Cloud and Object storage are in your future, what are some questions?
IMHO there is no doubt that cloud and object storage are in your future, what are some questions?
Granted, what type of cloud and object storage or service along with for work or entertainment are some questions.
Likewise, what are your cloud and object storage concerns (assuming you already have heard the benefits)?
Some other questions include when, where for different applications workload needs, as well as how and with what among others.
Keep in mind that there are many aspects to cloud storage and they are not all object, likewise, there are many facets to object storage.
Recently I did a piece over at InfoStor titled Cloud Storage Concerns, Considerations and Trends that looks at the above among other items including:
Is cloud storage cheaper than traditional storage?
How do you access cloud object storage from legacy block and file applications?
How do you implement on-site cloud storage?
Is enterprise file sync and share (EFSS) safe and secure?
Does cloud storage need to be backed up and protected?
What geographic location requirements or regulations apply to you?
When it comes to cloud computing and, in particular, cloud storage, context matters. Conversations are necessary to discuss concerns, as well as discuss various considerations, options and alternatives. People often ask me questions about the best cloud storage to use, concerns about privacy, security, performance and cost.
Some of the most common cloud conversations topics involve context :
Public, private or hybrid cloud; turnkey subscription service or do it yourself (DIY)?
Storage, compute server, networking, applications or development tools?
Storage application such as file sync and share like Dropbox?
Storage resources such as table, queues, objects, file or block?
Storage for applications in the cloud, on-site or hybrid?
Continue reading Cloud Storage Concerns, Considerations and Trends over at InfoStor.
InfoStor – Cloud Storage Concerns, Considerations and Trends
What This All Means
As I mentioned above, cloud and object storage are in your future, granted your future may not rely on just cloud or object storage. Take a few minutes to check out some of the conversation topics, tips and trends in my piece over at InfoStor Cloud Storage Concerns, Considerations and Trends along with more material at www.objectstoragecenter.com.
Btw, what are your questions, comments, concerns, claims or caveats as part of cloud and object storage conversations?
All Comments, (C) and (TM) belong to their owners/posters, Other content (C) Copyright 2006-2023 Server StorageIO(R) and UnlimitedIO All Rights Reserved
Cloud Conversations: AWS S3 Cross Region Replication storage enhancements
Amazon Web Services (AWS) recently among other enhancements announced new Simple Storage Service (S3) cross-region replication of objects from a bucket (e.g. container) in one region to a bucket in another region. AWS also recently enhanced Elastic Block Storage (EBS) increasing maximum performance and size of Provisioned IOPS (SSD) and General Purpose (SSD) volumes. EBS enhancements included ability to store up to 16 TBytes of data in a single volume and do 20,000 input/output operations per second (IOPS). Read more about EBS and other recent AWS server, storage I/O and application enhancements here.
The Problem, Issue, Challenge, Opportunity and Need
The challenge is being able to move data (e.g. objects) stored in AWS buckets in one region to another in a safe, secure, timely, automated, cost-effective way.
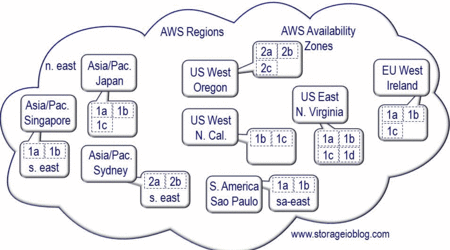
Even though AWS has a global name-space, buckets and their objects (e.g. files, data, videos, images, bit and byte streams) are stored in a specific region designated by the customer or user (AWS S3, EBS, EC2, Glacier, Regions and Availability Zone primer can be found here).
Understanding the challenge and designing a strategy
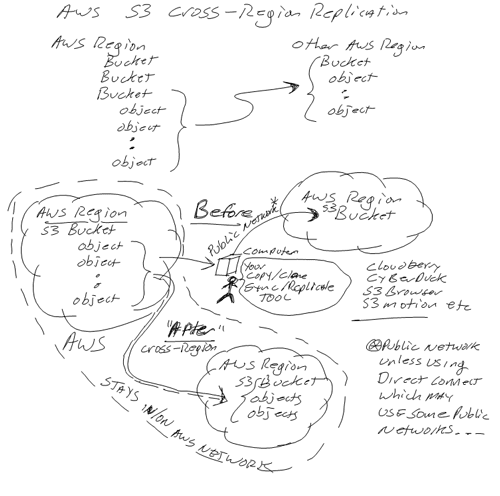
The following diagram shows the challenge and how to copy or replicate objects in an S3 bucket in one region to a destination bucket in a different region. While objects can be copied or replicated without S3 cross-region replication, that involves essentially reading your objects pulling that data out via the internet and then writing to another place. The catch is that this can add extra costs, take time, consume network bandwidth and need extra tools (Cloudberry, Cyberduck, S3fuse, S3motion, S3browser, S3 tools (not AWS) and a long list of others).
What is AWS S3 Cross-region replication
Highlights of AWS S3 Cross-region replication include:
AWS S3 Cross region replication is as its name implies, replication of S3 objects from a bucket in one region to a destination bucket in another region.
S3 replication of new objects added to an existing or new bucket (note new objects get replicated)
Policy based replication tied into S3 versioning and life-cycle rules
Quick and easy to set up for use in a matter of minutes via S3 dashboard or other interfaces
Keeps region to region data replication and movement within AWS networks (potential cost advantage)
To activate, you simply enable versioning on a bucket, enable cross-region replication, indicate source bucket (or prefix of objects in bucket), specify destination region and target bucket name (or create one), then create or select an IAM (Identify Access Management) role and objects should be replicated.
Some AWS S3 cross-region replication things to keep in mind (e.g. considerations):
As with other forms of mirroring and replication if you add something on one side it gets replicated to other side
As with other forms of mirroring and replication if you deleted something from the other side it can be deleted on both (be careful and do some testing)
Keep costs in perspective as you still need to pay for your S3 storage at both locations as well as applicable internal data transfer and GET fees
Click here to see current AWS S3 fees for various regions
S3 Cross-region replication and alternative approaches
There are several regions around the world and up until today AWS customers could copy, sync or replicate S3 bucket contents between AWS regions manually (or via automation) using various tools such as Cloudberry, Cyberduck, S3browser and S3motion to name just a few as well as via various gateways and other technologies. Some of those tools and technologies are open-source or free, some are freemium and some are premium for a few that also vary by interface (some with GUI, others with CLI or APIs) including ability to mount an S3 bucket as a local network drive and use tools to sync or copy.
However a catch with the above mentioned tools (among others) and approaches is that to replicate your data (e.g. objects in a bucket) can involve other AWS S3 fees. For example reading data (e.g. a GET which has a fee) from one AWS region and then copying out to the internet has fees. Likewise when copying data into another AWS S3 region (e.g. a PUT which are free) there is also the cost of storage at the destination.
AWS S3 cross-region hands on experience (first look)
For my first hands on (first look) experience with AWS cross-region replication today I enabled a bucket in the US Standard region (e.g. Northern Virginia) and created a new target destination bucket in the EU Ireland. Setup and configuration was very quick, literally just a few minutes with most of the time spent reading the text on the new AWS S3 dashboard properties configuration displays.
I selected an existing test bucket to replicate and noticed that nothing had replicated over to the other bucket until I realized that new objects would be replicated. Once some new objects were added to the source bucket within a matter of moments (e.g. few minutes) they appeared across the pond in my EU Ireland bucket. When I deleted those replicated objects from my EU Ireland bucket and switched back to my view of the source bucket in the US, those new objects were already deleted from the source. Yes, just like regular mirroring or replication, pay attention to how you have things configured (e.g. synchronized vs. contribute vs. echo of changes etc.).
While I was not able to do a solid quantifiable performance test, simply based on some quick copies and my network speed moving via S3 cross-region replication was faster than using something like s3motion with my server in the middle.
It also appears from some initial testing today that a benefit of AWS S3 cross-region replication (besides being bundled and part of AWS) is that some fees to pull data out of AWS and transfer out via the internet can be avoided.
Where to learn more
Here are some links to learn more about AWS S3 and related topics
How do primary storage clouds and cloud for backup differ?
What’s most important to know about my cloud privacy policy?
What this all means and wrap-up
For those who are looking for a way to streamline replicating data (e.g. objects) from an AWS bucket in one region with a bucket in a different region you now have a new option. There are potential cost savings if that is your goal along with performance benefits in addition to using what ever might be working in your environment. Replicating objects provides a way of expanding your business continuance (BC), business resiliency (BR) and disaster recovery (DR) involving S3 across regions as well as a means for content cache or distribution among other possible uses.
Overall, I like this ability for moving S3 objects within AWS, however I will continue to use other tools such as S3motion and s3sfs for moving data in and out of AWS as well as among other public cloud serves and local resources.
All Comments, (C) and (TM) belong to their owners/posters, Other content (C) Copyright 2006-2026 Server StorageIO and UnlimitedIO LLC All Rights Reserved
Cloud Bulk Big Data Software Defined Object Storage Resources
Welcome to the Cloud, Big Data, Software Defined, Bulk and Object Storage Resources Center Page objectstoragecenter.com.
This object storage resources, along with software defined, cloud, bulk, and scale-out storage page is part of the server StorageIOblog microsite collection of resources. Software-defined, Bulk, Cloud and Object Storage exist to support expanding and diverse application data demands.
Bulk, Cloud, Object Storage Solutions and Services
There are various types of cloud, bulk, and object storage including public services such as Amazon Web Services (AWS) Simple Storage Service (S3), Backblaze, Google, Microsoft Azure, IBM Softlayer, Rackspace among many others. There are also solutions for hybrid and private deployment from Cisco, Cloudian, CTERA, Cray, DDN, Dell EMC, Elastifile, Fujitsu, Vantera/HDS, HPE, Hedvig, Huawei, IBM, NetApp, Noobaa, OpenIO, OpenStack, Quantum, Rackspace, Rozo, Scality, Spectra, Storpool, StorageCraft, Suse, Swift, Virtuozzo, WekaIO, WD, among many others.
Cloud products and services among others, along with associated data infrastructures including object storage, file systems, repositories and access methods are at the center of bulk, big data, big bandwidth and little data initiatives on a public, private, hybrid and community basis. After all, not everything is the same in cloud, virtual and traditional data centers or information factories from active data to in-active deep digital archiving.
Object Context Matters
Before discussing Object Storage lets take a step back and look at some context that can clarify some confusion around the term object. The word object has many different meanings and context, both inside of the IT world as well as outside. Context matters with the term object such as a verb being a thing that can be seen or touched as well as a person or thing of action or feeling directed towards.
Besides a person, place or physical thing, an object can be a software-defined data structure that describes something. For example, a database record describing somebody’s contact or banking information, or a file descriptor with name, index ID, date and time stamps, permissions and access control lists along with other attributes or metadata. Another example is an object or blob stored in a cloud or object storage system repository, as well as an item in a hypervisor, operating system, container image or other application.
Besides being a verb, an object can also be a noun such as disapproval or disagreement with something or someone. From an IT context perspective, an object can also refer to a programming method (e.g. object-oriented programming [oop], or Java [among other environments] objects and classes) and systems development in addition to describing entities with data structures.
In other words, a data structure describes an object that can be a simple variable, constant, complex descriptor of something being processed by a program, as well as a function or unit of work. There are also objects unique or with context to specific environments besides Java or databases, operating systems, hypervisors, file systems, cloud and other things.
The Need For Bulk, Cloud and Object Storage
There is no such thing as an information recession with more data being generated, moved, processed, stored, preserved and served, granted there are economic realities. Likewise as a society our dependence on information being available for work or entertainment, from medical healthcare to social media and all points in between continues to increase (check out the Human Face of Big Data).
Object and cloud storage are in your future, the questions are when, where, with what and how among others.
Watch for more content and links to be added here soon to this object storage center page including posts, presentations, pod casts, polls, perspectives along with services and product solutions profiles.
All Comments, (C) and (TM) belong to their owners/posters, Other content (C) Copyright 2006-2026 Server StorageIO and UnlimitedIO. All Rights Reserved. StorageIO is a registered Trade Mark (TM) of Server StorageIO.