLEX environment consists of a federated management view across multiple VPLEX clusters including the ability to create a stretch volume that is accessible across multiple VPLEX clusters (Figure 5).

Figure 5: EMC VPLEX Big Picture

Figure 6: EMC VPLEX Local with 1 to 4 Engines
Each VPLEX local cluster (Figure 6) is made up of 1 to 4 engines (Figure 7) per rack with each engine consisting of two directors each having 64GByte of cache, localized compute Intel processors, 16 Front End (FE) and 16 Back End (BE) Fibre Channel ports configured in a high availability (HA). Communications between the directors and engines is Fibre Channel based. Meta data is moved between the directors and engines in 4K blocks to maintain consistency and coherency. Components are fully redundant and include phone home support.

Figure 7: EMC VPLEX Engine with redundant directors
VPLEX initially host servers supported include VMware, Cisco UCS, Windows, Solaris, IBM AIX, HPUX and Linux along with EMC PowerPath and Windows multipath management drivers. Local server clusters supported include Symantec VCS, Microsoft MSCS and Oracle RAC along with various volume mangers. SAN fabric connectivity supported includes Brocade and Cisco as well as Legacy McData based products.
VPLEX also supports cache (Figure 8 ) write thru to preserve underlying array based functionality and performance with 8,000 total virtualized LUNs per system. Note that underlying LUNs can be aggregated or simply passed through the VPLEX. Storage that attaches to the BE Fibre Channel ports include EMC Symmetrix VMAX and DMX along with CLARiiON CX and CX4. Third party storage supported includes HDS9000 and USPV/VM along with IBM DS8000 and others to be added as they are certified. In theory given that the VPLEX presents block based storage to hosts; one would also expect that NAS, CAS or other object based gateways and servers that rely on underlying block storage to also be supported in the future.

Figure 8: VPLEX Architecture and Distributed Cache Overview
Functionality that can be performed between the cluster nodes and engines with VPLEX include data migration and workload movement across different physical storage systems or sites along with shared access with read caching on a local and distributed basis. LUNS can also be pooled across different vendors underlying storage solutions that also retain their native feature functionality via VPLEX write thru caching.
Reads from various servers can be resolved by any node or engine that checks their cache tables (Figure 8 ) to determine where to resolve the actual I/O operation from. Data integrity checks are also maintained to prevent stale reads or write operations from occurring. Actual meta data communications between nodes is very small to enable state fullness while reducing overhead and maximizing performance. When a change to cache data occurs, meta information is sent to other nodes to maintain the distributed cache management index schema. Note that only pointers to where data and fresh cache entries reside are what is stored and communicated in the meta data via the distributed caching algorithm.

Figure 9: EMC VPLEX Metro Today
For metro deployments, two clusters (Figure 9) are utilized with distances supported up to about 100km or about 5ms of latency in a synchronous manner utilizing long distance Fibre Channel optics and transceivers including Dense Wave Division Multiplexing (DWDM) technologies (See Chapter 6: Metropolitan and Wide Area Storage Networking in Resilient Storage Networking (Elsevier) for additional details on LAN, MAN and WAN topics).
Initially EMC is supporting local or Metro including Campus based VPLEX deployments requiring synchronous communications however asynchronous (WAN) Geo and Global based solutions are planned for the future (Figure 10).

Figure 10: EMC VPLEX Future Wide Area and Global
Online Workload Migration across Systems and Sites
Online workload or data movement and migration across storage systems or sites is not new with solutions available from different vendors including Brocade, Cisco, Datacore, EMC, Fujitsu, HDS, HP, IBM, LSI and NetApp among others.
For synchronization and data mobility operations such as a VMware Vmotion or Microsoft HyperV Live migration over distance, information is written to separate LUNs in different locations across what are known as stretch volumes to enable non disruptive workload relocation across different storage systems (arrays) from various vendors. Once synchronization is completed, the original source can be disconnected or taken offline for maintenance or other common IRM tasks. Note that at least two LUNs are required, or put another way, for every stretch volume, two LUNs are subtracted from the total number of available LUNs similar to how RAID 1 mirroring requires at least two disk drives.
Unlike other approaches that for coherency and performance rely on either no cached data, or, extensive amounts of cached data along with subsequent overhead for maintaining state fullness (consistency and coherency) including avoiding stale reads or writes, VPLEX relies on a combination of distributed cache lookup tables along with pass thru access to underlying storage when or where needed. Consequently large amounts of data does not need to be cached as well as shipped between VPLEX devices to maintain data consistency, coherency or performance which should also help to keep costs affordable.
Approach is not unique, it is the implementation
Some storage virtualization solutions that have been software based running on an appliance or network switch as well as hardware system based have had a focus of emulating or providing competing capabilities with those of mid to high end storage systems. The premise has been to use lower cost, less feature enabled storage systems aggregated behind the appliance, switch or hardware based system to provide advanced data and storage management capabilities found in traditional higher end storage products.
VPLEX while like any tool or technology could be and probably will be made to do other things than what it is intended for is really focused on, flexibility, transparency and agility as opposed to being used as a means of replacing underlying storage system functionality. What this means is that while there is data movement and migration capabilities including ability to synchronize data across sites or locations, VPLEX by itself is not a replacement for the underlying functionality present in both EMC and third party (e.g. HDS, HP, IBM, NetApp, Oracle/Sun or others) storage systems.
This will make for some interesting discussions, debates and applies to oranges comparisons in particular with those vendors whose products are focused around replacing or providing functionality not found in underlying storage system products.
In a nut shell summary, VPLEX and the Virtual Storage story (vision) is about enabling agility, resiliency, flexibility, data and resource mobility to simply IT Infrastructure Resource Management (IRM). One of the key themes of global storage federation is anywhere access on a local, metro, wide area and global basis across both EMC and heterogeneous third party vendor hardware.
Lets Put it Together: When and Where to use a VPLEX
While many storage virtualization solutions are focused around consolidation or pooling, similar to first wave server and desktop virtualization, the next general broad wave of virtualization is life beyond consolidation. That means expanding the focus of virtualization from consolidation, pooling or LUN aggregation to that of enabling transparency for agility, flexibility, data or system movement, technology refresh and other common time consuming IRM tasks.
Some applications or usage scenarios in the future should include in addition to VMware Vmotion, Microsoft HypverV and Microsoft Clustering along with other host server closuring solutions.

Figure 11: EMC VPLEX Usage Scenarios
Thoughts and Industry Trends Perspectives:
The following are various thoughts, comments, perspectives and questions pertaining to this and storage, virtualization and IT in general.
Is this truly unique as is being claimed?
Interestingly, the message Im hearing out of EMC is not the claim that this is unique, revolutionary or the industries first as is so often the case by vendors, rather that it is their implementation and ability to deploy on a broad perspective basis that is unique. Now granted you will probably hear as is often the case with any vendor or fan boy/fan girl spins of it being unique and Im sure this will also serve up plenty of fodder for mudslinging in the blogsphere, YouTube galleries, twitter land and beyond.
What is the DejaVu factor here?
For some it will be nonexistent, yet for others there is certainly a DejaVu depending on your experience or what you have seen and heard in the past. In some ways this is the manifestation of many vision and initiatives from the late 90s and early 2000s when storage virtualization or virtual storage in an open context jumped into the limelight coinciding with SAN activity. There have been products rolled out along with proof of concept technology demonstrators, some of which are still in the market, others including companies have fallen by the way side for a variety of reasons.
Consequently if you were part of or read or listened to any of the discussions and initiatives from Brocade (Rhapsody), Cisco (SVC, VxVM and others), INRANGE (Tempest) or its successor CNT UMD not to mention IBM SVC, StorAge (now LSI), Incipient (now part of Texas Memory) or Troika among others you should have some DejaVu.
I guess that also begs the question of what is VPLEX, in band, out of band or hybrid fast path control path? From what I have seen it appears to be a fast path approach combined with distributed caching as opposed to a cache centric inband approaches such as IBM SVC (either on a server or as was tried on the Cisco special service blade) among others.
Likewise if you are familiar with IBM Mainframe GDPS or even EMC GDDR as well as OpenVMS Local and Metro clusters with distributed lock management you should also have DejaVu. Similarly if you had looked at or are familiar with any of the YottaYotta products or presentations, this should also be familiar as EMC acquired the assets of that now defunct company.
Is this a way for EMC to sell more hardware along with software products?
By removing barriers enabling IT staffs to support more data on more storage in a denser and more agile footprint the answer should be yes, something that we may see other vendors emulate, or, make noise about what they can or have been doing already.
How is this virtual storage spin different from the storage virtualization story?
That all depends on your view or definition as well as belief systems and preferences for what is or what is not virtual storage vs. storage virtualization. For some who believe that storage virtualization is only virtualization if and only if it involves software running on some hardware appliance or vendors storage system for aggregation and common functionality than you probably wont see this as virtual storage let alone storage virtualization. However for others, it will be confusing hence EMC introducing terms such as federation and avoiding terms including grid to minimize confusion yet play off of cloud crowd commotion.
Is VPLEX a replacement for storage system based tiering and replication?
I do not believe so and even though some vendors are making claims that tiered storage is dead, just like some vendors declared a couple of years ago that disk drives were going to be dead this year at the hands of SSD, neither has come to life so to speak pun intended. What this means for VPLEX is that it leverages underlying automated or manual tiering found in storage systems such as EMC FAST enabled or similar policy and manual functions in third party products.
What VPLEX brings to the table is the ability to transparently present a LUN or volume locally or over distance with shared access while maintaining cache and data coherency. This means that if a LUN or volume moves the applications or file system or volume managers expecting to access that storage will not be surprised, panic or encounter failover problems. Of course there will be plenty of details to be dug into and seen how it all actually works as is the case with any new technology.
Who is this for?
I see this as for environments that need flexibility and agility across multiple storage systems either from one or multiple vendors on a local or metro or wide area basis. This is for those environments that need ability to move workloads, applications and data between different storage systems and sites for maintenance, upgrades, technology refresh, BC/DR, load balancing or other IRM functions similar to how they would use virtual server migration such as VMotion or Live migration among others.
Do VPLEX and Virtual Storage eliminate need for Storage System functionality?
I see some storage virtualization solutions or appliances that have a focus of replacing underlying storage system functionality instead of coexisting or complementing. A way to test for this approach is to listen or read if the vendor or provider says anything along the lines of eliminating vendor lock in or control of the underlying storage system. That can be a sign of the golden rule of virtualization of whoever controls the virtualization functionality (at the server hypervisor or storage) controls the gold! This is why on the server side of things we are starting to see tiered hypervisors similar to tiered servers and storage where mixed hypervisors are being used for different purposes. Will we see tiered storage hypervisors or virtual storage solutions the answer could be perhaps or it depends.
Was Invista a failure not going into production and this a second attempt at virtualization?
There is a popular myth in the industry that Invista never saw the light of day outside of trade show expo or other demos however the reality is that there are actual customer deployments. Invista unlike other storage virtualization products had a different focus which was that around enabling agility and flexibility for common IRM tasks, similar the expanded focus of VPLEX. Consequently Invista has often been in apples to oranges comparison with other virtualization appliances that have as focus pooling along with other functions or in some cases serving as an appliance based storage system.
The focus around Invista and usage by those customers who have deployed it that I have talked with is around enabling agility for maintenance, facilitating upgrades, moves or reconfiguration and other common IRM tasks vs using it for pooling of storage for consolidation purposes. Thus I see VPLEX extending on the vision of Invista in a role of complimenting and leveraging underlying storage system functionality instead of trying to replace those capabilities with that of the storage virtualizer.
Is this a replacement for EMC Invista?
According to EMC the answer is no and that customers using Invista (Yes, there are customers that I have actually talked to) will continue to be supported. However I suspect that over time Invista will either become a low end entry for VPLEX, or, an entry level VPLEX solution will appear sometime in the future.
How does this stack up or compare with what others are doing?
If you are looking to compare to cache centric platforms such as IBMs SVC that adds extensive functionality and capabilities within the storage virtualization framework this is an apples to oranges comparison. VPLEX is providing cache pointers on a local and global basis functioning in a compliment to underlying storage system model where SVC caches at the specific cluster basis and enhancing functionality of underlying storage system. Rest assured there will be other apples to oranges comparisons made between these platforms.
How will this be priced?
When I asked EMC about pricing, they would not commit to a specific price prior to the announcement other than indicating that there will be options for on demand or consumption (e.g. cloud pricing) as well as pricing per engine capacity as well as subscription models (pay as you go).
What is the overhead of VPLEX?
While EMC runs various workload simulations (including benchmarks) internally as well as some publicly (e.g. Microsoft ESRP among others) they have been opposed to some storage simulation benchmarks such as SPC. The EMC opposition to simulations such as SPC have been varied however this could be a good and interesting opportunity for them to silence the industry (including myself) who continue ask them (along with a couple of other vendors including IBM and their XIV) when they will release public results.
What the interesting opportunity I think is for EMC is that they do not even have to benchmark one of their own storage systems such as a CLARiiON or VMAX, instead simply show the performance of some third party product that already is tested on the SPC website and then a submission with that product running attached to a VPLEX.
If the performance or low latency forecasts are as good as they have been described, EMC can accomplish a couple of things by:
- Demonstrating the low latency and minimal to no overhead of VPLEX
- Show VPLEX with a third party product comparing latency before and after
- Provide a comparison to other virtualization platforms including IBM SVC
As for EMC submitting a VMAX or CLARiiON SPC test in general, Im not going to hold my breath for that, instead, will continue to look at the other public workload tests such as ESRP.
Additional related reading material and links:
Resilient Storage Networks: Designing Flexible Scalable Data Infrastructures (Elsevier)
Chapter 3: Networking Your Storage
Chapter 4: Storage and IO Networking
Chapter 6: Metropolitan and Wide Area Storage Networking
Chapter 11: Storage Management
Chapter 16: Metropolitan and Wide Area Examples
The Green and Virtual Data Center (CRC)
Chapter 3: (see also here) What Defines a Next-Generation and Virtual Data Center
Chapter 4: IT Infrastructure Resource Management (IRM)
Chapter 5: Measurement, Metrics, and Management of IT Resources
Chapter 7: Server: Physical, Virtual, and Software
Chapter 9: Networking with your Servers and Storage
Also see these:
Virtual Storage and Social Media: What did EMC not Announce?
Server and Storage Virtualization – Life beyond Consolidation
Should Everything Be Virtualized?
Was today the proverbial day that he!! Froze over?
Moving Beyond the Benchmark Brouhaha
Closing comments (For now):
As with any new vision, initiative, architecture and initial product there will be plenty of questions to ask, items to investigate, early adopter customers or users to talk with and determine what is real, what is future, what is usable and practical along with what is nice to have. Likewise there will be plenty of mud ball throwing and slinging between competitors, fans and foes which for those who enjoy watching or reading those you should be well entertained.
In general, the EMC vision and story builds on and presumably delivers on past industry hype, buzz and vision with solutions that can be put into environments as productivity tool that works for the customer, instead of the customer working for the tool.
Remember the golden rule of virtualization which is in play here is that whoever controls the virtualization or associated management controls the gold. Likewise keep in mind that aggregation can cause aggravation. So do not be scared, however look before you leap meaning do your homework and due diligence with appropriate levels of expectations, aligning applicable technology to the task at hand.
Also, if you have seen or experienced something in the past, you are more likely to have DejaVu as opposed to seeing things as revolutionary. However it is also important to leverage lessons learned for future success. YottaYotta was a lot of NaddaNadda, lets see if EMC can leverage their past experiences to make this a LottaLotta.
Ok, nuff said.
Cheers gs
Greg Schulz – Author Cloud and Virtual Data Storage Networking (CRC Press), The Green and Virtual Data Center (CRC Press) and Resilient Storage Networks (Elsevier)
twitter @storageio
All Comments, (C) and (TM) belong to their owners/posters, Other content (C) Copyright 2006-2026 Server StorageIO and UnlimitedIO LLC All Rights Reserved



















{kind=link}